 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Invariant Representations to Invariant Data: Provable Robustness to Spurious Correlations via Noisy Counterfactual Matching
May 30, 2025Spurious correlations can cause model performance to degrade in new environments. Prior causality-inspired works aim to learn invariant representations (e.g., IRM) but typically underperform empirical risk minimization (ERM). Recent alternatives improve robustness by leveraging test-time data, but such data may be unavailable in practice. To address these issues, we take a data-centric approach by leveraging invariant data pairs, pairs of samples that would have the same prediction with the optimally robust classifier. We prove that certain counterfactual pairs will naturally satisfy this invariance property and introduce noisy counterfactual matching (NCM), a simple constraint-based method for leveraging invariant pairs for enhanced robustness, even with a small set of noisy pairs-in the ideal case, each pair can eliminate one spurious feature. For linear causal models, we prove that the test domain error can be upper bounded by the in-domain error and a term that depends on the counterfactuals' diversity and quality. We validate on a synthetic dataset and demonstrate on real-world benchmarks that linear probing on a pretrained backbone improves robustness.
TransferTraj: A Vehicle Trajectory Learning Model for Region and Task Transferability
May 19, 2025Vehicle GPS trajectories provide valuable movement information that supports various downstream tasks and applications. A desirable trajectory learning model should be able to transfer across regions and tasks without retraining, avoiding the need to maintain multiple specialized models and subpar performance with limited training data. However, each region has its unique spatial features and contexts, which are reflected in vehicle movement patterns and difficult to generalize. Additionally, transferring across different tasks faces technical challenges due to the varying input-output structures required for each task. Existing efforts towards transferability primarily involve learning embedding vectors for trajectories, which perform poorly in region transfer and require retraining of prediction modules for task transfer. To address these challenges, we propose TransferTraj, a vehicle GPS trajectory learning model that excels in both region and task transferability. For region transferability, we introduce RTTE as the main learnable module within TransferTraj. It integrates spatial, temporal, POI, and road network modalities of trajectories to effectively manage variations in spatial context distribution across regions. It also introduces a TRIE module for incorporating relative information of spatial features and a spatial context MoE module for handling movement patterns in diverse contexts. For task transferability, we propose a task-transferable input-output scheme that unifies the input-output structure of different tasks into the masking and recovery of modalities and trajectory points. This approach allows TransferTraj to be pre-trained once and transferred to different tasks without retraining. Extensive experiments on three real-world vehicle trajectory datasets under task transfer, zero-shot, and few-shot region transfer, validating TransferTraj's effectiveness.
Counterfactual Fairness by Combining Factual and Counterfactual Predictions
Sep 03, 2024



In high-stake domains such as healthcare and hiring, the role of machine learning (ML) in decision-making raises significant fairness concerns. This work focuses on Counterfactual Fairness (CF), which posits that an ML model's outcome on any individual should remain unchanged if they had belonged to a different demographic group. Previous works have proposed methods that guarantee CF. Notwithstanding, their effects on the model's predictive performance remains largely unclear. To fill in this gap, we provide a theoretical study on the inherent trade-off between CF and predictive performance in a model-agnostic manner. We first propose a simple but effective method to cast an optimal but potentially unfair predictor into a fair one without losing the optimality. By analyzing its excess risk in order to achieve CF, we quantify this inherent trade-off. Further analysis on our method's performance with access to only incomplete causal knowledge is also conducted. Built upon it, we propose a performant algorithm that can be applied in such scenarios. Experiments on both synthetic and semi-synthetic datasets demonstrate the validity of our analysis and methods.
