 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegenerative Particle Thompson Sampling
Mar 15, 2022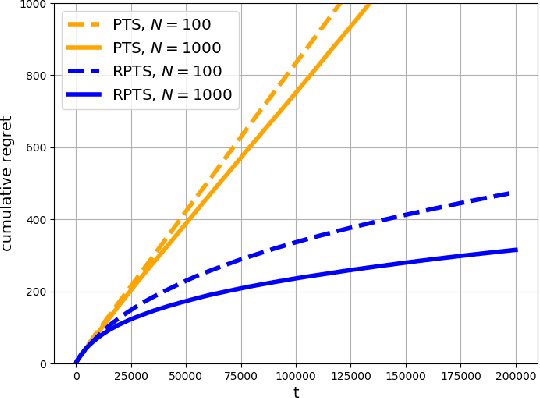
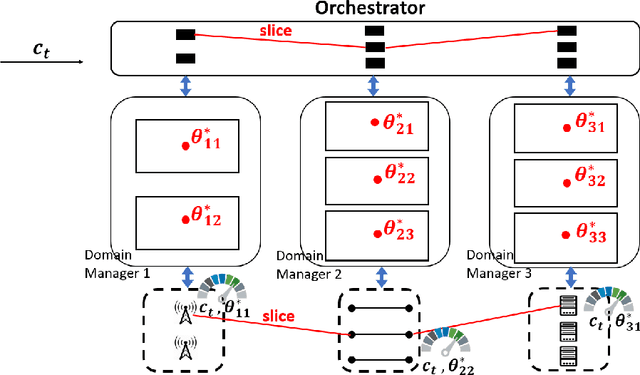
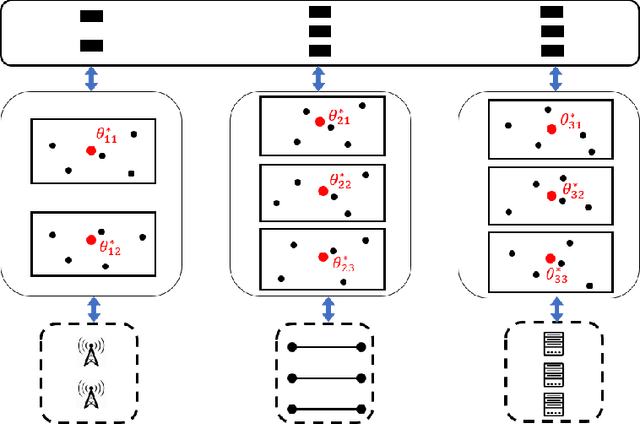
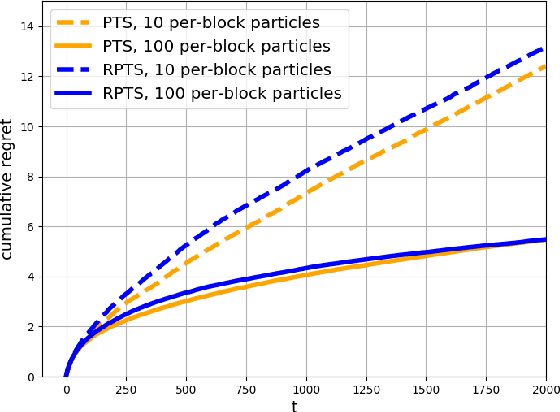
This paper proposes regenerative particle Thompson sampling (RPTS), a flexible variation of Thompson sampling. Thompson sampling itself is a Bayesian heuristic for solving stochastic bandit problems, but it is hard to implement in practice due to the intractability of maintaining a continuous posterior distribution. Particle Thompson sampling (PTS) is an approximation of Thompson sampling obtained by simply replacing the continuous distribution by a discrete distribution supported at a set of weighted static particles. We observe that in PTS, the weights of all but a few fit particles converge to zero. RPTS is based on the heuristic: delete the decaying unfit particles and regenerate new particles in the vicinity of fit surviving particles. Empirical evidence shows uniform improvement from PTS to RPTS and flexibility and efficacy of RPTS across a set of representative bandit problems, including an application to 5G network slicing.
