 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Reinforcement Learning for Media Streaming at the Wireless Edge
Apr 10, 2024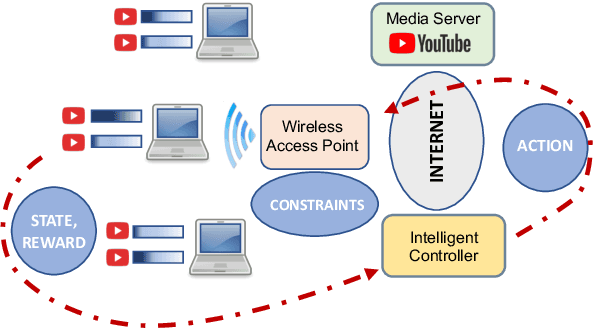
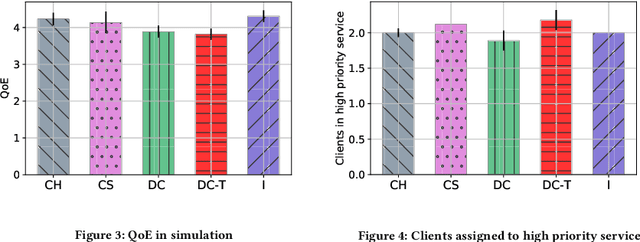
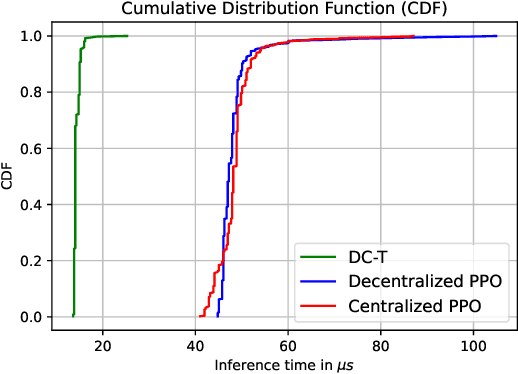
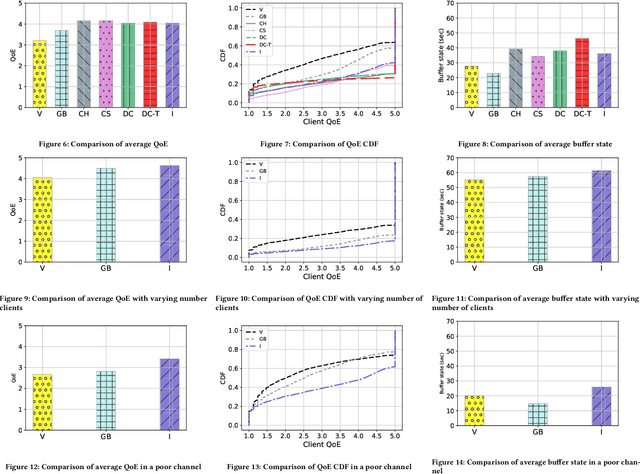
Media streaming is the dominant application over wireless edge (access) networks. The increasing softwarization of such networks has led to efforts at intelligent control, wherein application-specific actions may be dynamically taken to enhance the user experience. The goal of this work is to develop and demonstrate learning-based policies for optimal decision making to determine which clients to dynamically prioritize in a video streaming setting. We formulate the policy design question as a constrained Markov decision problem (CMDP), and observe that by using a Lagrangian relaxation we can decompose it into single-client problems. Further, the optimal policy takes a threshold form in the video buffer length, which enables us to design an efficient constrained reinforcement learning (CRL) algorithm to learn it. Specifically, we show that a natural policy gradient (NPG) based algorithm that is derived using the structure of our problem converges to the globally optimal policy. We then develop a simulation environment for training, and a real-world intelligent controller attached to a WiFi access point for evaluation. We empirically show that the structured learning approach enables fast learning. Furthermore, such a structured policy can be easily deployed due to low computational complexity, leading to policy execution taking only about 15$\mu$s. Using YouTube streaming experiments in a resource constrained scenario, we demonstrate that the CRL approach can increase QoE by over 30%.
