 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Augmented Digital Twin for Policy Evaluation in Short-Video Platforms
Mar 11, 2026Short-video platforms are closed-loop, human-in-the-loop ecosystems where platform policy, creator incentives, and user behavior co-evolve. This feedback structure makes counterfactual policy evaluation difficult in production, especially for long-horizon and distributional outcomes. The challenge is amplified as platforms deploy AI tools that change what content enters the system, how agents adapt, and how the platform operates. We propose a large language model (LLM)-augmented digital twin for short-video platforms, with a modular four-twin architecture (User, Content, Interaction, Platform) and an event-driven execution layer that supports reproducible experimentation. Platform policies are implemented as pluggable components within the Platform Twin, and LLMs are integrated as optional, schema-constrained decision services (e.g., persona generation, content captioning, campaign planning, trend prediction) that are routed through a unified optimizer. This design enables scalable simulations that preserve closed-loop dynamics while allowing selective LLM adoption, enabling the study of platform policies, including AI-enabled policies, under realistic feedback and constraints.
Reinforcement-Learning Portfolio Allocation with Dynamic Embedding of Market Information
Jan 29, 2025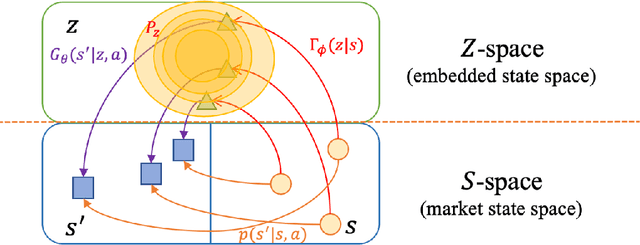
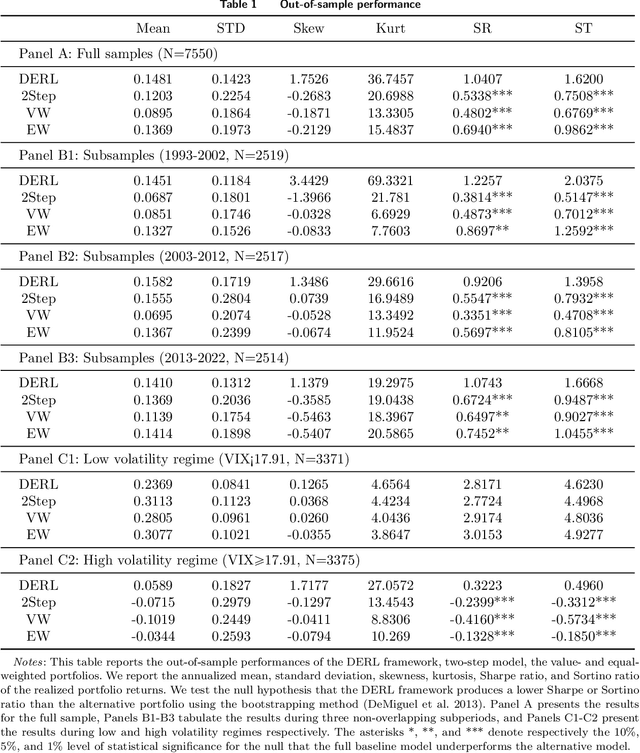
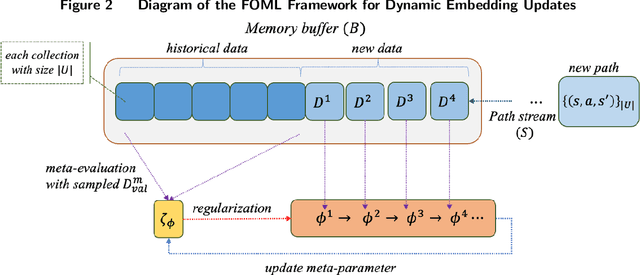
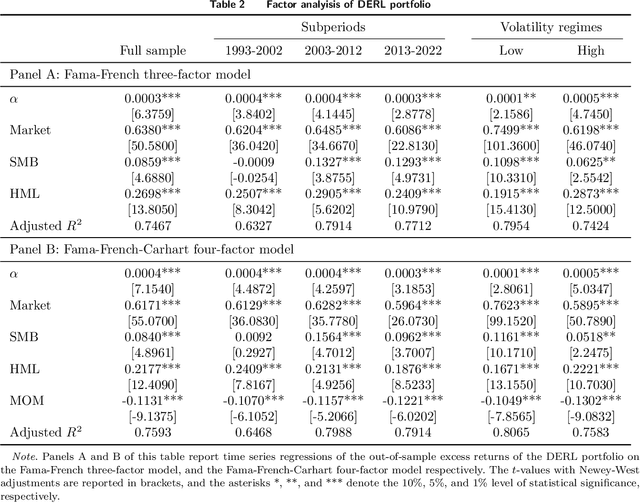
We develop a portfolio allocation framework that leverages deep learning techniques to address challenges arising from high-dimensional, non-stationary, and low-signal-to-noise market information. Our approach includes a dynamic embedding method that reduces the non-stationary, high-dimensional state space into a lower-dimensional representation. We design a reinforcement learning (RL) framework that integrates generative autoencoders and online meta-learning to dynamically embed market information, enabling the RL agent to focus on the most impactful parts of the state space for portfolio allocation decisions. Empirical analysis based on the top 500 U.S. stocks demonstrates that our framework outperforms common portfolio benchmarks and the predict-then-optimize (PTO) approach using machine learning, particularly during periods of market stress. Traditional factor models do not fully explain this superior performance. The framework's ability to time volatility reduces its market exposure during turbulent times. Ablation studies confirm the robustness of this performance across various reinforcement learning algorithms. Additionally, the embedding and meta-learning techniques effectively manage the complexities of high-dimensional, noisy, and non-stationary financial data, enhancing both portfolio performance and risk management.
