 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Boundaries: Leveraging Vision Foundation Models for Source-Free Object Detection
Nov 10, 2025Source-Free Object Detection (SFOD) aims to adapt a source-pretrained object detector to a target domain without access to source data. However, existing SFOD methods predominantly rely on internal knowledge from the source model, which limits their capacity to generalize across domains and often results in biased pseudo-labels, thereby hindering both transferability and discriminability. In contrast, Vision Foundation Models (VFMs), pretrained on massive and diverse data, exhibit strong perception capabilities and broad generalization, yet their potential remains largely untapped in the SFOD setting. In this paper, we propose a novel SFOD framework that leverages VFMs as external knowledge sources to jointly enhance feature alignment and label quality. Specifically, we design three VFM-based modules: (1) Patch-weighted Global Feature Alignment (PGFA) distills global features from VFMs using patch-similarity-based weighting to enhance global feature transferability; (2) Prototype-based Instance Feature Alignment (PIFA) performs instance-level contrastive learning guided by momentum-updated VFM prototypes; and (3) Dual-source Enhanced Pseudo-label Fusion (DEPF) fuses predictions from detection VFMs and teacher models via an entropy-aware strategy to yield more reliable supervision. Extensive experiments on six benchmarks demonstrate that our method achieves state-of-the-art SFOD performance, validating the effectiveness of integrating VFMs to simultaneously improve transferability and discriminability.
Tests as Prompt: A Test-Driven-Development Benchmark for LLM Code Generation
May 13, 2025We introduce WebApp1K, a novel benchmark for evaluating large language models (LLMs) in test-driven development (TDD) tasks, where test cases serve as both prompt and verification for code generation. Unlike traditional approaches relying on natural language prompts, our benchmark emphasizes the ability of LLMs to interpret and implement functionality directly from test cases, reflecting real-world software development practices. Comprising 1000 diverse challenges across 20 application domains, the benchmark evaluates LLMs on their ability to generate compact, functional code under the constraints of context length and multi-feature complexity. Our findings highlight instruction following and in-context learning as critical capabilities for TDD success, surpassing the importance of general coding proficiency or pretraining knowledge. Through comprehensive evaluation of 19 frontier models, we reveal performance bottlenecks, such as instruction loss in long prompts, and provide a detailed error analysis spanning multiple root causes. This work underscores the practical value of TDD-specific benchmarks and lays the foundation for advancing LLM capabilities in rigorous, application-driven coding scenarios.
MUFM: A Mamba-Enhanced Feedback Model for Micro Video Popularity Prediction
Nov 23, 2024



The surge in micro-videos is transforming the concept of popularity. As researchers delve into vast multi-modal datasets, there is a growing interest in understanding the origins of this popularity and the forces driving its rapid expansion. Recent studies suggest that the virality of short videos is not only tied to their inherent multi-modal content but is also heavily influenced by the strength of platform recommendations driven by audience feedback. In this paper, we introduce a framework for capturing long-term dependencies in user feedback and dynamic event interactions, based on the Mamba Hawkes process. Our experiments on the large-scale open-source multi-modal dataset show that our model significantly outperforms state-of-the-art approaches across various metrics by 23.2%. We believe our model's capability to map the relationships within user feedback behavior sequences will not only contribute to the evolution of next-generation recommendation algorithms and platform applications but also enhance our understanding of micro video dissemination and its broader societal impact.
Insights from Benchmarking Frontier Language Models on Web App Code Generation
Sep 08, 2024This paper presents insights from evaluating 16 frontier large language models (LLMs) on the WebApp1K benchmark, a test suite designed to assess the ability of LLMs to generate web application code. The results reveal that while all models possess similar underlying knowledge, their performance is differentiated by the frequency of mistakes they make. By analyzing lines of code (LOC) and failure distributions, we find that writing correct code is more complex than generating incorrect code. Furthermore, prompt engineering shows limited efficacy in reducing errors beyond specific cases. These findings suggest that further advancements in coding LLM should emphasize on model reliability and mistake minimization.
WebApp1K: A Practical Code-Generation Benchmark for Web App Development
Jul 30, 2024



We introduce WebApp1K, a practical code-generation benchmark to measure LLM ability to develop web apps. This benchmark aims to calibrate LLM output and aid the models to progressively improve code correctness and functionality. The benchmark is lightweight and easy to run. We present the initial version of WebApp1K, and share our findings of running the benchmark against the latest frontier LLMs. First, open source LLMs deliver impressive performance, closely trailing behind GPT-4o and Claude 3.5. Second, model size has strong correlation with code correctness. Third, no prompting techniques have been found to lift performance either universally to all models, or significantly to a single model.
