 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestless Bandits with Individual Penalty Constraints: A New Near-Optimal Index Policy and How to Learn It
Apr 05, 2026This paper investigates the Restless Multi-Armed Bandit (RMAB) framework under individual penalty constraints to address resource allocation challenges in dynamic wireless networked environments. Unlike conventional RMAB models, our model allows each user (arm) to have distinct and stringent performance constraints, such as energy limits, activation limits, or age of information minimums, enabling the capture of diverse objectives including fairness and efficiency. To find the optimal resource allocation policy, we propose a new Penalty-Optimal Whittle (POW) index policy. The POW index of an user only depends on the user's transition kernel and penalty constraints, and remains invariable to system-wide features such as the number of users present and the amount of resource available. This makes it computationally tractable to calculate the POW Indices offline without any need for online adaptation. Moreover, we theoretically prove that the POW index policy is asymptotically optimal while satisfying all individual penalty constraints. We also introduce a deep reinforcement learning algorithm to efficiently learn the POW index on the fly. Simulation results across various applications and system configurations further demonstrate that the POW index policy not only has near-optimal performance but also significantly outperforms other existing policies.
Deep Index Policy for Multi-Resource Restless Matching Bandit and Its Application in Multi-Channel Scheduling
Aug 13, 2024Scheduling in multi-channel wireless communication system presents formidable challenges in effectively allocating resources. To address these challenges, we investigate the multi-resource restless matching bandit (MR-RMB) model for heterogeneous resource systems with an objective of maximizing long-term discounted total rewards while respecting resource constraints. We have also generalized to applications beyond multi-channel wireless. We discuss the Max-Weight Index Matching algorithm, which optimizes resource allocation based on learned partial indexes. We have derived the policy gradient theorem for index learning. Our main contribution is the introduction of a new Deep Index Policy (DIP), an online learning algorithm tailored for MR-RMB. DIP learns the partial index by leveraging the policy gradient theorem for restless arms with convoluted and unknown transition kernels of heterogeneous resources. We demonstrate the utility of DIP by evaluating its performance for three different MR-RMB problems. Our simulation results show that DIP indeed learns the partial indexes efficiently.
Timely Communications for Remote Inference
Apr 25, 2024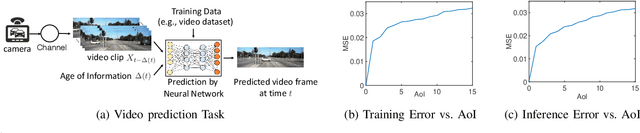
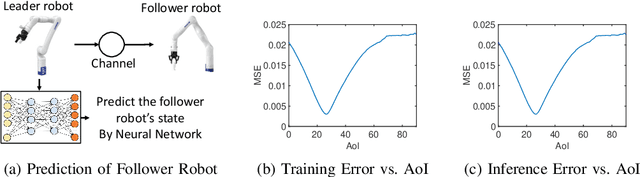
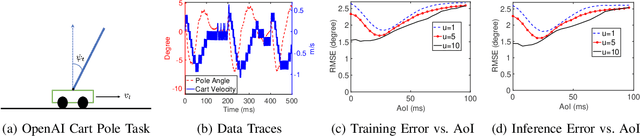

In this paper, we analyze the impact of data freshness on remote inference systems, where a pre-trained neural network infers a time-varying target (e.g., the locations of vehicles and pedestrians) based on features (e.g., video frames) observed at a sensing node (e.g., a camera). One might expect that the performance of a remote inference system degrades monotonically as the feature becomes stale. Using an information-theoretic analysis, we show that this is true if the feature and target data sequence can be closely approximated as a Markov chain, whereas it is not true if the data sequence is far from Markovian. Hence, the inference error is a function of Age of Information (AoI), where the function could be non-monotonic. To minimize the inference error in real-time, we propose a new "selection-from-buffer" model for sending the features, which is more general than the "generate-at-will" model used in earlier studies. In addition, we design low-complexity scheduling policies to improve inference performance. For single-source, single-channel systems, we provide an optimal scheduling policy. In multi-source, multi-channel systems, the scheduling problem becomes a multi-action restless multi-armed bandit problem. For this setting, we design a new scheduling policy by integrating Whittle index-based source selection and duality-based feature selection-from-buffer algorithms. This new scheduling policy is proven to be asymptotically optimal. These scheduling results hold for minimizing general AoI functions (monotonic or non-monotonic). Data-driven evaluations demonstrate the significant advantages of our proposed scheduling policies.
Distributed No-Regret Learning for Multi-Stage Systems with End-to-End Bandit Feedback
Apr 06, 2024This paper studies multi-stage systems with end-to-end bandit feedback. In such systems, each job needs to go through multiple stages, each managed by a different agent, before generating an outcome. Each agent can only control its own action and learn the final outcome of the job. It has neither knowledge nor control on actions taken by agents in the next stage. The goal of this paper is to develop distributed online learning algorithms that achieve sublinear regret in adversarial environments. The setting of this paper significantly expands the traditional multi-armed bandit problem, which considers only one agent and one stage. In addition to the exploration-exploitation dilemma in the traditional multi-armed bandit problem, we show that the consideration of multiple stages introduces a third component, education, where an agent needs to choose its actions to facilitate the learning of agents in the next stage. To solve this newly introduced exploration-exploitation-education trilemma, we propose a simple distributed online learning algorithm, $\epsilon-$EXP3. We theoretically prove that the $\epsilon-$EXP3 algorithm is a no-regret policy that achieves sublinear regret. Simulation results show that the $\epsilon-$EXP3 algorithm significantly outperforms existing no-regret online learning algorithms for the traditional multi-armed bandit problem.