Community Recovery in a Preferential Attachment Graph
Jul 20, 2018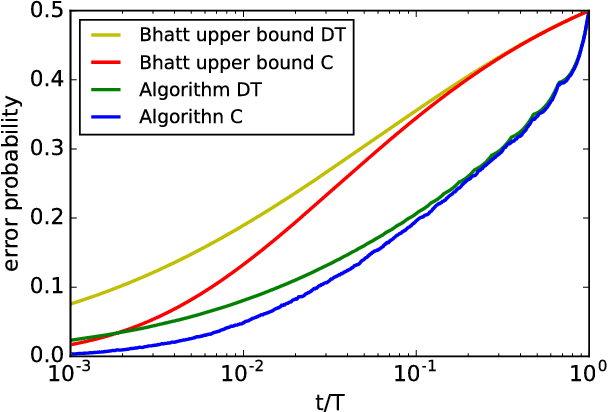
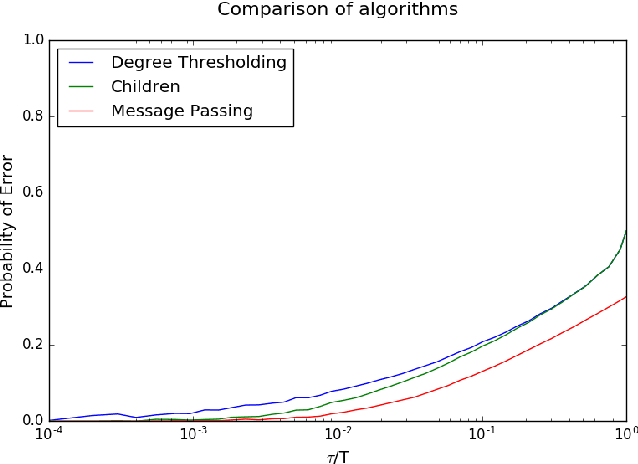
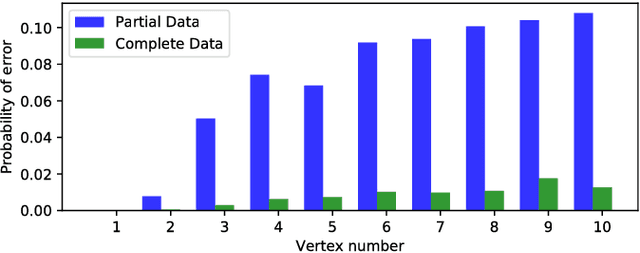
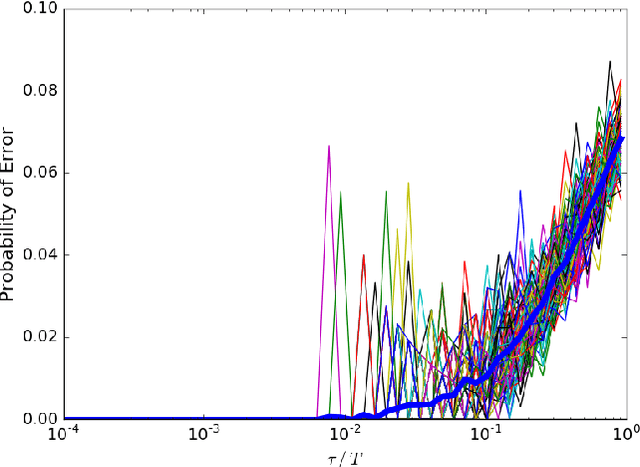
A message passing algorithm is derived for recovering communities within a graph generated by a variation of the Barab\'{a}si-Albert preferential attachment model. The estimator is assumed to know the arrival times, or order of attachment, of the vertices. The derivation of the algorithm is based on belief propagation under an independence assumption. Two precursors to the message passing algorithm are analyzed: the first is a degree thresholding (DT) algorithm and the second is an algorithm based on the arrival times of the children (C) of a given vertex, where the children of a given vertex are the vertices that attached to it. Comparison of the performance of the algorithms shows it is beneficial to know the arrival times, not just the number, of the children. The probability of correct classification of a vertex is asymptotically determined by the fraction of vertices arriving before it. Two extensions of Algorithm C are given: the first is based on joint likelihood of the children of a fixed set of vertices; it can sometimes be used to seed the message passing algorithm. The second is the message passing algorithm. Simulation results are given.