PTrajM: Efficient and Semantic-rich Trajectory Learning with Pretrained Trajectory-Mamba
Aug 09, 2024



Vehicle trajectories provide crucial movement information for various real-world applications. To better utilize vehicle trajectories, it is essential to develop a trajectory learning approach that can effectively and efficiently extract rich semantic information, including movement behavior and travel purposes, to support accurate downstream applications. However, creating such an approach presents two significant challenges. First, movement behavior are inherently spatio-temporally continuous, making them difficult to extract efficiently from irregular and discrete trajectory points. Second, travel purposes are related to the functionalities of areas and road segments traversed by vehicles. These functionalities are not available from the raw spatio-temporal trajectory features and are hard to extract directly from complex textual features associated with these areas and road segments. To address these challenges, we propose PTrajM, a novel method capable of efficient and semantic-rich vehicle trajectory learning. To support efficient modeling of movement behavior, we introduce Trajectory-Mamba as the learnable model of PTrajM, which effectively extracts continuous movement behavior while being more computationally efficient than existing structures. To facilitate efficient extraction of travel purposes, we propose a travel purpose-aware pre-training procedure, which enables PTrajM to discern the travel purposes of trajectories without additional computational resources during its embedding process. Extensive experiments on two real-world datasets and comparisons with several state-of-the-art trajectory learning methods demonstrate the effectiveness of PTrajM. Code is available at https://anonymous.4open.science/r/PTrajM-C973.
Spatial-Temporal Cross-View Contrastive Pre-training for Check-in Sequence Representation Learning
Jul 25, 2024



The rapid growth of location-based services (LBS) has yielded massive amounts of data on human mobility. Effectively extracting meaningful representations for user-generated check-in sequences is pivotal for facilitating various downstream services. However, the user-generated check-in data are simultaneously influenced by the surrounding objective circumstances and the user's subjective intention. Specifically, the temporal uncertainty and spatial diversity exhibited in check-in data make it difficult to capture the macroscopic spatial-temporal patterns of users and to understand the semantics of user mobility activities. Furthermore, the distinct characteristics of the temporal and spatial information in check-in sequences call for an effective fusion method to incorporate these two types of information. In this paper, we propose a novel Spatial-Temporal Cross-view Contrastive Representation (STCCR) framework for check-in sequence representation learning. Specifically, STCCR addresses the above challenges by employing self-supervision from "spatial topic" and "temporal intention" views, facilitating effective fusion of spatial and temporal information at the semantic level. Besides, STCCR leverages contrastive clustering to uncover users' shared spatial topics from diverse mobility activities, while employing angular momentum contrast to mitigate the impact of temporal uncertainty and noise. We extensively evaluate STCCR on three real-world datasets and demonstrate its superior performance across three downstream tasks.
UniTE: A Survey and Unified Pipeline for Pre-training ST Trajectory Embeddings
Jul 17, 2024



Spatio-temporal (ST) trajectories are sequences of timestamped locations, which enable a variety of analyses that in turn enable important real-world applications. It is common to map trajectories to vectors, called embeddings, before subsequent analyses. Thus, the qualities of embeddings are very important. Methods for pre-training embeddings, which leverage unlabeled trajectories for training universal embeddings, have shown promising applicability across different tasks, thus attracting considerable interest. However, research progress on this topic faces two key challenges: a lack of a comprehensive overview of existing methods, resulting in several related methods not being well-recognized, and the absence of a unified pipeline, complicating the development new methods and the analysis of methods. To overcome these obstacles and advance the field of pre-training of trajectory embeddings, we present UniTE, a survey and a unified pipeline for this domain. In doing so, we present a comprehensive list of existing methods for pre-training trajectory embeddings, which includes methods that either explicitly or implicitly employ pre-training techniques. Further, we present a unified and modular pipeline with publicly available underlying code, simplifying the process of constructing and evaluating methods for pre-training trajectory embeddings. Additionally, we contribute a selection of experimental results using the proposed pipeline on real-world datasets.
