 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrade-R1: Bridging Verifiable Rewards to Stochastic Environments via Process-Level Reasoning Verification
Jan 08, 2026Reinforcement Learning (RL) has enabled Large Language Models (LLMs) to achieve remarkable reasoning in domains like mathematics and coding, where verifiable rewards provide clear signals. However, extending this paradigm to financial decision is challenged by the market's stochastic nature: rewards are verifiable but inherently noisy, causing standard RL to degenerate into reward hacking. To address this, we propose Trade-R1, a model training framework that bridges verifiable rewards to stochastic environments via process-level reasoning verification. Our key innovation is a verification method that transforms the problem of evaluating reasoning over lengthy financial documents into a structured Retrieval-Augmented Generation (RAG) task. We construct a triangular consistency metric, assessing pairwise alignment between retrieved evidence, reasoning chains, and decisions to serve as a validity filter for noisy market returns. We explore two reward integration strategies: Fixed-effect Semantic Reward (FSR) for stable alignment signals, and Dynamic-effect Semantic Reward (DSR) for coupled magnitude optimization. Experiments on different country asset selection demonstrate that our paradigm reduces reward hacking, with DSR achieving superior cross-market generalization while maintaining the highest reasoning consistency.
Alpha-R1: Alpha Screening with LLM Reasoning via Reinforcement Learning
Dec 29, 2025Signal decay and regime shifts pose recurring challenges for data-driven investment strategies in non-stationary markets. Conventional time-series and machine learning approaches, which rely primarily on historical correlations, often struggle to generalize when the economic environment changes. While large language models (LLMs) offer strong capabilities for processing unstructured information, their potential to support quantitative factor screening through explicit economic reasoning remains underexplored. Existing factor-based methods typically reduce alphas to numerical time series, overlooking the semantic rationale that determines when a factor is economically relevant. We propose Alpha-R1, an 8B-parameter reasoning model trained via reinforcement learning for context-aware alpha screening. Alpha-R1 reasons over factor logic and real-time news to evaluate alpha relevance under changing market conditions, selectively activating or deactivating factors based on contextual consistency. Empirical results across multiple asset pools show that Alpha-R1 consistently outperforms benchmark strategies and exhibits improved robustness to alpha decay. The full implementation and resources are available at https://github.com/FinStep-AI/Alpha-R1.
SPOT: Scalable Policy Optimization with Trees for Markov Decision Processes
Oct 22, 2025



Interpretable reinforcement learning policies are essential for high-stakes decision-making, yet optimizing decision tree policies in Markov Decision Processes (MDPs) remains challenging. We propose SPOT, a novel method for computing decision tree policies, which formulates the optimization problem as a mixed-integer linear program (MILP). To enhance efficiency, we employ a reduced-space branch-and-bound approach that decouples the MDP dynamics from tree-structure constraints, enabling efficient parallel search. This significantly improves runtime and scalability compared to previous methods. Our approach ensures that each iteration yields the optimal decision tree. Experimental results on standard benchmarks demonstrate that SPOT achieves substantial speedup and scales to larger MDPs with a significantly higher number of states. The resulting decision tree policies are interpretable and compact, maintaining transparency without compromising performance. These results demonstrate that our approach simultaneously achieves interpretability and scalability, delivering high-quality policies an order of magnitude faster than existing approaches.
Spectral Mixture Kernels for Bayesian Optimization
May 23, 2025Bayesian Optimization (BO) is a widely used approach for solving expensive black-box optimization tasks. However, selecting an appropriate probabilistic surrogate model remains an important yet challenging problem. In this work, we introduce a novel Gaussian Process (GP)-based BO method that incorporates spectral mixture kernels, derived from spectral densities formed by scale-location mixtures of Cauchy and Gaussian distributions. This method achieves a significant improvement in both efficiency and optimization performance, matching the computational speed of simpler kernels while delivering results that outperform more complex models and automatic BO methods. We provide bounds on the information gain and cumulative regret associated with obtaining the optimum. Extensive numerical experiments demonstrate that our method consistently outperforms existing baselines across a diverse range of synthetic and real-world problems, including both low- and high-dimensional settings.