Preferential Attachment Graphs with Planted Communities
Jan 27, 2018A variation of the preferential attachment random graph model of Barab\'asi and Albert is defined that incorporates planted communities. The graph is built progressively, with new vertices attaching to the existing ones one-by-one. At every step, the incoming vertex is randomly assigned a label, which represents a community it belongs to. This vertex then chooses certain vertices as its neighbors, with the choice of each vertex being proportional to the degree of the vertex multiplied by an affinity depending on the labels of the new vertex and a potential neighbor. It is shown that the fraction of half-edges attached to vertices with a given label converges almost surely for some classes of affinity matrices. In addition, the empirical degree distribution for the set of vertices with a given label converges to a heavy tailed distribution, such that the tail decay parameter can be different for different communities. Our proof method may be of independent interest, both for the classical Barab\'asi -Albert model and for other possible extensions.
Recovering a Hidden Community Beyond the Kesten-Stigum Threshold in $O(|E| \log^*|V|)$ Time
Jan 16, 2018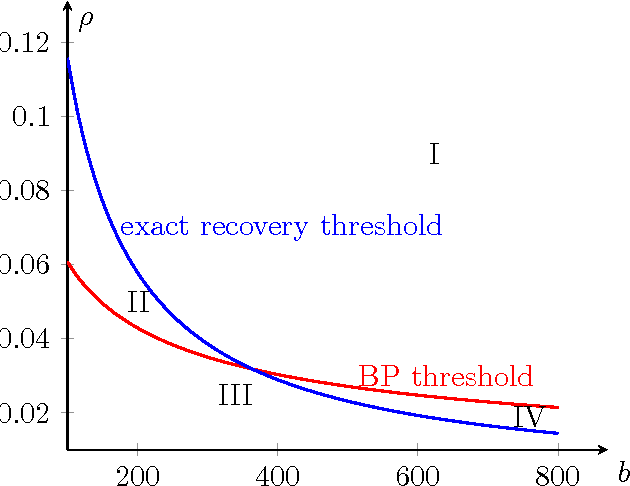
Community detection is considered for a stochastic block model graph of n vertices, with K vertices in the planted community, edge probability p for pairs of vertices both in the community, and edge probability q for other pairs of vertices. The main focus of the paper is on weak recovery of the community based on the graph G, with o(K) misclassified vertices on average, in the sublinear regime $n^{1-o(1)} \leq K \leq o(n).$ A critical parameter is the effective signal-to-noise ratio $\lambda=K^2(p-q)^2/((n-K)q)$, with $\lambda=1$ corresponding to the Kesten-Stigum threshold. We show that a belief propagation algorithm achieves weak recovery if $\lambda>1/e$, beyond the Kesten-Stigum threshold by a factor of $1/e.$ The belief propagation algorithm only needs to run for $\log^\ast n+O(1) $ iterations, with the total time complexity $O(|E| \log^*n)$, where $\log^*n$ is the iterated logarithm of $n.$ Conversely, if $\lambda \leq 1/e$, no local algorithm can asymptotically outperform trivial random guessing. Furthermore, a linear message-passing algorithm that corresponds to applying power iteration to the non-backtracking matrix of the graph is shown to attain weak recovery if and only if $\lambda>1$. In addition, the belief propagation algorithm can be combined with a linear-time voting procedure to achieve the information limit of exact recovery (correctly classify all vertices with high probability) for all $K \ge \frac{n}{\log n} \left( \rho_{\rm BP} +o(1) \right),$ where $\rho_{\rm BP}$ is a function of $p/q$.