PLM4Traj: Cognizing Movement Patterns and Travel Purposes from Trajectories with Pre-trained Language Models
May 21, 2024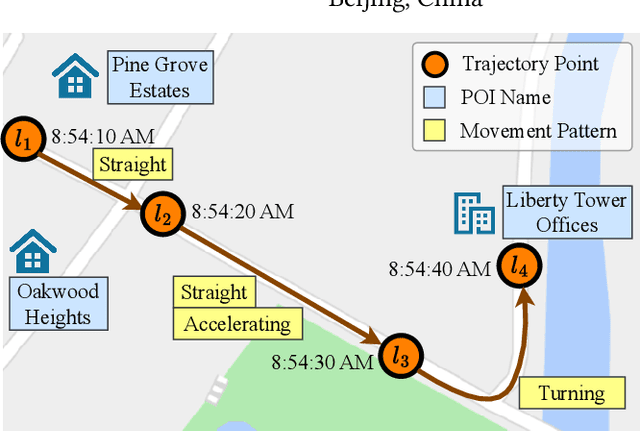
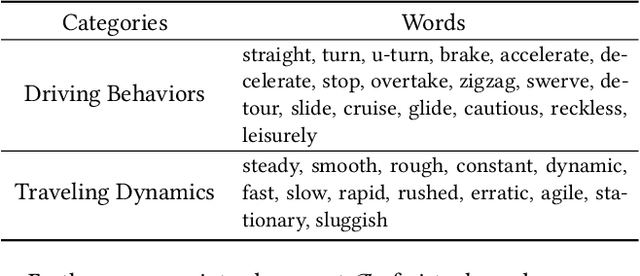
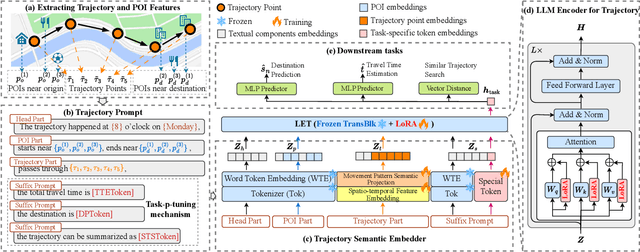
Spatio-temporal trajectories play a vital role in various spatio-temporal data mining tasks. Developing a versatile trajectory learning approach that can adapt to different tasks while ensuring high accuracy is crucial. This requires effectively extracting movement patterns and travel purposes embedded in trajectories. However, this task is challenging due to limitations in the size and quality of available trajectory datasets. On the other hand, pre-trained language models (PLMs) have shown great success in adapting to different tasks by training on large-scale, high-quality corpus datasets. Given the similarities between trajectories and sentences, there is potential in leveraging PLMs to enhance the development of a versatile and effective trajectory learning method. Nevertheless, vanilla PLMs are not tailored to handle the unique spatio-temporal features present in trajectories and lack the capability to extract movement patterns and travel purposes from them. To overcome these obstacles, we propose a model called PLM4Traj that effectively utilizes PLMs to model trajectories. PLM4Traj leverages the strengths of PLMs to create a versatile trajectory learning approach while addressing the limitations of vanilla PLMs in modeling trajectories. Firstly, PLM4Traj incorporates a novel trajectory semantic embedder that enables PLMs to process spatio-temporal features in trajectories and extract movement patterns and travel purposes from them. Secondly, PLM4Traj introduces a novel trajectory prompt that integrates movement patterns and travel purposes into PLMs, while also allowing the model to adapt to various tasks. Extensive experiments conducted on two real-world datasets and two representative tasks demonstrate that PLM4Traj successfully achieves its design goals. Codes are available at https://github.com/Zeru19/PLM4Traj.
Fault-Tolerant Vertical Federated Learning on Dynamic Networks
Dec 27, 2023Vertical Federated learning (VFL) is a class of FL where each client shares the same sample space but only holds a subset of the features. While VFL tackles key privacy challenges of distributed learning, it often assumes perfect hardware and communication capabilities. This assumption hinders the broad deployment of VFL, particularly on edge devices, which are heterogeneous in their in-situ capabilities and will connect/disconnect from the network over time. To address this gap, we define Internet Learning (IL) including its data splitting and network context and which puts good performance under extreme dynamic condition of clients as the primary goal. We propose VFL as a naive baseline and develop several extensions to handle the IL paradigm of learning. Furthermore, we implement new methods, propose metrics, and extensively analyze results based on simulating a sensor network. The results show that the developed methods are more robust to changes in the network than VFL baseline.
