 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-augmented Online Algorithm for Two-level Ski-rental Problem
Feb 09, 2024



In this paper, we study the two-level ski-rental problem,where a user needs to fulfill a sequence of demands for multiple items by choosing one of the three payment options: paying for the on-demand usage (i.e., rent), buying individual items (i.e., single purchase), and buying all the items (i.e., combo purchase). Without knowing future demands, the user aims to minimize the total cost (i.e., the sum of the rental, single purchase, and combo purchase costs) by balancing the trade-off between the expensive upfront costs (for purchase) and the potential future expenses (for rent). We first design a robust online algorithm (RDTSR) that offers a worst-case performance guarantee. While online algorithms are robust against the worst-case scenarios, they are often overly cautious and thus suffer a poor average performance in typical scenarios. On the other hand, Machine Learning (ML) algorithms typically show promising average performance in various applications but lack worst-case performance guarantees. To harness the benefits of both methods, we develop a learning-augmented algorithm (LADTSR) by integrating ML predictions into the robust online algorithm, which outperforms the robust online algorithm under accurate predictions while ensuring worst-case performance guarantees even when predictions are inaccurate. Finally, we conduct numerical experiments on both synthetic and real-world trace data to corroborate the effectiveness of our approach.
RoNet: Toward Robust Neural Assisted Mobile Network Configuration
Feb 07, 2023



Automating configuration is the key path to achieving zero-touch network management in ever-complicating mobile networks. Deep learning techniques show great potential to automatically learn and tackle high-dimensional networking problems. The vulnerability of deep learning to deviated input space, however, raises increasing deployment concerns under unpredictable variabilities and simulation-to-reality discrepancy in real-world networks. In this paper, we propose a novel RoNet framework to improve the robustness of neural-assisted configuration policies. We formulate the network configuration problem to maximize performance efficiency when serving diverse user applications. We design three integrated stages with novel normal training, learn-to-attack, and robust defense method for balancing the robustness and performance of policies. We evaluate RoNet via the NS-3 simulator extensively and the simulation results show that RoNet outperforms existing solutions in terms of robustness, adaptability, and scalability.
Atlas: Automate Online Service Configuration in Network Slicing
Oct 30, 2022



