 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvasionBench: Detecting Evasive Answers in Financial Q&A via Multi-Model Consensus and LLM-as-Judge
Jan 14, 2026Detecting evasive answers in earnings calls is critical for financial transparency, yet progress is hindered by the lack of large-scale benchmarks. We introduce EvasionBench, comprising 30,000 training samples and 1,000 human-annotated test samples (Cohen's Kappa 0.835) across three evasion levels. Our key contribution is a multi-model annotation framework leveraging a core insight: disagreement between frontier LLMs signals hard examples most valuable for training. We mine boundary cases where two strong annotators conflict, using a judge to resolve labels. This approach outperforms single-model distillation by 2.4 percent, with judge-resolved samples improving generalization despite higher training loss (0.421 vs 0.393) - evidence that disagreement mining acts as implicit regularization. Our trained model Eva-4B (4B parameters) achieves 81.3 percent accuracy, outperforming its base by 25 percentage points and approaching frontier LLM performance at a fraction of inference cost.
Spatial-Temporal Feedback Diffusion Guidance for Controlled Traffic Imputation
Jan 08, 2026Imputing missing values in spatial-temporal traffic data is essential for intelligent transportation systems. Among advanced imputation methods, score-based diffusion models have demonstrated competitive performance. These models generate data by reversing a noising process, using observed values as conditional guidance. However, existing diffusion models typically apply a uniform guidance scale across both spatial and temporal dimensions, which is inadequate for nodes with high missing data rates. Sparse observations provide insufficient conditional guidance, causing the generative process to drift toward the learned prior distribution rather than closely following the conditional observations, resulting in suboptimal imputation performance. To address this, we propose FENCE, a spatial-temporal feedback diffusion guidance method designed to adaptively control guidance scales during imputation. First, FENCE introduces a dynamic feedback mechanism that adjusts the guidance scale based on the posterior likelihood approximations. The guidance scale is increased when generated values diverge from observations and reduced when alignment improves, preventing overcorrection. Second, because alignment to observations varies across nodes and denoising steps, a global guidance scale for all nodes is suboptimal. FENCE computes guidance scales at the cluster level by grouping nodes based on their attention scores, leveraging spatial-temporal correlations to provide more accurate guidance. Experimental results on real-world traffic datasets show that FENCE significantly enhances imputation accuracy.
RIPCN: A Road Impedance Principal Component Network for Probabilistic Traffic Flow Forecasting
Dec 25, 2025Accurate traffic flow forecasting is crucial for intelligent transportation services such as navigation and ride-hailing. In such applications, uncertainty estimation in forecasting is important because it helps evaluate traffic risk levels, assess forecast reliability, and provide timely warnings. As a result, probabilistic traffic flow forecasting (PTFF) has gained significant attention, as it produces both point forecasts and uncertainty estimates. However, existing PTFF approaches still face two key challenges: (1) how to uncover and model the causes of traffic flow uncertainty for reliable forecasting, and (2) how to capture the spatiotemporal correlations of uncertainty for accurate prediction. To address these challenges, we propose RIPCN, a Road Impedance Principal Component Network that integrates domain-specific transportation theory with spatiotemporal principal component learning for PTFF. RIPCN introduces a dynamic impedance evolution network that captures directional traffic transfer patterns driven by road congestion level and flow variability, revealing the direct causes of uncertainty and enhancing both reliability and interpretability. In addition, a principal component network is designed to forecast the dominant eigenvectors of future flow covariance, enabling the model to capture spatiotemporal uncertainty correlations. This design allows for accurate and efficient uncertainty estimation while also improving point prediction performance. Experimental results on real-world datasets show that our approach outperforms existing probabilistic forecasting methods.