Reinforcement-Learning Portfolio Allocation with Dynamic Embedding of Market Information
Jan 29, 2025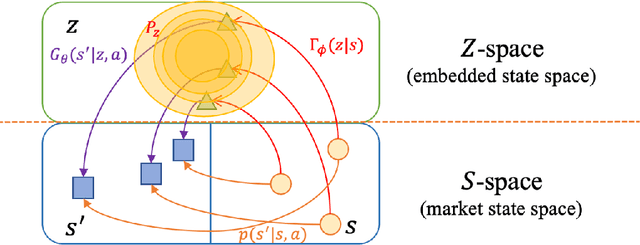
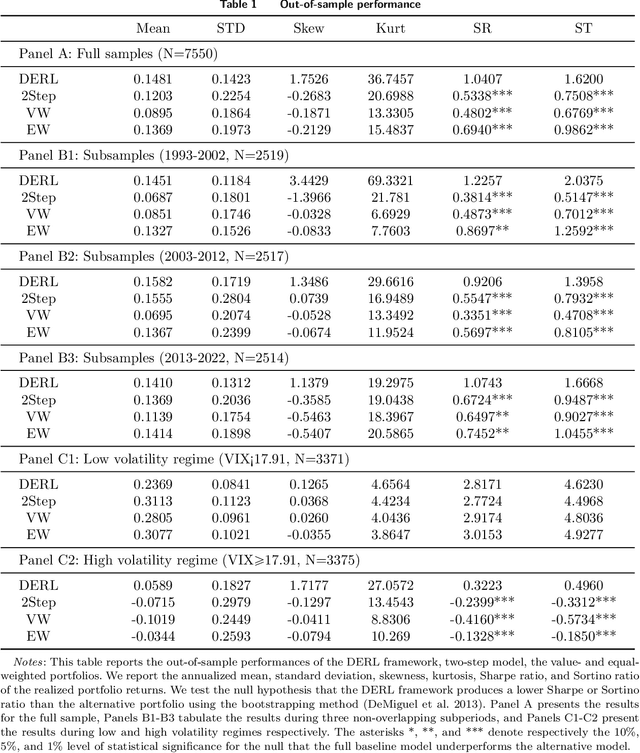
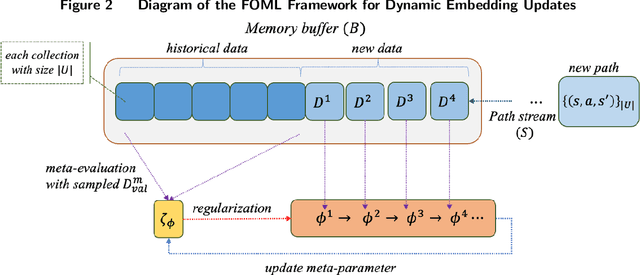
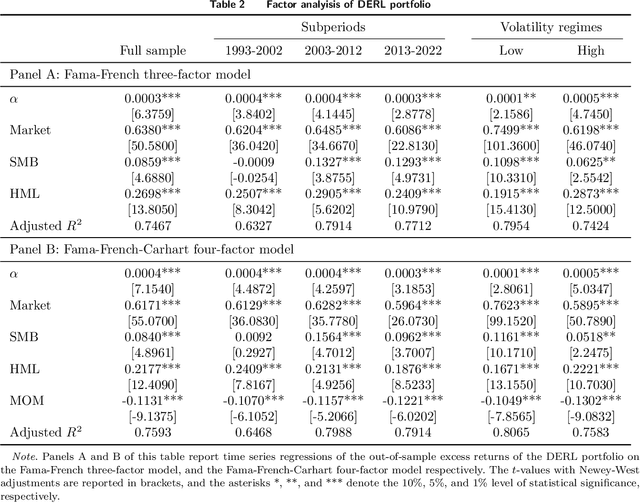
We develop a portfolio allocation framework that leverages deep learning techniques to address challenges arising from high-dimensional, non-stationary, and low-signal-to-noise market information. Our approach includes a dynamic embedding method that reduces the non-stationary, high-dimensional state space into a lower-dimensional representation. We design a reinforcement learning (RL) framework that integrates generative autoencoders and online meta-learning to dynamically embed market information, enabling the RL agent to focus on the most impactful parts of the state space for portfolio allocation decisions. Empirical analysis based on the top 500 U.S. stocks demonstrates that our framework outperforms common portfolio benchmarks and the predict-then-optimize (PTO) approach using machine learning, particularly during periods of market stress. Traditional factor models do not fully explain this superior performance. The framework's ability to time volatility reduces its market exposure during turbulent times. Ablation studies confirm the robustness of this performance across various reinforcement learning algorithms. Additionally, the embedding and meta-learning techniques effectively manage the complexities of high-dimensional, noisy, and non-stationary financial data, enhancing both portfolio performance and risk management.