Achieving Exact Cluster Recovery Threshold via Semidefinite Programming: Extensions
Jun 15, 2016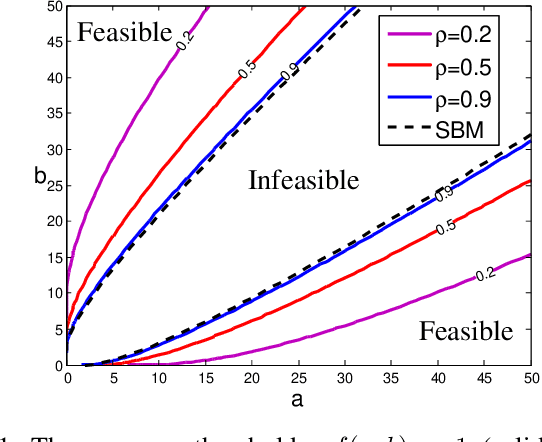
Resolving a conjecture of Abbe, Bandeira and Hall, the authors have recently shown that the semidefinite programming (SDP) relaxation of the maximum likelihood estimator achieves the sharp threshold for exactly recovering the community structure under the binary stochastic block model of two equal-sized clusters. The same was shown for the case of a single cluster and outliers. Extending the proof techniques, in this paper it is shown that SDP relaxations also achieve the sharp recovery threshold in the following cases: (1) Binary stochastic block model with two clusters of sizes proportional to network size but not necessarily equal; (2) Stochastic block model with a fixed number of equal-sized clusters; (3) Binary censored block model with the background graph being Erd\H{o}s-R\'enyi. Furthermore, a sufficient condition is given for an SDP procedure to achieve exact recovery for the general case of a fixed number of clusters plus outliers. These results demonstrate the versatility of SDP relaxation as a simple, general purpose, computationally feasible methodology for community detection.
Semidefinite Programs for Exact Recovery of a Hidden Community
Jun 03, 2016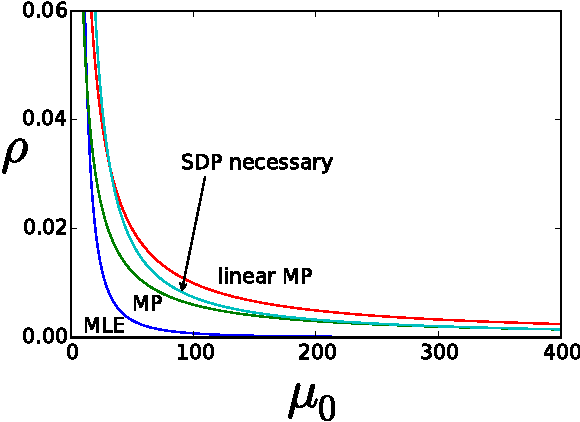
We study a semidefinite programming (SDP) relaxation of the maximum likelihood estimation for exactly recovering a hidden community of cardinality $K$ from an $n \times n$ symmetric data matrix $A$, where for distinct indices $i,j$, $A_{ij} \sim P$ if $i, j$ are both in the community and $A_{ij} \sim Q$ otherwise, for two known probability distributions $P$ and $Q$. We identify a sufficient condition and a necessary condition for the success of SDP for the general model. For both the Bernoulli case ($P={{\rm Bern}}(p)$ and $Q={{\rm Bern}}(q)$ with $p>q$) and the Gaussian case ($P=\mathcal{N}(\mu,1)$ and $Q=\mathcal{N}(0,1)$ with $\mu>0$), which correspond to the problem of planted dense subgraph recovery and submatrix localization respectively, the general results lead to the following findings: (1) If $K=\omega( n /\log n)$, SDP attains the information-theoretic recovery limits with sharp constants; (2) If $K=\Theta(n/\log n)$, SDP is order-wise optimal, but strictly suboptimal by a constant factor; (3) If $K=o(n/\log n)$ and $K \to \infty$, SDP is order-wise suboptimal. The same critical scaling for $K$ is found to hold, up to constant factors, for the performance of SDP on the stochastic block model of $n$ vertices partitioned into multiple communities of equal size $K$. A key ingredient in the proof of the necessary condition is a construction of a primal feasible solution based on random perturbation of the true cluster matrix.
