 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Multi-Agent Framework for Carbon-Efficient Liquid-Cooled Data Center Clusters
Feb 12, 2025Reducing the environmental impact of cloud computing requires efficient workload distribution across geographically dispersed Data Center Clusters (DCCs) and simultaneously optimizing liquid and air (HVAC) cooling with time shift of workloads within individual data centers (DC). This paper introduces Green-DCC, which proposes a Reinforcement Learning (RL) based hierarchical controller to optimize both workload and liquid cooling dynamically in a DCC. By incorporating factors such as weather, carbon intensity, and resource availability, Green-DCC addresses realistic constraints and interdependencies. We demonstrate how the system optimizes multiple data centers synchronously, enabling the scope of digital twins, and compare the performance of various RL approaches based on carbon emissions and sustainability metrics while also offering a framework and benchmark simulation for broader ML research in sustainability.
SustainDC -- Benchmarking for Sustainable Data Center Control
Aug 14, 2024



Machine learning has driven an exponential increase in computational demand, leading to massive data centers that consume significant amounts of energy and contribute to climate change. This makes sustainable data center control a priority. In this paper, we introduce SustainDC, a set of Python environments for benchmarking multi-agent reinforcement learning (MARL) algorithms for data centers (DC). SustainDC supports custom DC configurations and tasks such as workload scheduling, cooling optimization, and auxiliary battery management, with multiple agents managing these operations while accounting for the effects of each other. We evaluate various MARL algorithms on SustainDC, showing their performance across diverse DC designs, locations, weather conditions, grid carbon intensity, and workload requirements. Our results highlight significant opportunities for improvement of data center operations using MARL algorithms. Given the increasing use of DC due to AI, SustainDC provides a crucial platform for the development and benchmarking of advanced algorithms essential for achieving sustainable computing and addressing other heterogeneous real-world challenges.
Structured Reinforcement Learning for Media Streaming at the Wireless Edge
Apr 10, 2024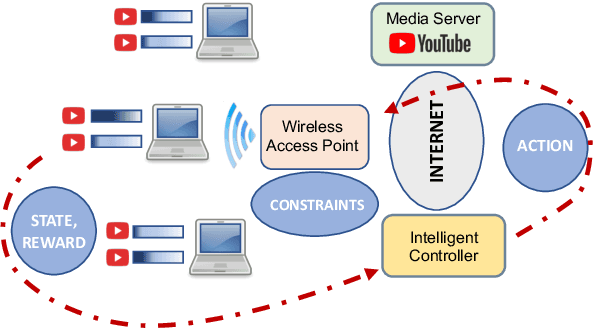
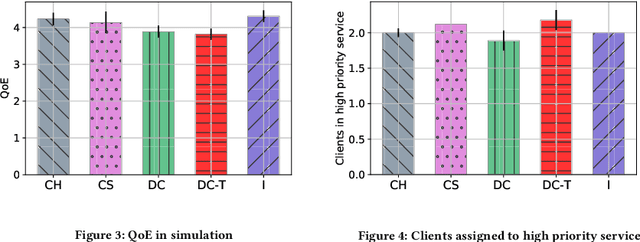
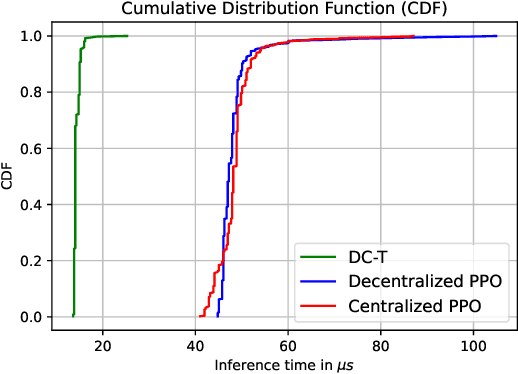
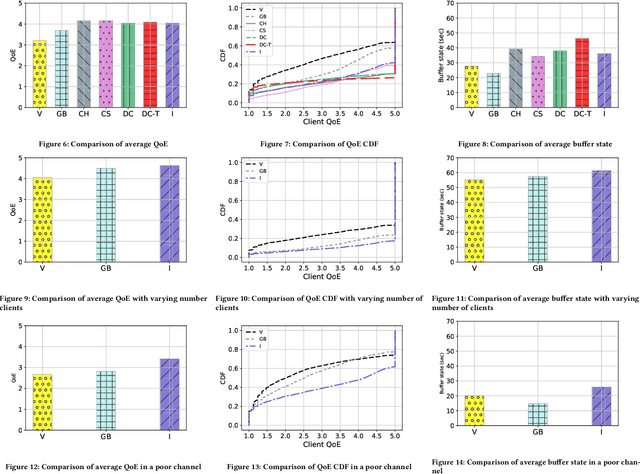
