 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Sales Lead Scoring with LLM-based Hierarchical Preference Ranking
Jun 03, 2026Sales lead conversion in high-stakes domains (e.g., automotive, real estate) differs fundamentally from e-commerce recommendation due to prolonged decision cycles and multi-stage funnels. Traditional lead scoring methods rule-based scorecards, machine learning, or pointwise CTR models face severe challenges: sparse supervision, a semantic gap in unstructured CRM logs, and inability to capture relative lead priority. While Large Language Models(LLMs) offer superior semantic understanding of customer interactions, general-purpose LLMs are ill-suited for lead ranking: they generate text rather than comparable scores, and lack alignment with the hierarchical priorities of sales funnels. We introduce an LLM-based discriminative framework for sales lead scoring, which supports joint modeling of structured CRM features and unstructured customer interactions. On top of this framework, we propose HPRO (Hierarchical Preference Ranking Optimization), which augments sales lead scoring with a hierarchical preference ranking objective. HPRO employs a margin-aware Bradley-Terry formulation to transform sparse binary labels into dense, funnel-aware preference pairs, enabling lead scoring to leverage both pointwise and pairwise supervision. Experiments on large-scale data from a leading NEV brand demonstrate state-of-the-art classification (AUC 0.8161) and ranking performance (+39.7% precision among top-ranked leads). A 132-day online A/B test validates 9.5% sales volume uplift, confirming real-world commercial impact.
Deep Learning-Based Meat Freshness Detection with Segmentation and OOD-Aware Classification
Feb 27, 2026In this study, we present a meat freshness classification framework from Red-Green-Blue (RGB) images that supports both packaged and unpackaged meat datasets. The system classifies four in-distribution (ID) meat classes and uses an out-of-distribution (OOD)-aware abstention mechanism that flags low-confidence samples as No Result. The pipeline combines U-Net-based segmentation with deep feature classifiers. Segmentation is used as a preprocessing step to isolate the meat region and reduce background, producing more consistent inputs for classification. The segmentation module achieved an Intersection over Union (IoU) of 75% and a Dice coefficient of 82%, producing standardized inputs for the classification stage. For classification, we benchmark five backbones: Residual Network-50 (ResNet-50), Vision Transformer-Base/16 (ViT-B/16), Swin Transformer-Tiny (Swin-T), EfficientNet-B0, and MobileNetV3-Small. We use nested 5x3 cross-validation (CV) for model selection and hyperparameter tuning. On the held-out ID test set, EfficientNet-B0 achieves the highest accuracy (98.10%), followed by ResNet-50 and MobileNetV3-Small (both 97.63%) and Swin-T (97.51%), while ViT-B/16 is lower (94.42%). We additionally evaluate OOD scoring and thresholding using standard OOD metrics and sensitivity analysis over the abstention threshold. Finally, we report on-device latency using TensorFlow Lite (TFLite) on a smartphone, highlighting practical accuracy-latency trade-offs for future deployment.
Adaptive Underwater Acoustic Communications with Limited Feedback: An AoI-Aware Hierarchical Bandit Approach
Feb 23, 2026Underwater Acoustic (UWA) networks are vital for remote sensing and ocean exploration but face inherent challenges such as limited bandwidth, long propagation delays, and highly dynamic channels. These constraints hinder real-time communication and degrade overall system performance. To address these challenges, this paper proposes a bilevel Multi-Armed Bandit (MAB) framework. At the fast inner level, a Contextual Delayed MAB (CD-MAB) jointly optimizes adaptive modulation and transmission power based on both channel state feedback and its Age of Information (AoI), thereby maximizing throughput. At the slower outer level, a Feedback Scheduling MAB dynamically adjusts the channel-state feedback interval according to throughput dynamics: stable throughput allows longer update intervals, while throughput drops trigger more frequent updates. This adaptive mechanism reduces feedback overhead and enhances responsiveness to varying network conditions. The proposed bilevel framework is computationally efficient and well-suited to resource-constrained UWA networks. Simulation results using the DESERT Underwater Network Simulator demonstrate throughput gains of up to 20.61% and energy savings of up to 36.60% compared with Deep Reinforcement Learning (DRL) baselines reported in the existing literature.