MUFM: A Mamba-Enhanced Feedback Model for Micro Video Popularity Prediction
Nov 23, 2024



The surge in micro-videos is transforming the concept of popularity. As researchers delve into vast multi-modal datasets, there is a growing interest in understanding the origins of this popularity and the forces driving its rapid expansion. Recent studies suggest that the virality of short videos is not only tied to their inherent multi-modal content but is also heavily influenced by the strength of platform recommendations driven by audience feedback. In this paper, we introduce a framework for capturing long-term dependencies in user feedback and dynamic event interactions, based on the Mamba Hawkes process. Our experiments on the large-scale open-source multi-modal dataset show that our model significantly outperforms state-of-the-art approaches across various metrics by 23.2%. We believe our model's capability to map the relationships within user feedback behavior sequences will not only contribute to the evolution of next-generation recommendation algorithms and platform applications but also enhance our understanding of micro video dissemination and its broader societal impact.
Collaborative Intelligence in Sequential Experiments: A Human-in-the-Loop Framework for Drug Discovery
May 07, 2024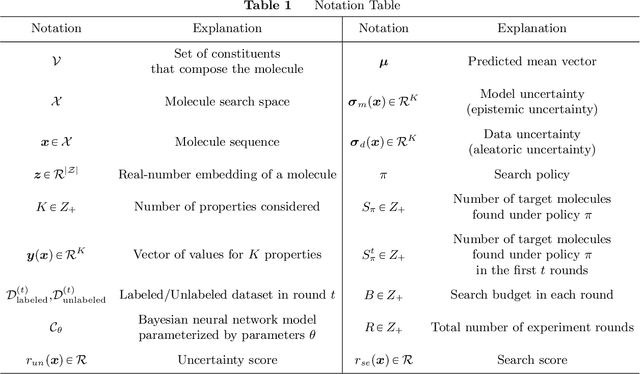
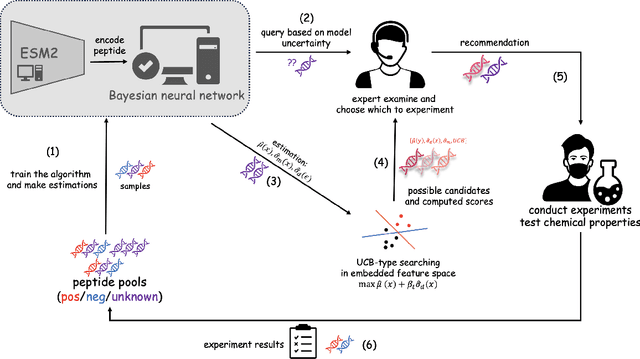
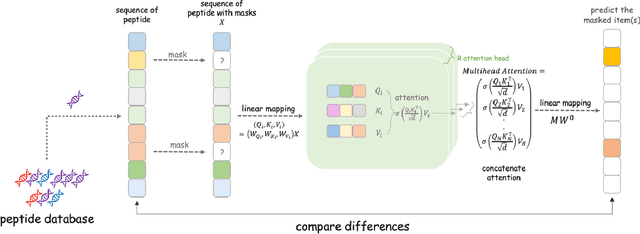
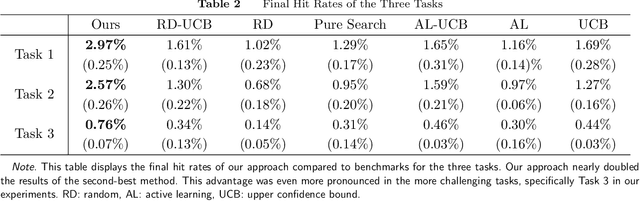
Drug discovery is a complex process that involves sequentially screening and examining a vast array of molecules to identify those with the target properties. This process, also referred to as sequential experimentation, faces challenges due to the vast search space, the rarity of target molecules, and constraints imposed by limited data and experimental budgets. To address these challenges, we introduce a human-in-the-loop framework for sequential experiments in drug discovery. This collaborative approach combines human expert knowledge with deep learning algorithms, enhancing the discovery of target molecules within a specified experimental budget. The proposed algorithm processes experimental data to recommend both promising molecules and those that could improve its performance to human experts. Human experts retain the final decision-making authority based on these recommendations and their domain expertise, including the ability to override algorithmic recommendations. We applied our method to drug discovery tasks using real-world data and found that it consistently outperforms all baseline methods, including those which rely solely on human or algorithmic input. This demonstrates the complementarity between human experts and the algorithm. Our results provide key insights into the levels of humans' domain knowledge, the importance of meta-knowledge, and effective work delegation strategies. Our findings suggest that such a framework can significantly accelerate the development of new vaccines and drugs by leveraging the best of both human and artificial intelligence.