Safe Exploration for Constrained Reinforcement Learning with Provable Guarantees
Dec 01, 2021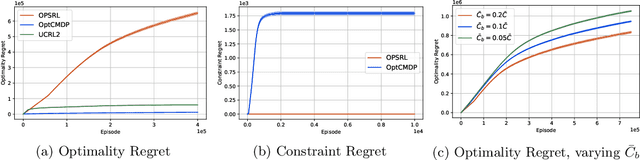
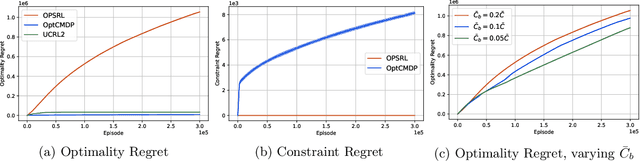
We consider the problem of learning an episodic safe control policy that minimizes an objective function, while satisfying necessary safety constraints -- both during learning and deployment. We formulate this safety constrained reinforcement learning (RL) problem using the framework of a finite-horizon Constrained Markov Decision Process (CMDP) with an unknown transition probability function. Here, we model the safety requirements as constraints on the expected cumulative costs that must be satisfied during all episodes of learning. We propose a model-based safe RL algorithm that we call the Optimistic-Pessimistic Safe Reinforcement Learning (OPSRL) algorithm, and show that it achieves an $\tilde{\mathcal{O}}(S^{2}\sqrt{A H^{7}K}/ (\bar{C} - \bar{C}_{b}))$ cumulative regret without violating the safety constraints during learning, where $S$ is the number of states, $A$ is the number of actions, $H$ is the horizon length, $K$ is the number of learning episodes, and $(\bar{C} - \bar{C}_{b})$ is the safety gap, i.e., the difference between the constraint value and the cost of a known safe baseline policy. The scaling as $\tilde{\mathcal{O}}(\sqrt{K})$ is the same as the traditional approach where constraints may be violated during learning, which means that our algorithm suffers no additional regret in spite of providing a safety guarantee. Our key idea is to use an optimistic exploration approach with pessimistic constraint enforcement for learning the policy. This approach simultaneously incentivizes the exploration of unknown states while imposing a penalty for visiting states that are likely to cause violation of safety constraints. We validate our algorithm by evaluating its performance on benchmark problems against conventional approaches.
QFlow: A Reinforcement Learning Approach to High QoE Video Streaming over Wireless Networks
Jan 04, 2019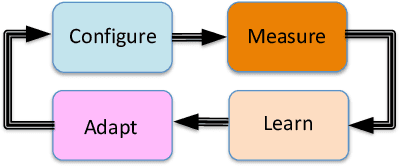
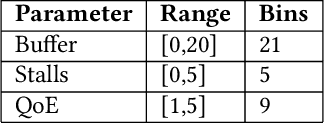

Wireless Internet access has brought legions of heterogeneous applications all sharing the same resources. However, current wireless edge networks that cater to worst or average case performance lack the agility to best serve these diverse sessions. Simultaneously, software reconfigurable infrastructure has become increasingly mainstream to the point that dynamic per packet and per flow decisions are possible at multiple layers of the communications stack. Exploiting such reconfigurability requires the design of a system that can enable a configuration, measure the impact on the application performance (Quality of Experience), and adaptively select a new configuration. Effectively, this feedback loop is a Markov Decision Process whose parameters are unknown. The goal of this work is to design, develop and demonstrate QFlow that instantiates this feedback loop as an application of reinforcement learning (RL). Our context is that of reconfigurable (priority) queueing, and we use the popular application of video streaming as our use case. We develop both model-free and model-based RL approaches that are tailored to the problem of determining which clients should be assigned to which queue at each decision period. Through experimental validation, we show how the RL-based control policies on QFlow are able to schedule the right clients for prioritization in a high-load scenario to outperform the status quo, as well as the best known solutions with over 25% improvement in QoE, and a perfect QoE score of 5 over 85% of the time.