DramaBench: A Six-Dimensional Evaluation Framework for Drama Script Continuation
Dec 23, 2025Drama script continuation requires models to maintain character consistency, advance plot coherently, and preserve dramatic structurecapabilities that existing benchmarks fail to evaluate comprehensively. We present DramaBench, the first large-scale benchmark for evaluating drama script continuation across six independent dimensions: Format Standards, Narrative Efficiency, Character Consistency, Emotional Depth, Logic Consistency, and Conflict Handling. Our framework combines rulebased analysis with LLM-based labeling and statistical metrics, ensuring objective and reproducible evaluation. We conduct comprehensive evaluation of 8 state-of-the-art language models on 1,103 scripts (8,824 evaluations total), with rigorous statistical significance testing (252 pairwise comparisons, 65.9% significant) and human validation (188 scripts, substantial agreement on 3/5 dimensions). Our ablation studies confirm all six dimensions capture independent quality aspects (mean | r | = 0.020). DramaBench provides actionable, dimensionspecific feedback for model improvement and establishes a rigorous standard for creative writing evaluation.
SculptDrug : A Spatial Condition-Aware Bayesian Flow Model for Structure-based Drug Design
Nov 16, 2025Structure-Based drug design (SBDD) has emerged as a popular approach in drug discovery, leveraging three-dimensional protein structures to generate drug ligands. However, existing generative models encounter several key challenges: (1) incorporating boundary condition constraints, (2) integrating hierarchical structural conditions, and (3) ensuring spatial modeling fidelity. To address these limitations, we propose SculptDrug, a spatial condition-aware generative model based on Bayesian flow networks (BFNs). First, SculptDrug follows a BFN-based framework and employs a progressive denoising strategy to ensure spatial modeling fidelity, iteratively refining atom positions while enhancing local interactions for precise spatial alignment. Second, we introduce a Boundary Awareness Block that incorporates protein surface constraints into the generative process to ensure that generated ligands are geometrically compatible with the target protein. Third, we design a Hierarchical Encoder that captures global structural context while preserving fine-grained molecular interactions, ensuring overall consistency and accurate ligand-protein conformations. We evaluate SculptDrug on the CrossDocked dataset, and experimental results demonstrate that SculptDrug outperforms state-of-the-art baselines, highlighting the effectiveness of spatial condition-aware modeling.
TransferTraj: A Vehicle Trajectory Learning Model for Region and Task Transferability
May 19, 2025Vehicle GPS trajectories provide valuable movement information that supports various downstream tasks and applications. A desirable trajectory learning model should be able to transfer across regions and tasks without retraining, avoiding the need to maintain multiple specialized models and subpar performance with limited training data. However, each region has its unique spatial features and contexts, which are reflected in vehicle movement patterns and difficult to generalize. Additionally, transferring across different tasks faces technical challenges due to the varying input-output structures required for each task. Existing efforts towards transferability primarily involve learning embedding vectors for trajectories, which perform poorly in region transfer and require retraining of prediction modules for task transfer. To address these challenges, we propose TransferTraj, a vehicle GPS trajectory learning model that excels in both region and task transferability. For region transferability, we introduce RTTE as the main learnable module within TransferTraj. It integrates spatial, temporal, POI, and road network modalities of trajectories to effectively manage variations in spatial context distribution across regions. It also introduces a TRIE module for incorporating relative information of spatial features and a spatial context MoE module for handling movement patterns in diverse contexts. For task transferability, we propose a task-transferable input-output scheme that unifies the input-output structure of different tasks into the masking and recovery of modalities and trajectory points. This approach allows TransferTraj to be pre-trained once and transferred to different tasks without retraining. Extensive experiments on three real-world vehicle trajectory datasets under task transfer, zero-shot, and few-shot region transfer, validating TransferTraj's effectiveness.
Log Optimization Simplification Method for Predicting Remaining Time
Mar 10, 2025Information systems generate a large volume of event log data during business operations, much of which consists of low-value and redundant information. When performance predictions are made directly from these logs, the accuracy of the predictions can be compromised. Researchers have explored methods to simplify and compress these data while preserving their valuable components. Most existing approaches focus on reducing the dimensionality of the data by eliminating redundant and irrelevant features. However, there has been limited investigation into the efficiency of execution both before and after event log simplification. In this paper, we present a prediction point selection algorithm designed to avoid the simplification of all points that function similarly. We select sequences or self-loop structures to form a simplifiable segment, and we optimize the deviation between the actual simplifiable value and the original data prediction value to prevent over-simplification. Experiments indicate that the simplified event log retains its predictive performance and, in some cases, enhances its predictive accuracy compared to the original event log.