Contextual Restless Multi-Armed Bandits with Application to Demand Response Decision-Making
Mar 22, 2024This paper introduces a novel multi-armed bandits framework, termed Contextual Restless Bandits (CRB), for complex online decision-making. This CRB framework incorporates the core features of contextual bandits and restless bandits, so that it can model both the internal state transitions of each arm and the influence of external global environmental contexts. Using the dual decomposition method, we develop a scalable index policy algorithm for solving the CRB problem, and theoretically analyze the asymptotical optimality of this algorithm. In the case when the arm models are unknown, we further propose a model-based online learning algorithm based on the index policy to learn the arm models and make decisions simultaneously. Furthermore, we apply the proposed CRB framework and the index policy algorithm specifically to the demand response decision-making problem in smart grids. The numerical simulations demonstrate the performance and efficiency of our proposed CRB approaches.
DeepTOP: Deep Threshold-Optimal Policy for MDPs and RMABs
Sep 28, 2022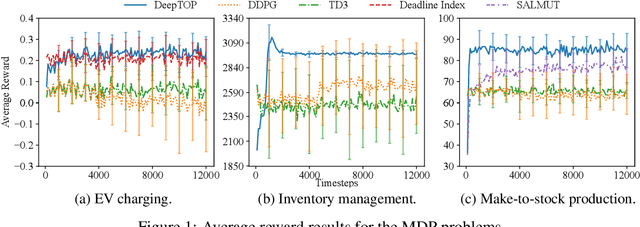
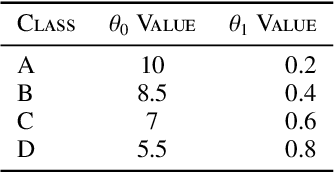
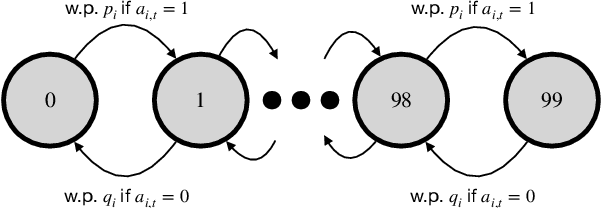
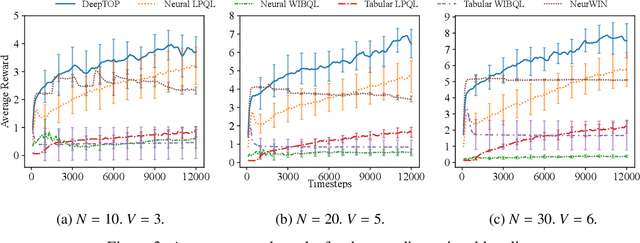
We consider the problem of learning the optimal threshold policy for control problems. Threshold policies make control decisions by evaluating whether an element of the system state exceeds a certain threshold, whose value is determined by other elements of the system state. By leveraging the monotone property of threshold policies, we prove that their policy gradients have a surprisingly simple expression. We use this simple expression to build an off-policy actor-critic algorithm for learning the optimal threshold policy. Simulation results show that our policy significantly outperforms other reinforcement learning algorithms due to its ability to exploit the monotone property. In addition, we show that the Whittle index, a powerful tool for restless multi-armed bandit problems, is equivalent to the optimal threshold policy for an alternative problem. This observation leads to a simple algorithm that finds the Whittle index by learning the optimal threshold policy in the alternative problem. Simulation results show that our algorithm learns the Whittle index much faster than several recent studies that learn the Whittle index through indirect means.
NeurWIN: Neural Whittle Index Network For Restless Bandits Via Deep RL
Oct 05, 2021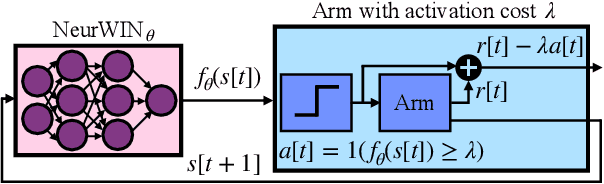
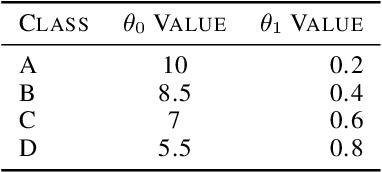
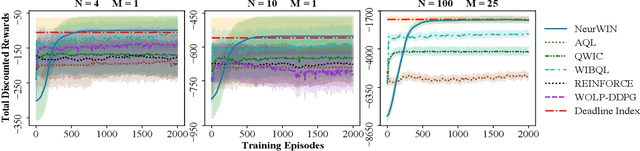
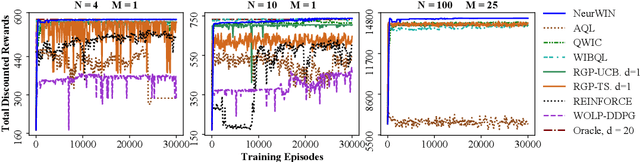
Whittle index policy is a powerful tool to obtain asymptotically optimal solutions for the notoriously intractable problem of restless bandits. However, finding the Whittle indices remains a difficult problem for many practical restless bandits with convoluted transition kernels. This paper proposes NeurWIN, a neural Whittle index network that seeks to learn the Whittle indices for any restless bandits by leveraging mathematical properties of the Whittle indices. We show that a neural network that produces the Whittle index is also one that produces the optimal control for a set of Markov decision problems. This property motivates using deep reinforcement learning for the training of NeurWIN. We demonstrate the utility of NeurWIN by evaluating its performance for three recently studied restless bandit problems. Our experiment results show that the performance of NeurWIN is significantly better than other RL algorithms.