Balancing Rewards in Text Summarization: Multi-Objective Reinforcement Learning via HyperVolume Optimization
Oct 22, 2025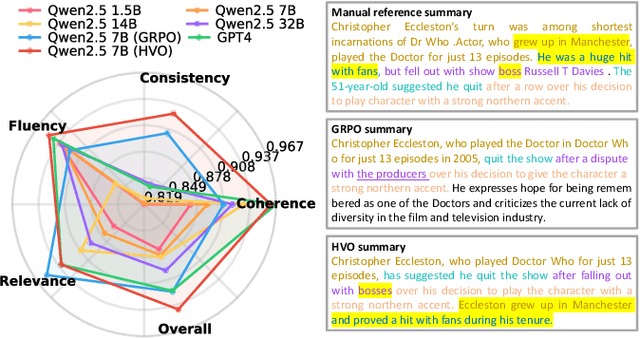
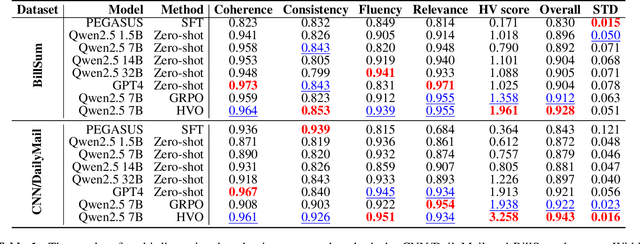
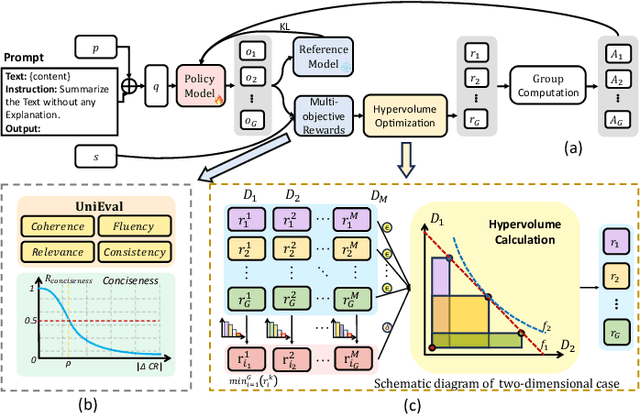

Text summarization is a crucial task that requires the simultaneous optimization of multiple objectives, including consistency, coherence, relevance, and fluency, which presents considerable challenges. Although large language models (LLMs) have demonstrated remarkable performance, enhanced by reinforcement learning (RL), few studies have focused on optimizing the multi-objective problem of summarization through RL based on LLMs. In this paper, we introduce hypervolume optimization (HVO), a novel optimization strategy that dynamically adjusts the scores between groups during the reward process in RL by using the hypervolume method. This method guides the model's optimization to progressively approximate the pareto front, thereby generating balanced summaries across multiple objectives. Experimental results on several representative summarization datasets demonstrate that our method outperforms group relative policy optimization (GRPO) in overall scores and shows more balanced performance across different dimensions. Moreover, a 7B foundation model enhanced by HVO performs comparably to GPT-4 in the summarization task, while maintaining a shorter generation length. Our code is publicly available at https://github.com/ai4business-LiAuto/HVO.git
Multimodal Remote Inference
Aug 11, 2025We consider a remote inference system with multiple modalities, where a multimodal machine learning (ML) model performs real-time inference using features collected from remote sensors. As sensor observations may change dynamically over time, fresh features are critical for inference tasks. However, timely delivering features from all modalities is often infeasible due to limited network resources. To this end, we study a two-modality scheduling problem to minimize the ML model's inference error, which is expressed as a penalty function of AoI for both modalities. We develop an index-based threshold policy and prove its optimality. Specifically, the scheduler switches modalities when the current modality's index function exceeds a threshold. We show that the two modalities share the same threshold, and both the index functions and the threshold can be computed efficiently. The optimality of our policy holds for (i) general AoI functions that are \emph{non-monotonic} and \emph{non-additive} and (ii) \emph{heterogeneous} transmission times. Numerical results show that our policy reduces inference error by up to 55% compared to round-robin and uniform random policies, which are oblivious to the AoI-based inference error function. Our results shed light on how to improve remote inference accuracy by optimizing task-oriented AoI functions.
