 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoTL: Egocentric Think-Aloud Chains for Long-Horizon Tasks
Apr 10, 2026Large foundation models have made significant advances in embodied intelligence, enabling synthesis and reasoning over egocentric input for household tasks. However, VLM-based auto-labeling is often noisy because the primary data sources lack accurate human action labels, chain-of-thought (CoT), and spatial annotations; these errors are amplified during long-horizon spatial instruction following. These issues stem from insufficient coverage of minute-long, daily household planning tasks and from inaccurate spatial grounding. As a result, VLM reasoning chains and world-model synthesis can hallucinate objects, skip steps, or fail to respect real-world physical attributes. To address these gaps, we introduce EgoTL. EgoTL builds a think-aloud capture pipeline for egocentric data. It uses a say-before-act protocol to record step-by-step goals and spoken reasoning with word-level timestamps, then calibrates physical properties with metric-scale spatial estimators, a memory-bank walkthrough for scene context, and clip-level tags for navigation instructions and detailed manipulation actions. With EgoTL, we are able to benchmark VLMs and World Models on six task dimensions from three layers and long-horizon generation over minute-long sequences across over 100 daily household tasks. We find that foundation models still fall short as egocentric assistants or open-world simulators. Finally, we finetune foundation models with human CoT aligned with metric labels on the training split of EgoTL, which improves long-horizon planning and reasoning, step-wise reasoning, instruction following, and spatial grounding.
PITA: Preference-Guided Inference-Time Alignment for LLM Post-Training
Jul 26, 2025



Inference-time alignment enables large language models (LLMs) to generate outputs aligned with end-user preferences without further training. Recent post-training methods achieve this by using small guidance models to modify token generation during inference. These methods typically optimize a reward function KL-regularized by the original LLM taken as the reference policy. A critical limitation, however, is their dependence on a pre-trained reward model, which requires fitting to human preference feedback--a potentially unstable process. In contrast, we introduce PITA, a novel framework that integrates preference feedback directly into the LLM's token generation, eliminating the need for a reward model. PITA learns a small preference-based guidance policy to modify token probabilities at inference time without LLM fine-tuning, reducing computational cost and bypassing the pre-trained reward model dependency. The problem is framed as identifying an underlying preference distribution, solved through stochastic search and iterative refinement of the preference-based guidance model. We evaluate PITA across diverse tasks, including mathematical reasoning and sentiment classification, demonstrating its effectiveness in aligning LLM outputs with user preferences.
Risk-Averse Finetuning of Large Language Models
Jan 12, 2025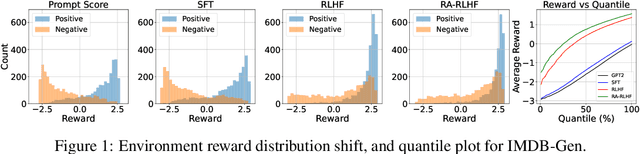
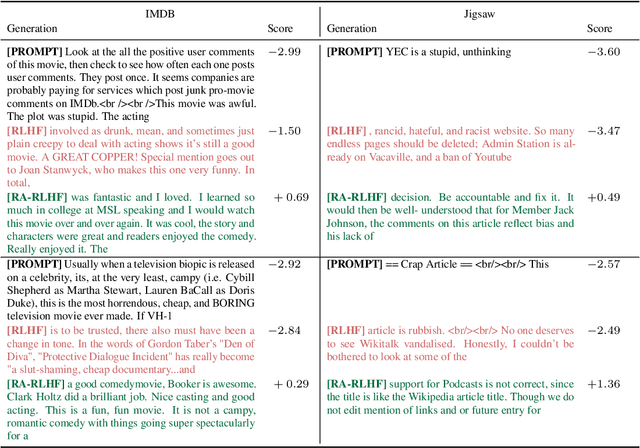
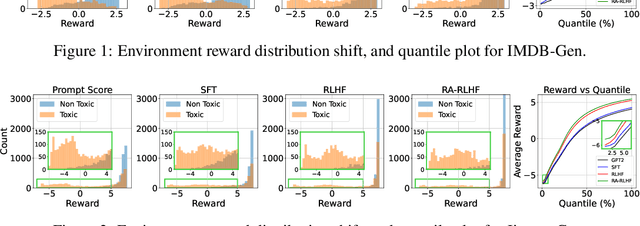
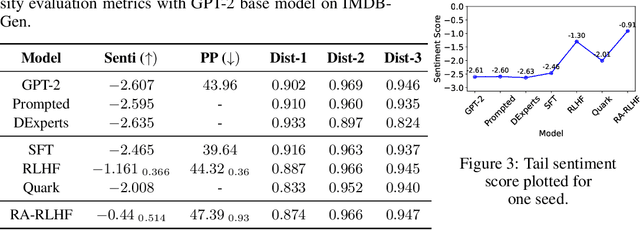