Media streaming is the dominant application over wireless edge (access) networks. The increasing softwarization of such networks has led to efforts at intelligent control, wherein application-specific actions may be dynamically taken to enhance the user experience. The goal of this work is to develop and demonstrate learning-based policies for optimal decision making to determine which clients to dynamically prioritize in a video streaming setting. We formulate the policy design question as a constrained Markov decision problem (CMDP), and observe that by using a Lagrangian relaxation we can decompose it into single-client problems. Further, the optimal policy takes a threshold form in the video buffer length, which enables us to design an efficient constrained reinforcement learning (CRL) algorithm to learn it. Specifically, we show that a natural policy gradient (NPG) based algorithm that is derived using the structure of our problem converges to the globally optimal policy. We then develop a simulation environment for training, and a real-world intelligent controller attached to a WiFi access point for evaluation. We empirically show that the structured learning approach enables fast learning. Furthermore, such a structured policy can be easily deployed due to low computational complexity, leading to policy execution taking only about 15$\mu$s. Using YouTube streaming experiments in a resource constrained scenario, we demonstrate that the CRL approach can increase QoE by over 30%.
N-Critics: Self-Refinement of Large Language Models with Ensemble of Critics
Nov 08, 2023



We propose a self-correction mechanism for Large Language Models (LLMs) to mitigate issues such as toxicity and fact hallucination. This method involves refining model outputs through an ensemble of critics and the model's own feedback. Drawing inspiration from human behavior, we explore whether LLMs can emulate the self-correction process observed in humans who often engage in self-reflection and seek input from others to refine their understanding of complex topics. Our approach is model-agnostic and can be applied across various domains to enhance trustworthiness by addressing fairness, bias, and robustness concerns. We consistently observe performance improvements in LLMs for reducing toxicity and correcting factual errors.
Federated Ensemble-Directed Offline Reinforcement Learning
May 04, 2023



We consider the problem of federated offline reinforcement learning (RL), a scenario under which distributed learning agents must collaboratively learn a high-quality control policy only using small pre-collected datasets generated according to different unknown behavior policies. Naively combining a standard offline RL approach with a standard federated learning approach to solve this problem can lead to poorly performing policies. In response, we develop the Federated Ensemble-Directed Offline Reinforcement Learning Algorithm (FEDORA), which distills the collective wisdom of the clients using an ensemble learning approach. We develop the FEDORA codebase to utilize distributed compute resources on a federated learning platform. We show that FEDORA significantly outperforms other approaches, including offline RL over the combined data pool, in various complex continuous control environments and real world datasets. Finally, we demonstrate the performance of FEDORA in the real-world on a mobile robot.