Send Pilot or Data? Leveraging Age of Channel State Information for Throughput Maximization
Mar 18, 2025



In this paper, we study the optimal timing for pilot and data transmissions to maximize effective throughput, also known as goodput, over a wireless fading channel. The receiver utilizes the received pilot signal and its Age of Information (AoI), termed the Age of Channel State Information (AoCSI), to estimate the channel state. Based on this estimation, the transmitter selects an appropriate modulation and coding scheme (MCS) to maximize goodput while ensuring compliance with a predefined block error probability constraint. Furthermore, we design an optimal pilot scheduling policy that determines whether to transmit a pilot or data at each time step, with the objective of maximizing the long-term average goodput. This problem involves a non-monotonic AoI metric optimization challenge, as the goodput function is non-monotonic with respect to AoCSI. The numerical results illustrate the performance gains achieved by the proposed policy under various SNR levels and mobility speeds.
Timely Remote Estimation with Memory at the Receiver
Jan 03, 2025


In this study, we consider a remote estimation system that estimates a time-varying target based on sensor data transmitted over wireless channel. Due to transmission errors, some data packets fail to reach the receiver. To mitigate this, the receiver uses a buffer to store recently received data packets, which allows for more accurate estimation from the incomplete received data. Our research focuses on optimizing the transmission scheduling policy to minimize the estimation error, which is quantified as a function of the age of information vector associated with the buffered packets. Our results show that maintaining a buffer at the receiver results in better estimation performance for non-Markovian sources.
Goal-Oriented Communications for Real-time Inference with Two-Way Delay
Oct 11, 2024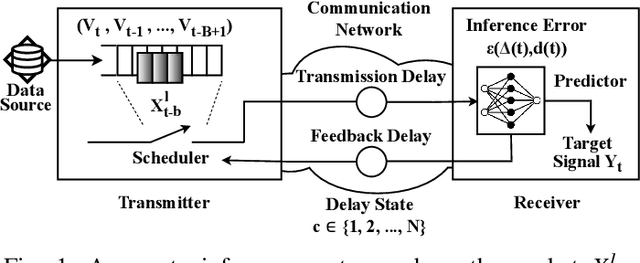
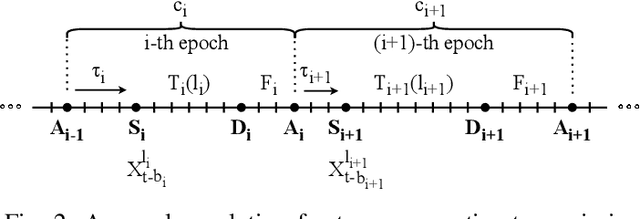
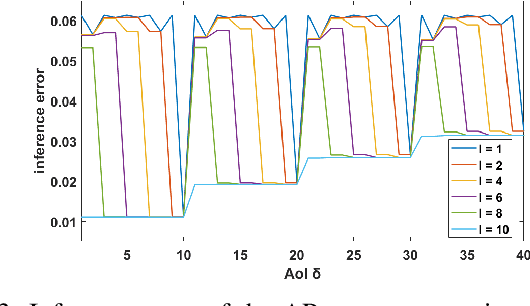
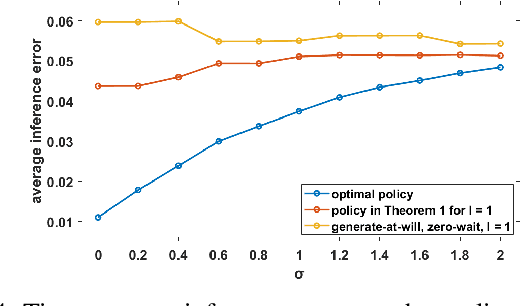
We design a goal-oriented communication strategy for remote inference, where an intelligent model (e.g., a pre-trained neural network) at the receiver side predicts the real-time value of a target signal based on data packets transmitted from a remote location. The inference error depends on both the Age of Information (AoI) and the length of the data packets. Previous formulations of this problem either assumed IID transmission delays with immediate feedback or focused only on monotonic relations where inference performance degrades as the input data ages. In contrast, we consider a possibly non-monotonic relationship between the inference error and AoI. We show how to minimize the expected time-average inference error under two-way delay, where the delay process can have memory. Simulation results highlight the significant benefits of adopting such a goal-oriented communication strategy for remote inference, especially under highly variable delay scenarios.