We consider the challenge of mitigating the generation of negative or toxic content by the Large Language Models (LLMs) in response to certain prompts. We propose integrating risk-averse principles into LLM fine-tuning to minimize the occurrence of harmful outputs, particularly rare but significant events. By optimizing the risk measure of Conditional Value at Risk (CVaR), our methodology trains LLMs to exhibit superior performance in avoiding toxic outputs while maintaining effectiveness in generative tasks. Empirical evaluations on sentiment modification and toxicity mitigation tasks demonstrate the efficacy of risk-averse reinforcement learning with human feedback (RLHF) in promoting a safer and more constructive online discourse environment.
DOPL: Direct Online Preference Learning for Restless Bandits with Preference Feedback
Oct 07, 2024



Restless multi-armed bandits (RMAB) has been widely used to model constrained sequential decision making problems, where the state of each restless arm evolves according to a Markov chain and each state transition generates a scalar reward. However, the success of RMAB crucially relies on the availability and quality of reward signals. Unfortunately, specifying an exact reward function in practice can be challenging and even infeasible. In this paper, we introduce Pref-RMAB, a new RMAB model in the presence of preference signals, where the decision maker only observes pairwise preference feedback rather than scalar reward from the activated arms at each decision epoch. Preference feedback, however, arguably contains less information than the scalar reward, which makes Pref-RMAB seemingly more difficult. To address this challenge, we present a direct online preference learning (DOPL) algorithm for Pref-RMAB to efficiently explore the unknown environments, adaptively collect preference data in an online manner, and directly leverage the preference feedback for decision-makings. We prove that DOPL yields a sublinear regret. To our best knowledge, this is the first algorithm to ensure $\tilde{\mathcal{O}}(\sqrt{T\ln T})$ regret for RMAB with preference feedback. Experimental results further demonstrate the effectiveness of DOPL.
CONGO: Compressive Online Gradient Optimization with Application to Microservices Management
Jul 08, 2024


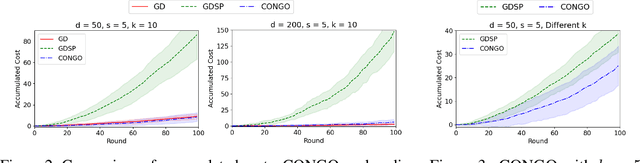
We address the challenge of online convex optimization where the objective function's gradient exhibits sparsity, indicating that only a small number of dimensions possess non-zero gradients. Our aim is to leverage this sparsity to obtain useful estimates of the objective function's gradient even when the only information available is a limited number of function samples. Our motivation stems from distributed queueing systems like microservices-based applications, characterized by request-response workloads. Here, each request type proceeds through a sequence of microservices to produce a response, and the resource allocation across the collection of microservices is controlled to balance end-to-end latency with resource costs. While the number of microservices is substantial, the latency function primarily reacts to resource changes in a few, rendering the gradient sparse. Our proposed method, CONGO (Compressive Online Gradient Optimization), combines simultaneous perturbation with compressive sensing to estimate gradients. We establish analytical bounds on the requisite number of compressive sensing samples per iteration to maintain bounded bias of gradient estimates, ensuring sub-linear regret. By exploiting sparsity, we reduce the samples required per iteration to match the gradient's sparsity, rather than the problem's original dimensionality. Numerical experiments and real-world microservices benchmarks demonstrate CONGO's superiority over multiple stochastic gradient descent approaches, as it quickly converges to performance comparable to policies pre-trained with workload awareness.