Enhanced Meta Reinforcement Learning using Demonstrations in Sparse Reward Environments
Sep 26, 2022
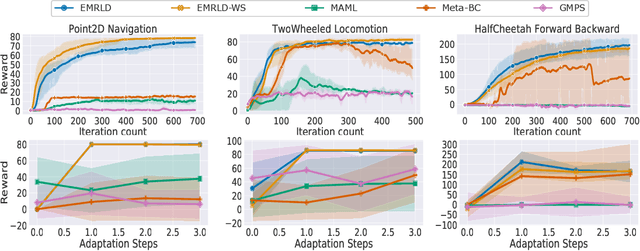
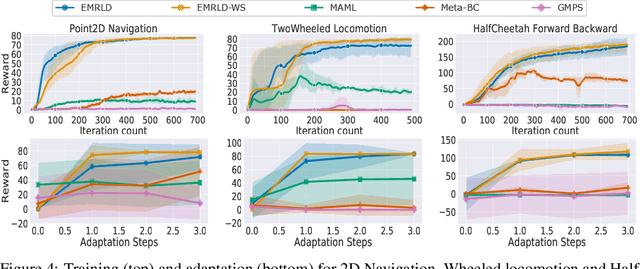
Meta reinforcement learning (Meta-RL) is an approach wherein the experience gained from solving a variety of tasks is distilled into a meta-policy. The meta-policy, when adapted over only a small (or just a single) number of steps, is able to perform near-optimally on a new, related task. However, a major challenge to adopting this approach to solve real-world problems is that they are often associated with sparse reward functions that only indicate whether a task is completed partially or fully. We consider the situation where some data, possibly generated by a sub-optimal agent, is available for each task. We then develop a class of algorithms entitled Enhanced Meta-RL using Demonstrations (EMRLD) that exploit this information even if sub-optimal to obtain guidance during training. We show how EMRLD jointly utilizes RL and supervised learning over the offline data to generate a meta-policy that demonstrates monotone performance improvements. We also develop a warm started variant called EMRLD-WS that is particularly efficient for sub-optimal demonstration data. Finally, we show that our EMRLD algorithms significantly outperform existing approaches in a variety of sparse reward environments, including that of a mobile robot.
Reinforcement Learning with Sparse Rewards using Guidance from Offline Demonstration
Feb 13, 2022



A major challenge in real-world reinforcement learning (RL) is the sparsity of reward feedback. Often, what is available is an intuitive but sparse reward function that only indicates whether the task is completed partially or fully. However, the lack of carefully designed, fine grain feedback implies that most existing RL algorithms fail to learn an acceptable policy in a reasonable time frame. This is because of the large number of exploration actions that the policy has to perform before it gets any useful feedback that it can learn from. In this work, we address this challenging problem by developing an algorithm that exploits the offline demonstration data generated by a sub-optimal behavior policy for faster and efficient online RL in such sparse reward settings. The proposed algorithm, which we call the Learning Online with Guidance Offline (LOGO) algorithm, merges a policy improvement step with an additional policy guidance step by using the offline demonstration data. The key idea is that by obtaining guidance from - not imitating - the offline data, LOGO orients its policy in the manner of the sub-optimal policy, while yet being able to learn beyond and approach optimality. We provide a theoretical analysis of our algorithm, and provide a lower bound on the performance improvement in each learning episode. We also extend our algorithm to the even more challenging incomplete observation setting, where the demonstration data contains only a censored version of the true state observation. We demonstrate the superior performance of our algorithm over state-of-the-art approaches on a number of benchmark environments with sparse rewards and censored state. Further, we demonstrate the value of our approach via implementing LOGO on a mobile robot for trajectory tracking and obstacle avoidance, where it shows excellent performance.