Daily Physical Activity Monitoring -- Adaptive Learning from Multi-source Motion Sensor Data
May 26, 2024



In healthcare applications, there is a growing need to develop machine learning models that use data from a single source, such as that from a wrist wearable device, to monitor physical activities, assess health risks, and provide immediate health recommendations or interventions. However, the limitation of using single-source data often compromises the model's accuracy, as it fails to capture the full scope of human activities. While a more comprehensive dataset can be gathered in a lab setting using multiple sensors attached to various body parts, this approach is not practical for everyday use due to the impracticality of wearing multiple sensors. To address this challenge, we introduce a transfer learning framework that optimizes machine learning models for everyday applications by leveraging multi-source data collected in a laboratory setting. We introduce a novel metric to leverage the inherent relationship between these multiple data sources, as they are all paired to capture aspects of the same physical activity. Through numerical experiments, our framework outperforms existing methods in classification accuracy and robustness to noise, offering a promising avenue for the enhancement of daily activity monitoring.
Collaborative Intelligence in Sequential Experiments: A Human-in-the-Loop Framework for Drug Discovery
May 07, 2024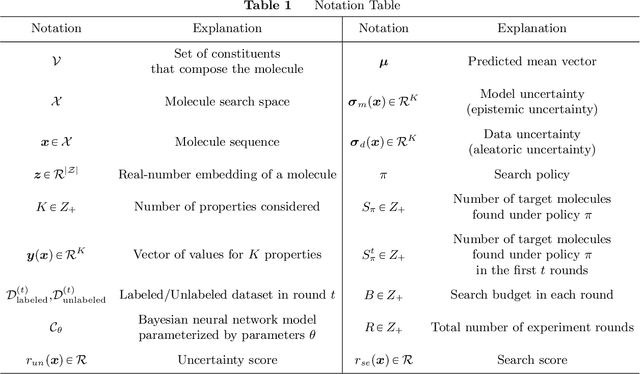
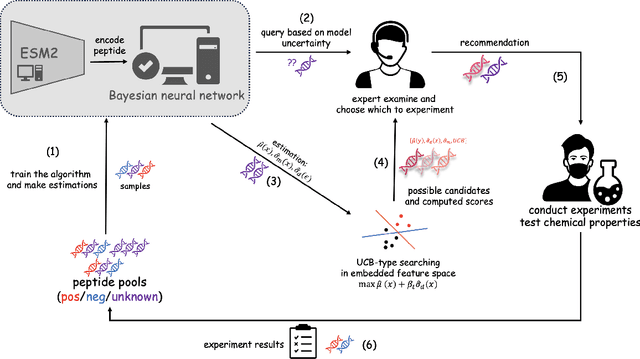
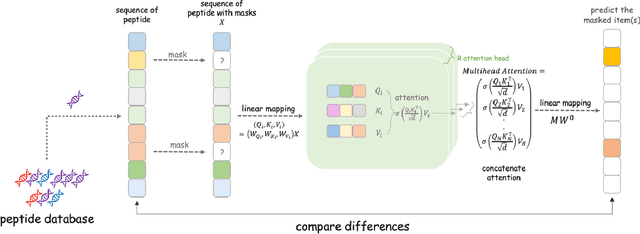
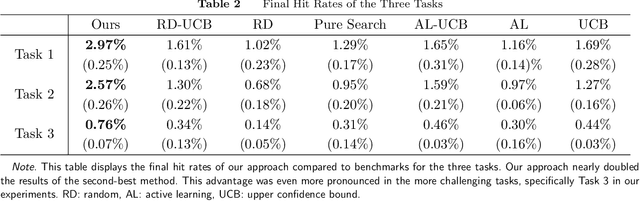
Drug discovery is a complex process that involves sequentially screening and examining a vast array of molecules to identify those with the target properties. This process, also referred to as sequential experimentation, faces challenges due to the vast search space, the rarity of target molecules, and constraints imposed by limited data and experimental budgets. To address these challenges, we introduce a human-in-the-loop framework for sequential experiments in drug discovery. This collaborative approach combines human expert knowledge with deep learning algorithms, enhancing the discovery of target molecules within a specified experimental budget. The proposed algorithm processes experimental data to recommend both promising molecules and those that could improve its performance to human experts. Human experts retain the final decision-making authority based on these recommendations and their domain expertise, including the ability to override algorithmic recommendations. We applied our method to drug discovery tasks using real-world