Energy System Digitization in the Era of AI: A Three-Layered Approach towards Carbon Neutrality
Nov 02, 2022The transition towards carbon-neutral electricity is one of the biggest game changers in addressing climate change since it addresses the dual challenges of removing carbon emissions from the two largest sectors of emitters: electricity and transportation. The transition to a carbon-neutral electric grid poses significant challenges to conventional paradigms of modern grid planning and operation. Much of the challenge arises from the scale of the decision making and the uncertainty associated with the energy supply and demand. Artificial Intelligence (AI) could potentially have a transformative impact on accelerating the speed and scale of carbon-neutral transition, as many decision making processes in the power grid can be cast as classic, though challenging, machine learning tasks. We point out that to amplify AI's impact on carbon-neutral transition of the electric energy systems, the AI algorithms originally developed for other applications should be tailored in three layers of technology, markets, and policy.
Region of Interest Detection in Melanocytic Skin Tumor Whole Slide Images
Oct 29, 2022Automated region of interest detection in histopathological image analysis is a challenging and important topic with tremendous potential impact on clinical practice. The deep-learning methods used in computational pathology help us to reduce costs and increase the speed and accuracy of regions of interest detection and cancer diagnosis. In this work, we propose a patch-based region of interest detection method for melanocytic skin tumor whole-slide images. We work with a dataset that contains 165 primary melanomas and nevi Hematoxylin and Eosin whole-slide images and build a deep-learning method. The proposed method performs well on a hold-out test data set including five TCGA-SKCM slides (accuracy of 93.94\% in slide classification task and intersection over union rate of 41.27\% in the region of interest detection task), showing the outstanding performance of our model on melanocytic skin tumor. Even though we test the experiments on the skin tumor dataset, our work could also be extended to other medical image detection problems, such as various tumors' classification and prediction, to help and benefit the clinical evaluation and diagnosis of different tumors.
Using EBGAN for Anomaly Intrusion Detection
Jun 21, 2022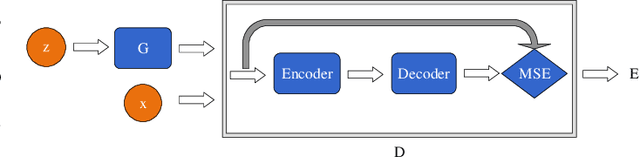
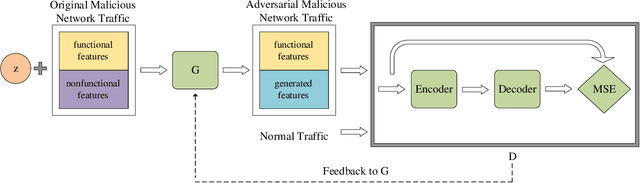
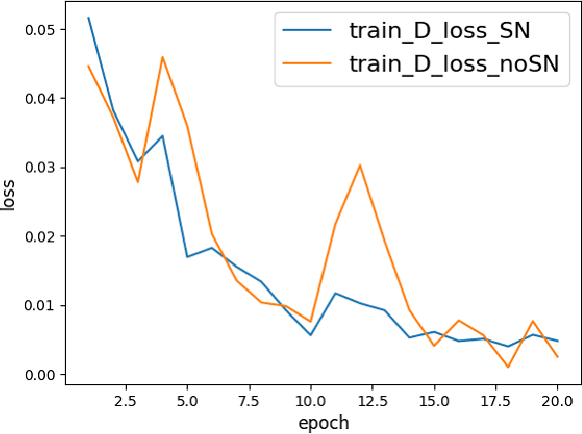
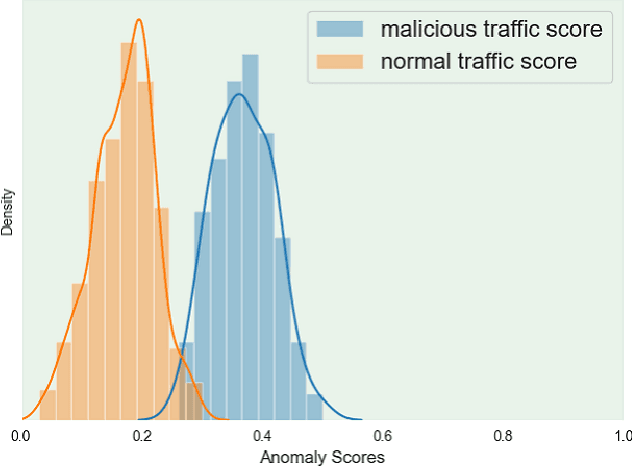
As an active network security protection scheme, intrusion detection system (IDS) undertakes the important responsibility of detecting network attacks in the form of malicious network traffic. Intrusion detection technology is an important part of IDS. At present, many scholars have carried out extensive research on intrusion detection technology. However, developing an efficient intrusion detection method for massive network traffic data is still difficult. Since Generative Adversarial Networks (GANs) have powerful modeling capabilities for complex high-dimensional data, they provide new ideas for addressing this problem. In this paper, we put forward an EBGAN-based intrusion detection method, IDS-EBGAN, that classifies network records as normal traffic or malicious traffic. The generator in IDS-EBGAN is responsible for converting the original malicious network traffic in the training set into adversarial malicious examples. This is because we want to use adversarial learning to improve the ability of discriminator to detect malicious traffic. At the same time, the discriminator adopts Autoencoder model. During testing, IDS-EBGAN uses reconstruction error of discriminator to classify traffic records.