Learning Trembling Hand Perfect Mean Field Equilibrium for Dynamic Mean Field Games
Jun 21, 2020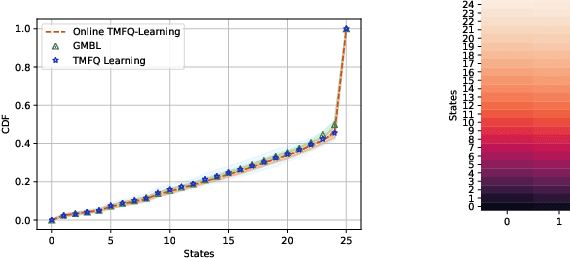
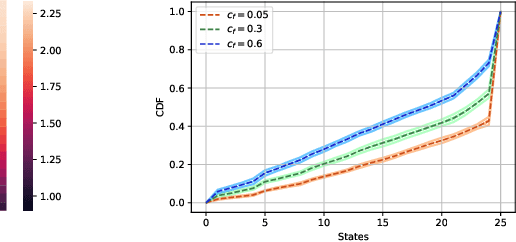
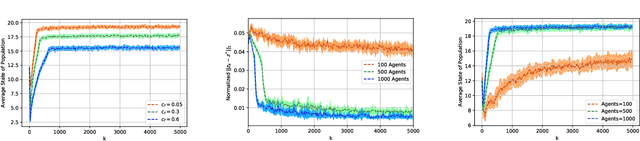
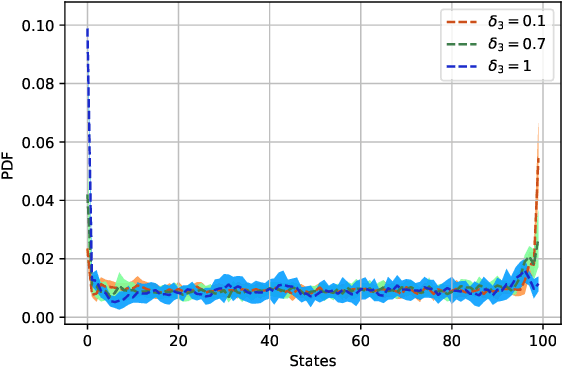
Mean Field Games (MFG) are those in which each agent assumes that the states of all others are drawn in an i.i.d. manner from a common belief distribution, and optimizes accordingly. The equilibrium concept here is a Mean Field Equilibrium (MFE), and algorithms for learning MFE in dynamic MFGs are unknown in general due to the non-stationary evolution of the belief distribution. Our focus is on an important subclass that possess a monotonicity property called Strategic Complementarities (MFG-SC). We introduce a natural refinement to the equilibrium concept that we call Trembling-Hand-Perfect MFE (T-MFE), which allows agents to employ a measure of randomization while accounting for the impact of such randomization on their payoffs. We propose a simple algorithm for computing T-MFE under a known model. We introduce both a model-free and a model based approach to learning T-MFE under unknown transition probabilities, using the trembling-hand idea of enabling exploration. We analyze the sample complexity of both algorithms. We also develop a scheme on concurrently sampling the system with a large number of agents that negates the need for a simulator, even though the model is non-stationary. Finally, we empirically evaluate the performance of the proposed algorithms via examples motivated by real-world applications.
QFlow: A Reinforcement Learning Approach to High QoE Video Streaming over Wireless Networks
Jan 04, 2019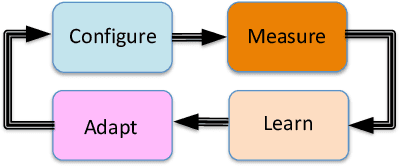
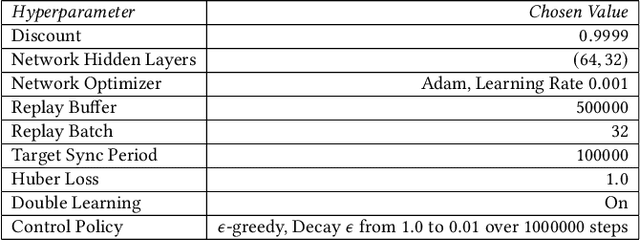
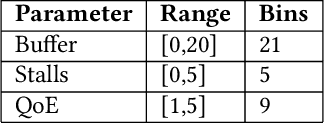

Wireless Internet access has brought legions of heterogeneous applications all sharing the same resources. However, current wireless edge networks that cater to worst or average case performance lack the agility to best serve these diverse sessions. Simultaneously, software reconfigurable infrastructure has become increasingly mainstream to the point that dynamic per packet and per flow decisions are possible at multiple layers of the communications stack. Exploiting such reconfigurability requires the design of a system that can enable a configuration, measure the impact on the application performance (Quality of Experience), and adaptively select a new configuration. Effectively, this feedback loop is a Markov Decision Process whose parameters are unknown. The goal of this work is to design, develop and demonstrate QFlow that instantiates this feedback loop as an application of reinforcement learning (RL). Our context is that of reconfigurable (priority) queueing, and we use the popular application of video streaming as our use case. We develop both model-free and model-based RL approaches that are tailored to the problem of determining which clients should be assigned to which queue at each decision period. Through experimental validation, we show how the RL-based control policies on QFlow are able to schedule the right clients for prioritization in a high-load scenario to outperform the status quo, as well as the best known solutions with over 25% improvement in QoE, and a perfect QoE score of 5 over 85% of the time.