DUET: Dual Clustering Enhanced Multivariate Time Series Forecasting
Dec 14, 2024
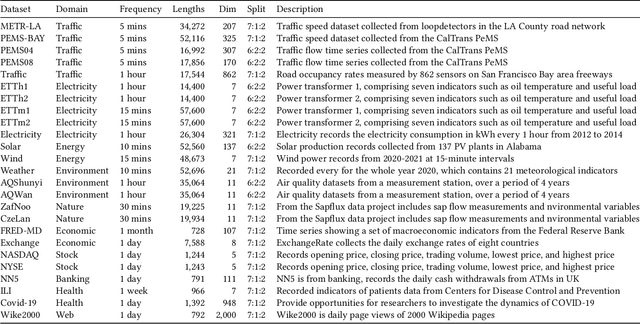


Multivariate time series forecasting is crucial for various applications, such as financial investment, energy management, weather forecasting, and traffic optimization. However, accurate forecasting is challenging due to two main factors. First, real-world time series often show heterogeneous temporal patterns caused by distribution shifts over time. Second, correlations among channels are complex and intertwined, making it hard to model the interactions among channels precisely and flexibly. In this study, we address these challenges by proposing a general framework called \textbf{DUET}, which introduces \underline{DU}al clustering on the temporal and channel dimensions to \underline{E}nhance multivariate \underline{T}ime series forecasting. First, we design a Temporal Clustering Module (TCM) that clusters time series into fine-grained distributions to handle heterogeneous temporal patterns. For different distribution clusters, we design various pattern extractors to capture their intrinsic temporal patterns, thus modeling the heterogeneity. Second, we introduce a novel Channel-Soft-Clustering strategy and design a Channel Clustering Module (CCM), which captures the relationships among channels in the frequency domain through metric learning and applies sparsification to mitigate the adverse effects of noisy channels. Finally, DUET combines TCM and CCM to incorporate both the temporal and channel dimensions. Extensive experiments on 25 real-world datasets from 10 application domains, demonstrate the state-of-the-art performance of DUET.
An Experimental Evaluation of Imputation Models for Spatial-Temporal Traffic Data
Dec 06, 2024



Traffic data imputation is a critical preprocessing step in intelligent transportation systems, enabling advanced transportation services. Despite significant advancements in this field, selecting the most suitable model for practical applications remains challenging due to three key issues: 1) incomprehensive consideration of missing patterns that describe how data loss along spatial and temporal dimensions, 2) the lack of test on standardized datasets, and 3) insufficient evaluations. To this end, we first propose practice-oriented taxonomies for missing patterns and imputation models, systematically identifying all possible forms of real-world traffic data loss and analyzing the characteristics of existing models. Furthermore, we introduce a unified benchmarking pipeline to comprehensively evaluate 10 representative models across various missing patterns and rates. This work aims to provide a holistic understanding of traffic data imputation research and serve as a practical guideline.
Mobility-LLM: Learning Visiting Intentions and Travel Preferences from Human Mobility Data with Large Language Models
Oct 29, 2024



Location-based services (LBS) have accumulated extensive human mobility data on diverse behaviors through check-in sequences. These sequences offer valuable insights into users' intentions and preferences. Yet, existing models analyzing check-in sequences fail to consider the semantics contained in these sequences, which closely reflect human visiting intentions and travel preferences, leading to an incomplete comprehension. Drawing inspiration from the exceptional semantic understanding and contextual information processing capabilities of large language models (LLMs) across various domains, we present Mobility-LLM, a novel framework that leverages LLMs to analyze check-in sequences for multiple tasks. Since LLMs cannot directly interpret check-ins, we reprogram these sequences to help LLMs comprehensively understand the semantics of human visiting intentions and travel preferences. Specifically, we introduce a visiting intention memory network (VIMN) to capture the visiting intentions at each record, along with a shared pool of human travel preference prompts (HTPP) to guide the LLM in understanding users' travel preferences. These components enhance the model's ability to extract and leverage semantic information from human mobility data effectively. Extensive experiments on four benchmark datasets and three downstream tasks demonstrate that our approach significantly outperforms existing models, underscoring the effectiveness of Mobility-LLM in advancing our understanding of human mobility data within LBS contexts.