Timely Communications for Remote Inference
Apr 25, 2024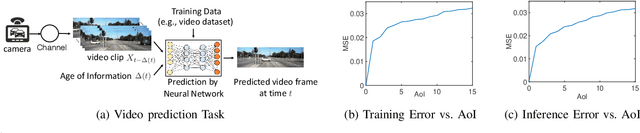
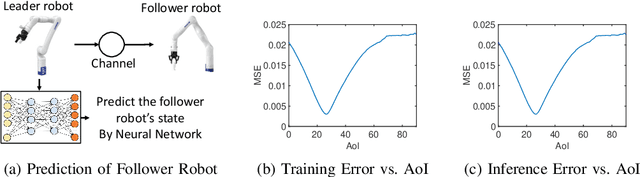
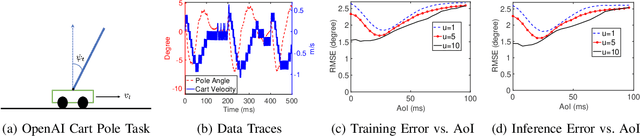

In this paper, we analyze the impact of data freshness on remote inference systems, where a pre-trained neural network infers a time-varying target (e.g., the locations of vehicles and pedestrians) based on features (e.g., video frames) observed at a sensing node (e.g., a camera). One might expect that the performance of a remote inference system degrades monotonically as the feature becomes stale. Using an information-theoretic analysis, we show that this is true if the feature and target data sequence can be closely approximated as a Markov chain, whereas it is not true if the data sequence is far from Markovian. Hence, the inference error is a function of Age of Information (AoI), where the function could be non-monotonic. To minimize the inference error in real-time, we propose a new "selection-from-buffer" model for sending the features, which is more general than the "generate-at-will" model used in earlier studies. In addition, we design low-complexity scheduling policies to improve inference performance. For single-source, single-channel systems, we provide an optimal scheduling policy. In multi-source, multi-channel systems, the scheduling problem becomes a multi-action restless multi-armed bandit problem. For this setting, we design a new scheduling policy by integrating Whittle index-based source selection and duality-based feature selection-from-buffer algorithms. This new scheduling policy is proven to be asymptotically optimal. These scheduling results hold for minimizing general AoI functions (monotonic or non-monotonic). Data-driven evaluations demonstrate the significant advantages of our proposed scheduling policies.
On the Monotonicity of Information Aging
Mar 06, 2024
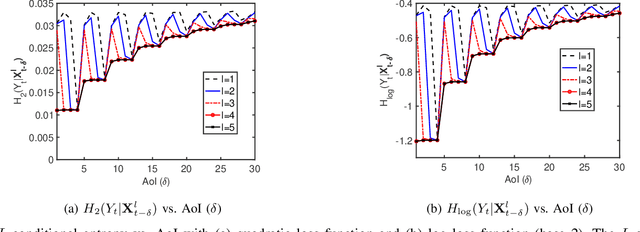
In this paper, we analyze the monotonicity of information aging in a remote estimation system, where historical observations of a Gaussian autoregressive AR(p) process are used to predict its future values. We consider two widely used loss functions in estimation: (i) logarithmic loss function for maximum likelihood estimation and (ii) quadratic loss function for MMSE estimation. The estimation error of the AR(p) process is written as a generalized conditional entropy which has closed-form expressions. By using a new information-theoretic tool called $\epsilon$-Markov chain, we can evaluate the divergence of the AR(p) process from being a Markov chain. When the divergence $\epsilon$ is large, the estimation error of the AR(p) process can be far from a non-decreasing function of the Age of Information (AoI). Conversely, for small divergence $\epsilon$, the inference error is close to a non-decreasing AoI function. Each observation is a short sequence taken from the AR(p) process. As the observation sequence length increases, the parameter $\epsilon$ progressively reduces to zero, and hence the estimation error becomes a non-decreasing AoI function. These results underscore a connection between the monotonicity of information aging and the divergence of from being a Markov chain.