data and found that it consistently outperforms all baseline methods, including those which rely solely on human or algorithmic input. This demonstrates the complementarity between human experts and the algorithm. Our results provide key insights into the levels of humans' domain knowledge, the importance of meta-knowledge, and effective work delegation strategies. Our findings suggest that such a framework can significantly accelerate the development of new vaccines and drugs by leveraging the best of both human and artificial intelligence.
Language Model Prompt Selection via Simulation Optimization
Apr 12, 2024With the advancement in generative language models, the selection of prompts has gained significant attention in recent years. A prompt is an instruction or description provided by the user, serving as a guide for the generative language model in content generation. Despite existing methods for prompt selection that are based on human labor, we consider facilitating this selection through simulation optimization, aiming to maximize a pre-defined score for the selected prompt. Specifically, we propose a two-stage framework. In the first stage, we determine a feasible set of prompts in sufficient numbers, where each prompt is represented by a moderate-dimensional vector. In the subsequent stage for evaluation and selection, we construct a surrogate model of the score regarding the moderate-dimensional vectors that represent the prompts. We propose sequentially selecting the prompt for evaluation based on this constructed surrogate model. We prove the consistency of the sequential evaluation procedure in our framework. We also conduct numerical experiments to demonstrate the efficacy of our proposed framework, providing practical instructions for implementation.
Causal inference with Machine Learning-Based Covariate Representation
Nov 03, 2023Utilizing covariate information has been a powerful approach to improve the efficiency and accuracy for causal inference, which support massive amount of randomized experiments run on data-driven enterprises. However, state-of-art approaches can become practically unreliable when the dimension of covariate increases to just 50, whereas experiments on large platforms can observe even higher dimension of covariate. We propose a machine-learning-assisted covariate representation approach that can effectively make use of historical experiment or observational data that are run on the same platform to understand which lower dimensions can effectively represent the higher-dimensional covariate. We then propose design and estimation methods with the covariate representation. We prove statistically reliability and performance guarantees for the proposed methods. The empirical performance is demonstrated using numerical experiments.