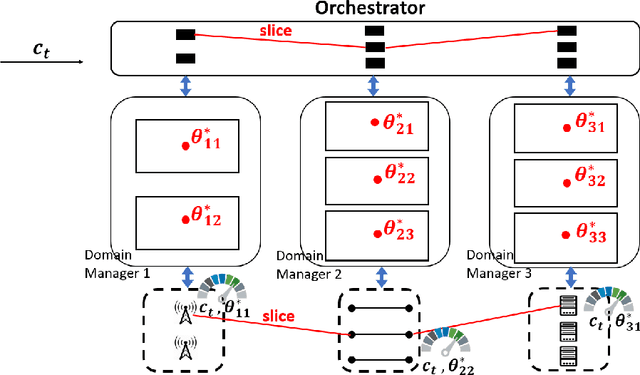
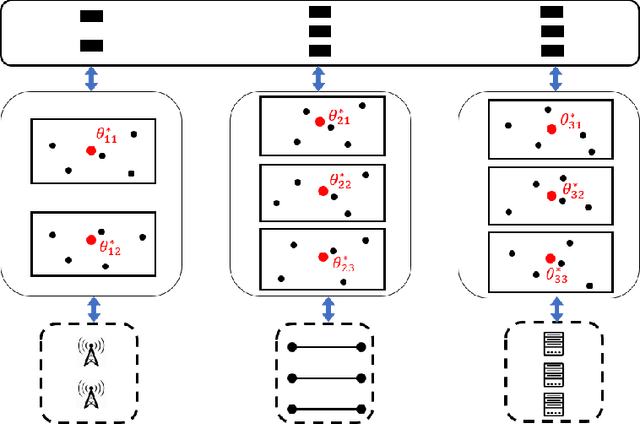
Network slicing achieves cost-efficient slice customization to support heterogeneous applications and services. Configuring cross-domain resources to end-to-end slices based on service-level agreements, however, is challenging, due to the complicated underlying correlations and the simulation-to-reality discrepancy between simulators and real networks. In this paper, we propose Atlas, an online network slicing system, which automates the service configuration of slices via safe and sample-efficient learn-to-configure approaches in three interrelated stages. First, we design a learning-based simulator to reduce the sim-to-real discrepancy, which is accomplished by a new parameter searching method based on Bayesian optimization. Second, we offline train the policy in the augmented simulator via a novel offline algorithm with a Bayesian neural network and parallel Thompson sampling. Third, we online learn the policy in real networks with a novel online algorithm with safe exploration and Gaussian process regression. We implement Atlas on an end-to-end network prototype based on OpenAirInterface RAN, OpenDayLight SDN transport, OpenAir-CN core network, and Docker-based edge server. Experimental results show that, compared to state-of-the-art solutions, Atlas achieves 63.9% and 85.7% regret reduction on resource usage and slice quality of experience during the online learning stage, respectively.
Regenerative Particle Thompson Sampling
Mar 15, 2022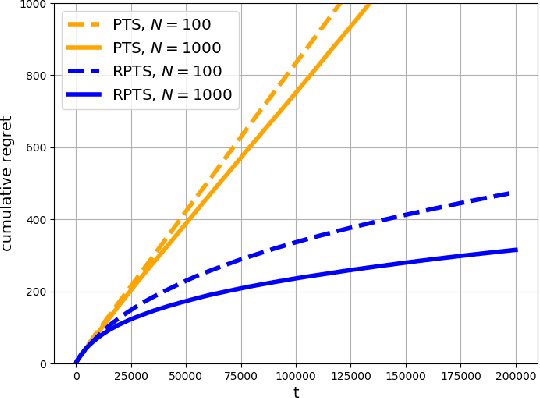
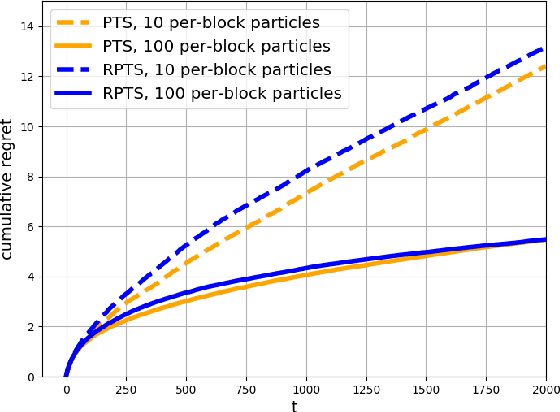
This paper proposes regenerative particle Thompson sampling (RPTS), a flexible variation of Thompson sampling. Thompson sampling itself is a Bayesian heuristic for solving stochastic bandit problems, but it is hard to implement in practice due to the intractability of maintaining a continuous posterior distribution. Particle Thompson sampling (PTS) is an approximation of Thompson sampling obtained by simply replacing the continuous distribution by a discrete distribution supported at a set of weighted static particles. We observe that in PTS, the weights of all but a few fit particles converge to zero. RPTS is based on the heuristic: delete the decaying unfit particles and regenerate new particles in the vicinity of fit surviving particles. Empirical evidence shows uniform improvement from PTS to RPTS and flexibility and efficacy of RPTS across a set of representative bandit problems, including an application to 5G network slicing.
OnSlicing: Online End-to-End Network Slicing with Reinforcement Learning
Nov 02, 2021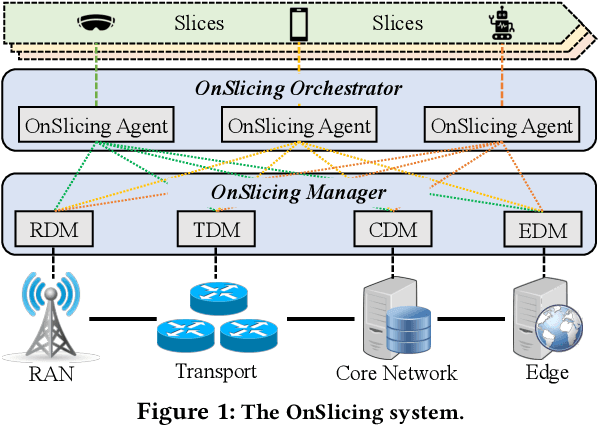
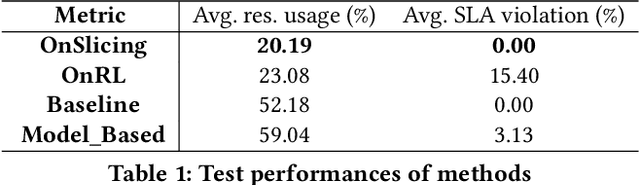
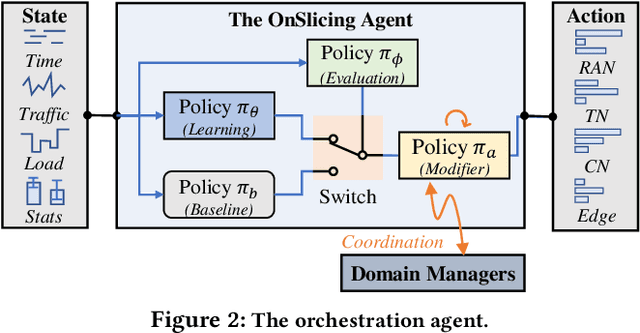
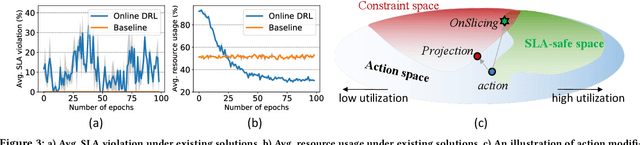
Network slicing allows mobile network operators to virtualize infrastructures and provide customized slices for supporting various use cases with heterogeneous requirements. Online deep reinforcement learning (DRL) has shown promising potential in solving network problems and eliminating the simulation-to-reality discrepancy. Optimizing cross-domain resources with online DRL is, however, challenging, as the random exploration of DRL violates the service level agreement (SLA) of slices and resource constraints of infrastructures. In this paper, we propose OnSlicing, an online end-to-end network slicing system, to achieve minimal resource usage while satisfying slices' SLA. OnSlicing allows individualized learning for each slice and maintains its SLA by using a novel constraint-aware policy update method and proactive baseline switching mechanism. OnSlicing complies with resource constraints of infrastructures by using a unique design of action modification in slices and parameter coordination in infrastructures. OnSlicing further mitigates the poor performance of online learning during the early learning stage by offline imitating a rule-based solution. Besides, we design four new domain managers to enable dynamic resource configuration in radio access, transport, core, and edge networks, respectively, at a timescale of subseconds. We implement OnSlicing on an end-to-end slicing testbed designed based on OpenAirInterface with both 4G LTE and 5G NR, OpenDayLight SDN platform, and OpenAir-CN core network. The experimental results show that OnSlicing achieves 61.3% usage reduction as compared to the rule-based solution and maintains nearly zero violation (0.06%) throughout the online learning phase. As online learning is converged, OnSlicing reduces 12.5% usage without any violations as compared to the state-of-the-art online DRL solution.