Towards Characterizing Domain Counterfactuals For Invertible Latent Causal Models
Jun 20, 2023



Learning latent causal models from data has many important applications such as robustness, model extrapolation, and counterfactuals. Most prior theoretic work has focused on full causal discovery (i.e., recovering the true latent variables) but requires strong assumptions such as linearity or fails to have any analysis of the equivalence class of solutions (e.g., IRM). Instead of full causal discovery, we focus on a specific type of causal query called the domain counterfactual, which hypothesizes what a sample would have looked like if it had been generated in a different domain (or environment). Concretely, we assume domain-specific invertible latent structural causal models and a shared invertible observation function, both of which are less restrictive assumptions than prior theoretic works. Under these assumptions, we define domain counterfactually equivalent models and prove that any model can be transformed into an equivalent model via two invertible functions. This constructive property provides a tight characterization of the domain counterfactual equivalence classes. Building upon this result, we prove that every equivalence class contains a model where all intervened variables are at the end when topologically sorted by the causal DAG, i.e., all non-intervened variables have non-intervened ancestors. This surprising result suggests that an algorithm that only allows intervention in the last $k$ latent variables may improve model estimation for counterfactuals. In experiments, we enforce the sparse intervention hypothesis via this theoretic result by constraining that the latent SCMs can only differ in the last few causal mechanisms and demonstrate the feasibility of this algorithm in simulated and image-based experiments.
Regenerative Particle Thompson Sampling
Mar 15, 2022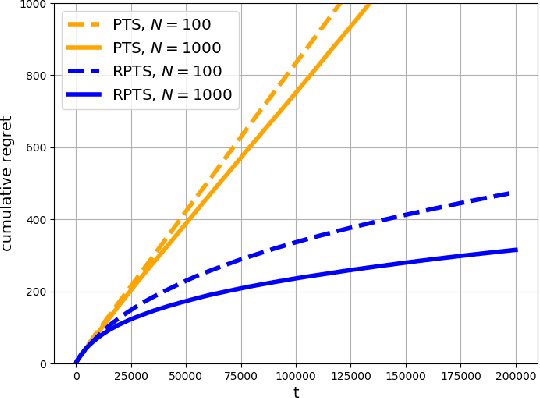
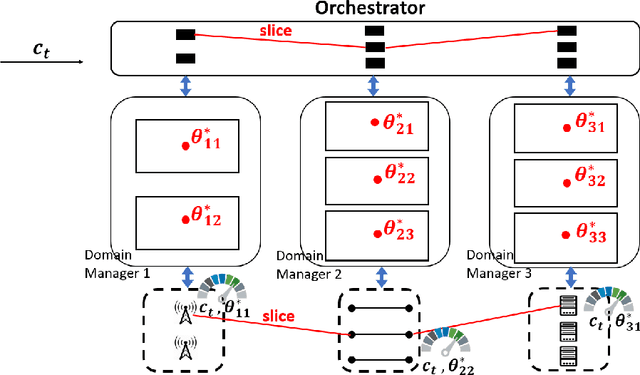
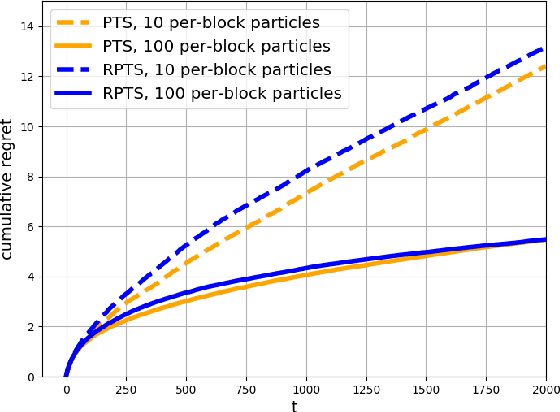
This paper proposes regenerative particle Thompson sampling (RPTS), a flexible variation of Thompson sampling. Thompson sampling itself is a Bayesian heuristic for solving stochastic bandit problems, but it is hard to implement in practice due to the intractability of maintaining a continuous posterior distribution. Particle Thompson sampling (PTS) is an approximation of Thompson sampling obtained by simply replacing the continuous distribution by a discrete distribution supported at a set of weighted static particles. We observe that in PTS, the weights of all but a few fit particles converge to zero. RPTS is based on the heuristic: delete the decaying unfit particles and regenerate new particles in the vicinity of fit surviving particles. Empirical evidence shows uniform improvement from PTS to RPTS and flexibility and efficacy of RPTS across a set of representative bandit problems, including an application to 5G network slicing.