Information Limits for Recovering a Hidden Community
Jan 25, 2016We study the problem of recovering a hidden community of cardinality $K$ from an $n \times n$ symmetric data matrix $A$, where for distinct indices $i,j$, $A_{ij} \sim P$ if $i, j$ both belong to the community and $A_{ij} \sim Q$ otherwise, for two known probability distributions $P$ and $Q$ depending on $n$. If $P={\rm Bern}(p)$ and $Q={\rm Bern}(q)$ with $p>q$, it reduces to the problem of finding a densely-connected $K$-subgraph planted in a large Erd\"os-R\'enyi graph; if $P=\mathcal{N}(\mu,1)$ and $Q=\mathcal{N}(0,1)$ with $\mu>0$, it corresponds to the problem of locating a $K \times K$ principal submatrix of elevated means in a large Gaussian random matrix. We focus on two types of asymptotic recovery guarantees as $n \to \infty$: (1) weak recovery: expected number of classification errors is $o(K)$; (2) exact recovery: probability of classifying all indices correctly converges to one. Under mild assumptions on $P$ and $Q$, and allowing the community size to scale sublinearly with $n$, we derive a set of sufficient conditions and a set of necessary conditions for recovery, which are asymptotically tight with sharp constants. The results hold in particular for the Gaussian case, and for the case of bounded log likelihood ratio, including the Bernoulli case whenever $\frac{p}{q}$ and $\frac{1-p}{1-q}$ are bounded away from zero and infinity. An important algorithmic implication is that, whenever exact recovery is information theoretically possible, any algorithm that provides weak recovery when the community size is concentrated near $K$ can be upgraded to achieve exact recovery in linear additional time by a simple voting procedure.
Achieving Exact Cluster Recovery Threshold via Semidefinite Programming
Jan 05, 2016The binary symmetric stochastic block model deals with a random graph of $n$ vertices partitioned into two equal-sized clusters, such that each pair of vertices is connected independently with probability $p$ within clusters and $q$ across clusters. In the asymptotic regime of $p=a \log n/n$ and $q=b \log n/n$ for fixed $a,b$ and $n \to \infty$, we show that the semidefinite programming relaxation of the maximum likelihood estimator achieves the optimal threshold for exactly recovering the partition from the graph with probability tending to one, resolving a conjecture of Abbe et al. \cite{Abbe14}. Furthermore, we show that the semidefinite programming relaxation also achieves the optimal recovery threshold in the planted dense subgraph model containing a single cluster of size proportional to $n$.
Clustering and Inference From Pairwise Comparisons
Dec 17, 2015
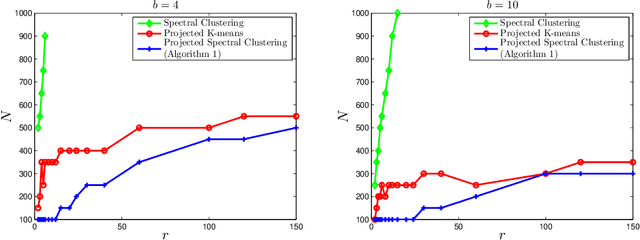
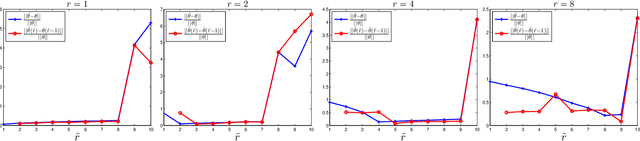
Given a set of pairwise comparisons, the classical ranking problem computes a single ranking that best represents the preferences of all users. In this paper, we study the problem of inferring individual preferences, arising in the context of making personalized recommendations. In particular, we assume that there are $n$ users of $r$ types; users of the same type provide similar pairwise comparisons for $m$ items according to the Bradley-Terry model. We propose an efficient algorithm that accurately estimates the individual preferences for almost all users, if there are $r \max \{m, n\}\log m \log^2 n$ pairwise comparisons per type, which is near optimal in sample complexity when $r$ only grows logarithmically with $m$ or $n$. Our algorithm has three steps: first, for each user, compute the \emph{net-win} vector which is a projection of its $\binom{m}{2}$-dimensional vector of pairwise comparisons onto an $m$-dimensional linear subspace; second, cluster the users based on the net-win vectors; third, estimate a single preference for each cluster separately. The net-win vectors are much less noisy than the high dimensional vectors of pairwise comparisons and clustering is more accurate after the projection as confirmed by numerical experiments. Moreover, we show that, when a cluster is only approximately correct, the maximum likelihood estimation for the Bradley-Terry model is still close to the true preference.