Structured Reinforcement Learning for Media Streaming at the Wireless Edge
Apr 10, 2024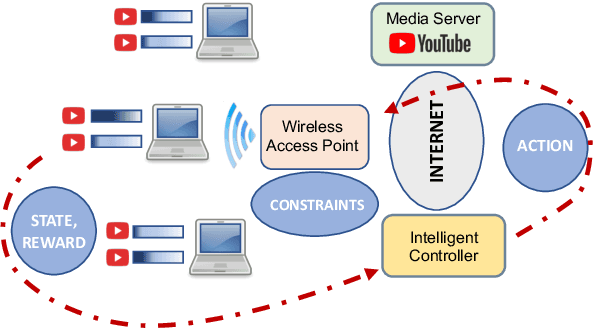
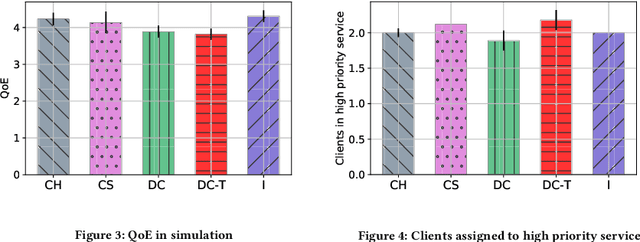
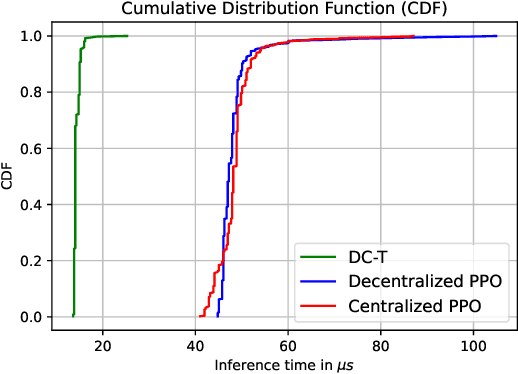
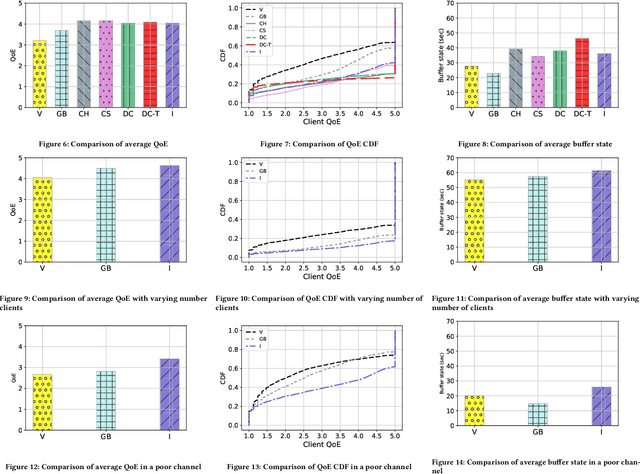
Media streaming is the dominant application over wireless edge (access) networks. The increasing softwarization of such networks has led to efforts at intelligent control, wherein application-specific actions may be dynamically taken to enhance the user experience. The goal of this work is to develop and demonstrate learning-based policies for optimal decision making to determine which clients to dynamically prioritize in a video streaming setting. We formulate the policy design question as a constrained Markov decision problem (CMDP), and observe that by using a Lagrangian relaxation we can decompose it into single-client problems. Further, the optimal policy takes a threshold form in the video buffer length, which enables us to design an efficient constrained reinforcement learning (CRL) algorithm to learn it. Specifically, we show that a natural policy gradient (NPG) based algorithm that is derived using the structure of our problem converges to the globally optimal policy. We then develop a simulation environment for training, and a real-world intelligent controller attached to a WiFi access point for evaluation. We empirically show that the structured learning approach enables fast learning. Furthermore, such a structured policy can be easily deployed due to low computational complexity, leading to policy execution taking only about 15$\mu$s. Using YouTube streaming experiments in a resource constrained scenario, we demonstrate that the CRL approach can increase QoE by over 30%.