Optimal Dispatch in Emergency Service System via Reinforcement Learning
Oct 15, 2020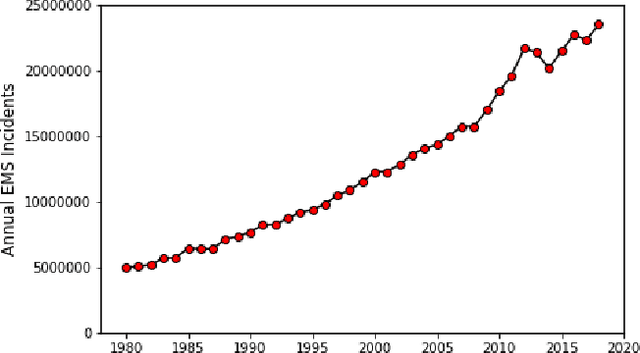
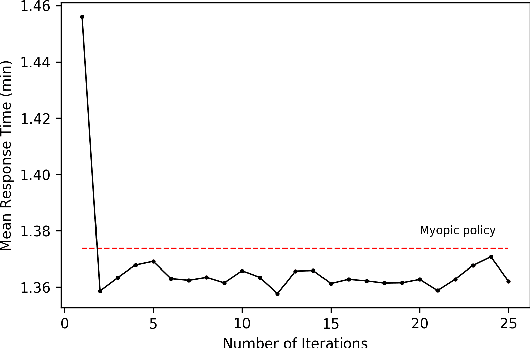
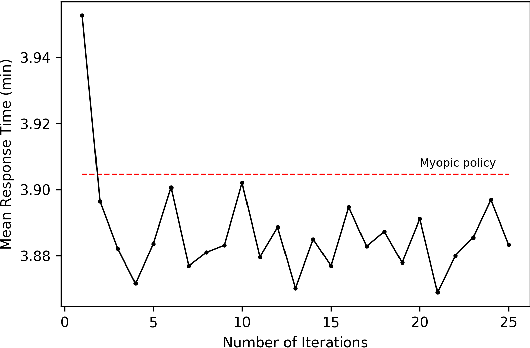
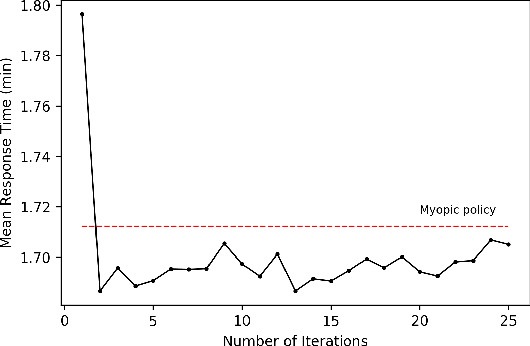
In the United States, medical responses by fire departments over the last four decades increased by 367%. This had made it critical to decision makers in emergency response departments that existing resources are efficiently used. In this paper, we model the ambulance dispatch problem as an average-cost Markov decision process and present a policy iteration approach to find an optimal dispatch policy. We then propose an alternative formulation using post-decision states that is shown to be mathematically equivalent to the original model, but with a much smaller state space. We present a temporal difference learning approach to the dispatch problem based on the post-decision states. In our numerical experiments, we show that our obtained temporal-difference policy outperforms the benchmark myopic policy. Our findings suggest that emergency response departments can improve their performance with minimal to no cost.