Submatrix localization via message passing
Oct 30, 2015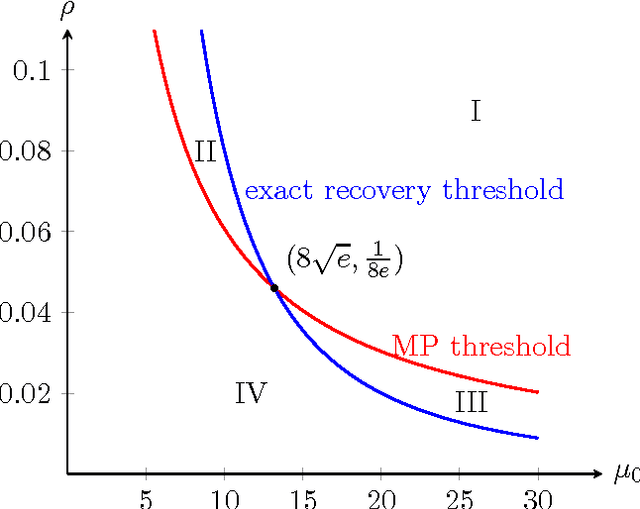
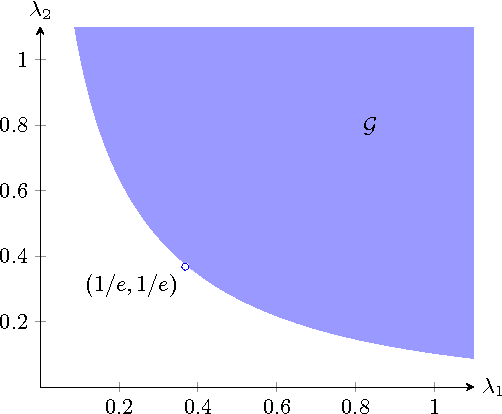
The principal submatrix localization problem deals with recovering a $K\times K$ principal submatrix of elevated mean $\mu$ in a large $n\times n$ symmetric matrix subject to additive standard Gaussian noise. This problem serves as a prototypical example for community detection, in which the community corresponds to the support of the submatrix. The main result of this paper is that in the regime $\Omega(\sqrt{n}) \leq K \leq o(n)$, the support of the submatrix can be weakly recovered (with $o(K)$ misclassification errors on average) by an optimized message passing algorithm if $\lambda = \mu^2K^2/n$, the signal-to-noise ratio, exceeds $1/e$. This extends a result by Deshpande and Montanari previously obtained for $K=\Theta(\sqrt{n}).$ In addition, the algorithm can be extended to provide exact recovery whenever information-theoretically possible and achieve the information limit of exact recovery as long as $K \geq \frac{n}{\log n} (\frac{1}{8e} + o(1))$. The total running time of the algorithm is $O(n^2\log n)$. Another version of the submatrix localization problem, known as noisy biclustering, aims to recover a $K_1\times K_2$ submatrix of elevated mean $\mu$ in a large $n_1\times n_2$ Gaussian matrix. The optimized message passing algorithm and its analysis are adapted to the bicluster problem assuming $\Omega(\sqrt{n_i}) \leq K_i \leq o(n_i)$ and $K_1\asymp K_2.$ A sharp information-theoretic condition for the weak recovery of both clusters is also identified.