 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-augmented Online Minimization of Age of Information and Transmission Costs
Mar 05, 2024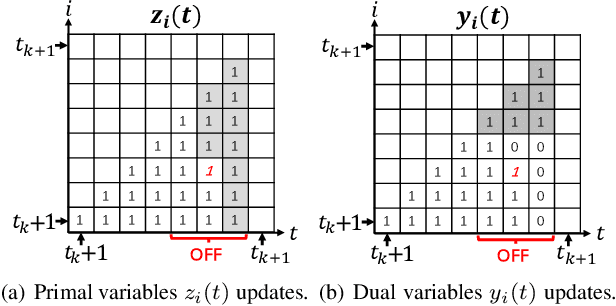
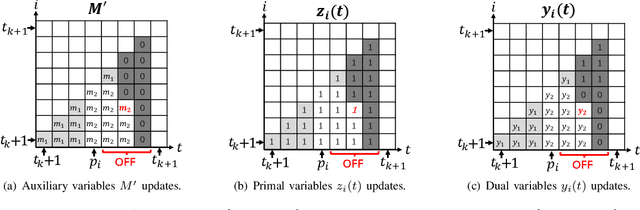
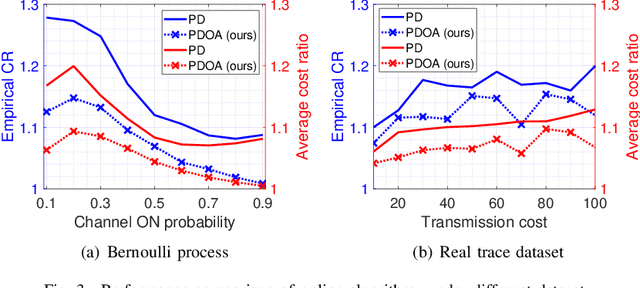
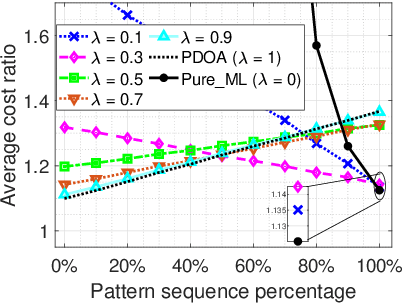
We consider a discrete-time system where a resource-constrained source (e.g., a small sensor) transmits its time-sensitive data to a destination over a time-varying wireless channel. Each transmission incurs a fixed transmission cost (e.g., energy cost), and no transmission results in a staleness cost represented by the Age-of-Information. The source must balance the tradeoff between transmission and staleness costs. To address this challenge, we develop a robust online algorithm to minimize the sum of transmission and staleness costs, ensuring a worst-case performance guarantee. While online algorithms are robust, they are usually overly conservative and may have a poor average performance in typical scenarios. In contrast, by leveraging historical data and prediction models, machine learning (ML) algorithms perform well in average cases. However, they typically lack worst-case performance guarantees. To achieve the best of both worlds, we design a learning-augmented online algorithm that exhibits two desired properties: (i) consistency: closely approximating the optimal offline algorithm when the ML prediction is accurate and trusted; (ii) robustness: ensuring worst-case performance guarantee even ML predictions are inaccurate. Finally, we perform extensive simulations to show that our online algorithm performs well empirically and that our learning-augmented algorithm achieves both consistency and robustness.
Learning-augmented Online Algorithm for Two-level Ski-rental Problem
Feb 09, 2024



In this paper, we study the two-level ski-rental problem,where a user needs to fulfill a sequence of demands for multiple items by choosing one of the three payment options: paying for the on-demand usage (i.e., rent), buying individual items (i.e., single purchase), and buying all the items (i.e., combo purchase). Without knowing future demands, the user aims to minimize the total cost (i.e., the sum of the rental, single purchase, and combo purchase costs) by balancing the trade-off between the expensive upfront costs (for purchase) and the potential future expenses (for rent). We first design a robust online algorithm (RDTSR) that offers a worst-case performance guarantee. While online algorithms are robust against the worst-case scenarios, they are often overly cautious and thus suffer a poor average performance in typical scenarios. On the other hand, Machine Learning (ML) algorithms typically show promising average performance in various applications but lack worst-case performance guarantees. To harness the benefits of both methods, we develop a learning-augmented algorithm (LADTSR) by integrating ML predictions into the robust online algorithm, which outperforms the robust online algorithm under accurate predictions while ensuring worst-case performance guarantees even when predictions are inaccurate. Finally, we conduct numerical experiments on both synthetic and real-world trace data to corroborate the effectiveness of our approach.
Waiting but not Aging: Age-of-Information and Utility Optimization Under the Pull Model
Dec 17, 2019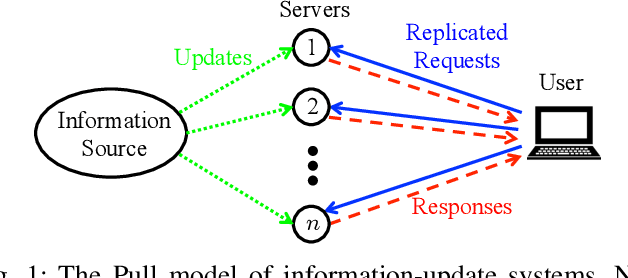
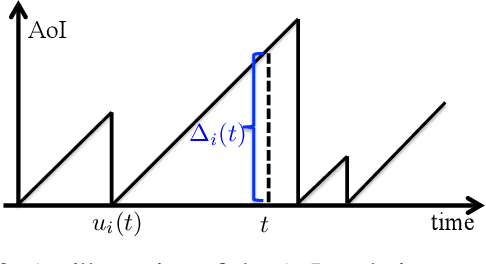

The Age-of-Information (AoI) has recently been proposed as an important metric for investigating the timeliness performance in information-update systems. In this paper, we introduce a new Pull model and study the AoI optimization problem under replication schemes. Interestingly, we find that under this new Pull model, replication schemes capture a novel tradeoff between different levels of information freshness and different response times across the servers, which can be exploited to minimize the expected AoI at the user's side. Specifically, assuming Poisson updating process for the servers and exponentially distributed response time, we derive a closed-form formula for computing the expected AoI and obtain the optimal number of responses to wait for to minimize the expected AoI. Then, we extend our analysis to the setting where the user aims to maximize the AoI-based utility, which represents the user's satisfaction level with respect to freshness of the received information. Furthermore, we consider a more realistic scenario where the user has no knowledge of the system. In this case, we reformulate the utility maximization problem as a stochastic Multi-Armed Bandit problem with side observations and leverage the unique structure of the problem to design learning algorithms with improved performance guarantees. Finally, we conduct extensive simulations to elucidate our theoretical results and compare the performance of different algorithms. Our findings reveal that under the Pull model, waiting for more than one response can significantly reduce the AoI and improve the AoI-based utility in most scenarios.