 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Assisted Logic Rule Learning: Scaling Human Expertise for Time Series Anomaly Detection
Jan 27, 2026Time series anomaly detection is critical for supply chain management to take proactive operations, but faces challenges: classical unsupervised anomaly detection based on exploiting data patterns often yields results misaligned with business requirements and domain knowledge, while manual expert analysis cannot scale to millions of products in the supply chain. We propose a framework that leverages large language models (LLMs) to systematically encode human expertise into interpretable, logic-based rules for detecting anomaly patterns in supply chain time series data. Our approach operates in three stages: 1) LLM-based labeling of training data instructed by domain knowledge, 2) automated generation and iterative improvements of symbolic rules through LLM-driven optimization, and 3) rule augmentation with business-relevant anomaly categories supported by LLMs to enhance interpretability. The experiment results showcase that our approach outperforms the unsupervised learning methods in both detection accuracy and interpretability. Furthermore, compared to direct LLM deployment for time series anomaly detection, our approach provides consistent, deterministic results with low computational latency and cost, making it ideal for production deployment. The proposed framework thus demonstrates how LLMs can bridge the gap between scalable automation and expert-driven decision-making in operational settings.
Collaborative Bayesian Optimization via Wasserstein Barycenters
Apr 15, 2025



Motivated by the growing need for black-box optimization and data privacy, we introduce a collaborative Bayesian optimization (BO) framework that addresses both of these challenges. In this framework agents work collaboratively to optimize a function they only have oracle access to. In order to mitigate against communication and privacy constraints, agents are not allowed to share their data but can share their Gaussian process (GP) surrogate models. To enable collaboration under these constraints, we construct a central model to approximate the objective function by leveraging the concept of Wasserstein barycenters of GPs. This central model integrates the shared models without accessing the underlying data. A key aspect of our approach is a collaborative acquisition function that balances exploration and exploitation, allowing for the optimization of decision variables collaboratively in each iteration. We prove that our proposed algorithm is asymptotically consistent and that its implementation via Monte Carlo methods is numerically accurate. Through numerical experiments, we demonstrate that our approach outperforms other baseline collaborative frameworks and is competitive with centralized approaches that do not consider data privacy.
Daily Physical Activity Monitoring -- Adaptive Learning from Multi-source Motion Sensor Data
May 26, 2024



In healthcare applications, there is a growing need to develop machine learning models that use data from a single source, such as that from a wrist wearable device, to monitor physical activities, assess health risks, and provide immediate health recommendations or interventions. However, the limitation of using single-source data often compromises the model's accuracy, as it fails to capture the full scope of human activities. While a more comprehensive dataset can be gathered in a lab setting using multiple sensors attached to various body parts, this approach is not practical for everyday use due to the impracticality of wearing multiple sensors. To address this challenge, we introduce a transfer learning framework that optimizes machine learning models for everyday applications by leveraging multi-source data collected in a laboratory setting. We introduce a novel metric to leverage the inherent relationship between these multiple data sources, as they are all paired to capture aspects of the same physical activity. Through numerical experiments, our framework outperforms existing methods in classification accuracy and robustness to noise, offering a promising avenue for the enhancement of daily activity monitoring.
Language Model Prompt Selection via Simulation Optimization
Apr 12, 2024With the advancement in generative language models, the selection of prompts has gained significant attention in recent years. A prompt is an instruction or description provided by the user, serving as a guide for the generative language model in content generation. Despite existing methods for prompt selection that are based on human labor, we consider facilitating this selection through simulation optimization, aiming to maximize a pre-defined score for the selected prompt. Specifically, we propose a two-stage framework. In the first stage, we determine a feasible set of prompts in sufficient numbers, where each prompt is represented by a moderate-dimensional vector. In the subsequent stage for evaluation and selection, we construct a surrogate model of the score regarding the moderate-dimensional vectors that represent the prompts. We propose sequentially selecting the prompt for evaluation based on this constructed surrogate model. We prove the consistency of the sequential evaluation procedure in our framework. We also conduct numerical experiments to demonstrate the efficacy of our proposed framework, providing practical instructions for implementation.
Multi-Facet Clustering Variational Autoencoders
Jun 09, 2021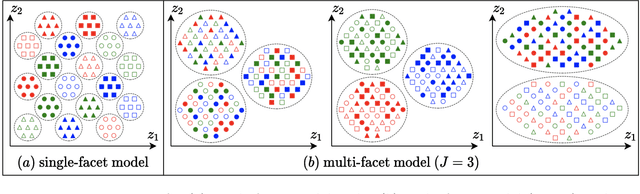
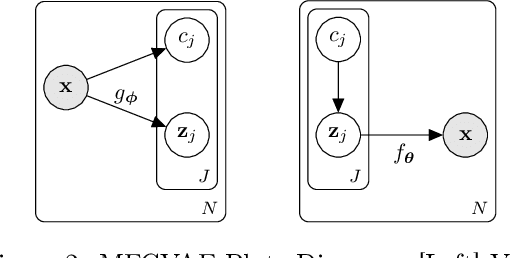

