 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReshaping Viscoelastic-String Path-Planner (RVP)
Mar 02, 2023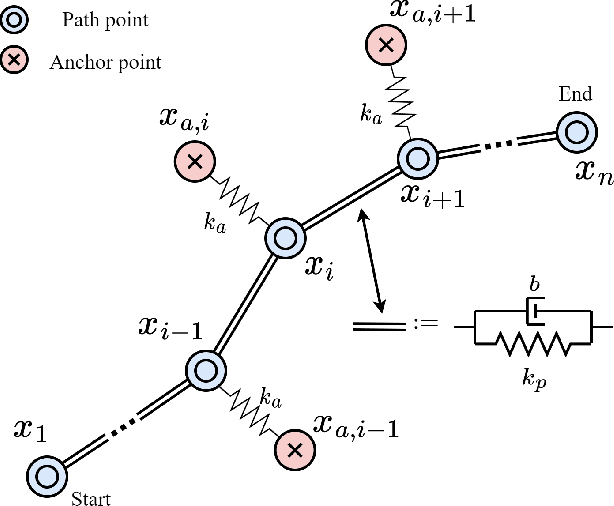
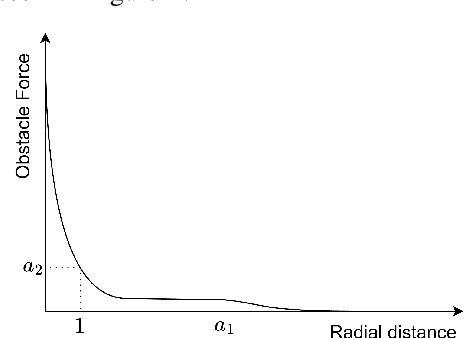


We present Reshaping Viscoelastic-String Path-Planner a Path Planner that reshapes a desired Global Plan for a Robotic Vehicle based on sensor observations of the Environment. We model the path to be a viscoelastic string with shape preserving tendencies, approximated by a connected series of Springs, Masses, and Dampers. The resultant path is then reshaped according to the forces emanating from the obstacles until an equilibrium is reached. The reshaped path remains close in shape to the original path because of Anchor Points that connect to the discrete masses through springs. The final path is the resultant equilibrium configuration of the Spring-Mass-Damper network. Two key concepts enable RVP (i) Virtual Obstacle Forces that push the Spring-Mass-Damper system away from the original path and (ii) Anchor points in conjunction with the Spring-Mass-Damper network that attempts to retain the path shape. We demonstrate the results in simulation and compare it's performance with an existing Reshaping Local Planner that also takes a Global Plan and reshapes it according to sensor based observations of the environment.
Reinforcement Learning with Sparse Rewards using Guidance from Offline Demonstration
Feb 13, 2022



A major challenge in real-world reinforcement learning (RL) is the sparsity of reward feedback. Often, what is available is an intuitive but sparse reward function that only indicates whether the task is completed partially or fully. However, the lack of carefully designed, fine grain feedback implies that most existing RL algorithms fail to learn an acceptable policy in a reasonable time frame. This is because of the large number of exploration actions that the policy has to perform before it gets any useful feedback that it can learn from. In this work, we address this challenging problem by developing an algorithm that exploits the offline demonstration data generated by a sub-optimal behavior policy for faster and efficient online RL in such sparse reward settings. The proposed algorithm, which we call the Learning Online with Guidance Offline (LOGO) algorithm, merges a policy improvement step with an additional policy guidance step by using the offline demonstration data. The key idea is that by obtaining guidance from - not imitating - the offline data, LOGO orients its policy in the manner of the sub-optimal policy, while yet being able to learn beyond and approach optimality. We provide a theoretical analysis of our algorithm, and provide a lower bound on the performance improvement in each learning episode. We also extend our algorithm to the even more challenging incomplete observation setting, where the demonstration data contains only a censored version of the true state observation. We demonstrate the superior performance of our algorithm over state-of-the-art approaches on a number of benchmark environments with sparse rewards and censored state. Further, we demonstrate the value of our approach via implementing LOGO on a mobile robot for trajectory tracking and obstacle avoidance, where it shows excellent performance.