Transformers are Efficient In-Context Estimators for Wireless Communication
Nov 01, 2023



Pre-trained transformers can perform in-context learning, where they adapt to a new task using only a small number of prompts without any explicit model optimization. Inspired by this attribute, we propose a novel approach, called in-context estimation, for the canonical communication problem of estimating transmitted symbols from received symbols. A communication channel is essentially a noisy function that maps transmitted symbols to received symbols, and this function can be represented by an unknown parameter whose statistics depend on an (also unknown) latent context. Conventional approaches ignore this hierarchical structure and simply attempt to use known transmissions, called pilots, to perform a least-squares estimate of the channel parameter, which is then used to estimate successive, unknown transmitted symbols. We make the basic connection that transformers show excellent contextual sequence completion with a few prompts, and so they should be able to implicitly determine the latent context from pilot symbols to perform end-to-end in-context estimation of transmitted symbols. Furthermore, the transformer should use information efficiently, i.e., it should utilize any pilots received to attain the best possible symbol estimates. Through extensive simulations, we show that in-context estimation not only significantly outperforms standard approaches, but also achieves the same performance as an estimator with perfect knowledge of the latent context within a few context examples. Thus, we make a strong case that transformers are efficient in-context estimators in the communication setting.
LLMZip: Lossless Text Compression using Large Language Models
Jun 26, 2023



We provide new estimates of an asymptotic upper bound on the entropy of English using the large language model LLaMA-7B as a predictor for the next token given a window of past tokens. This estimate is significantly smaller than currently available estimates in \cite{cover1978convergent}, \cite{lutati2023focus}. A natural byproduct is an algorithm for lossless compression of English text which combines the prediction from the large language model with a lossless compression scheme. Preliminary results from limited experiments suggest that our scheme outperforms state-of-the-art text compression schemes such as BSC, ZPAQ, and paq8h.
Federated Ensemble-Directed Offline Reinforcement Learning
May 04, 2023



We consider the problem of federated offline reinforcement learning (RL), a scenario under which distributed learning agents must collaboratively learn a high-quality control policy only using small pre-collected datasets generated according to different unknown behavior policies. Naively combining a standard offline RL approach with a standard federated learning approach to solve this problem can lead to poorly performing policies. In response, we develop the Federated Ensemble-Directed Offline Reinforcement Learning Algorithm (FEDORA), which distills the collective wisdom of the clients using an ensemble learning approach. We develop the FEDORA codebase to utilize distributed compute resources on a federated learning platform. We show that FEDORA significantly outperforms other approaches, including offline RL over the combined data pool, in various complex continuous control environments and real world datasets. Finally, we demonstrate the performance of FEDORA in the real-world on a mobile robot.
Energy System Digitization in the Era of AI: A Three-Layered Approach towards Carbon Neutrality
Nov 02, 2022The transition towards carbon-neutral electricity is one of the biggest game changers in addressing climate change since it addresses the dual challenges of removing carbon emissions from the two largest sectors of emitters: electricity and transportation. The transition to a carbon-neutral electric grid poses significant challenges to conventional paradigms of modern grid planning and operation. Much of the challenge arises from the scale of the decision making and the uncertainty associated with the energy supply and demand. Artificial Intelligence (AI) could potentially have a transformative impact on accelerating the speed and scale of carbon-neutral transition, as many decision making processes in the power grid can be cast as classic, though challenging, machine learning tasks. We point out that to amplify AI's impact on carbon-neutral transition of the electric energy systems, the AI algorithms originally developed for other applications should be tailored in three layers of technology, markets, and policy.