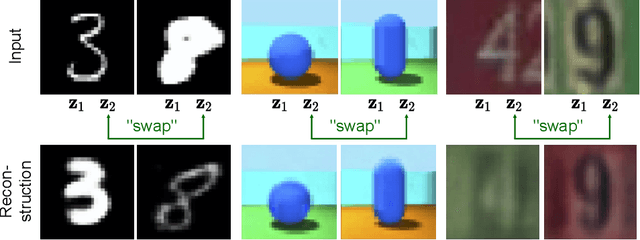
Work in deep clustering focuses on finding a single partition of data. However, high-dimensional data, such as images, typically feature multiple interesting characteristics one could cluster over. For example, images of objects against a background could be clustered over the shape of the object and separately by the colour of the background. In this paper, we introduce Multi-Facet Clustering Variational Autoencoders (MFCVAE), a novel class of variational autoencoders with a hierarchy of latent variables, each with a Mixture-of-Gaussians prior, that learns multiple clusterings simultaneously, and is trained fully unsupervised and end-to-end. MFCVAE uses a progressively-trained ladder architecture which leads to highly stable performance. We provide novel theoretical results for optimising the ELBO analytically with respect to the categorical variational posterior distribution, and corrects earlier influential theoretical work. On image benchmarks, we demonstrate that our approach separates out and clusters over different aspects of the data in a disentangled manner. We also show other advantages of our model: the compositionality of its latent space and that it provides controlled generation of samples.
Adaptive Transfer Learning of Multi-View Time Series Classification
Oct 14, 2019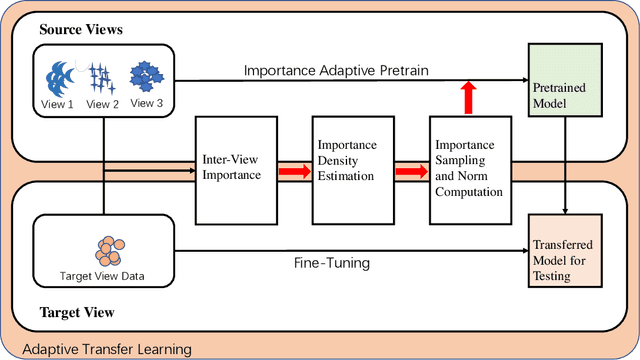


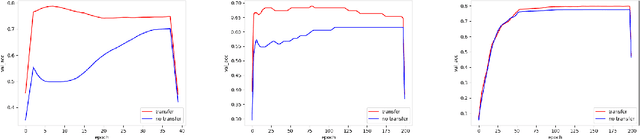
Time Series Classification (TSC) has been an important and challenging task in data mining, especially on multivariate time series and multi-view time series data sets. Meanwhile, transfer learning has been widely applied in computer vision and natural language processing applications to improve deep neural network's generalization capabilities. However, very few previous works applied transfer learning framework to time series mining problems. Particularly, the technique of measuring similarities between source domain and target domain based on dynamic representation such as density estimation with importance sampling has never been combined with transfer learning framework. In this paper, we first proposed a general adaptive transfer learning framework for multi-view time series data, which shows strong ability in storing inter-view importance value in the process of knowledge transfer. Next, we represented inter-view importance through some time series similarity measurements and approximated the posterior distribution in latent space for the importance sampling via density estimation techniques. We then computed the matrix norm of sampled importance value, which controls the degree of knowledge transfer in pre-training process. We further evaluated our work, applied it to many other time series classification tasks, and observed that our architecture maintained desirable generalization ability. Finally, we concluded that our framework could be adapted with deep learning techniques to receive significant model performance improvements.