 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMartingale-Consistent Self-Supervised Learning
May 12, 2026Self-supervised learning (SSL) is often deployed under changing information, such as shorter histories, missing features, or partially observed images. In these settings, predictions from coarse and refined views should be coherent: before refinement, the coarse-view prediction should match the average prediction expected after refinement. Martingales formalize this coherence principle, but standard SSL objectives do not enforce it. Unlike invariance objectives that pull views together, martingale consistency constrains only the expected refined prediction, allowing predictions to update as information is revealed while preventing systematic drift. We introduce a martingale-consistent SSL framework that closes this gap, with practical prediction- and latent-space variants and an unbiased two-sample Monte Carlo estimator based on stochastic refinement. We evaluate the approach on synthetic and real time-series, tabular, and image benchmarks under partial-observation regimes, in both semi-self-supervised and fully label-free settings. Across these experiments, our framework improves robustness and calibration under partial observation, yielding more stable representations as information is revealed.
Multimodal Survival Analysis with Locally Deployable Large Language Models
Mar 23, 2026We study multimodal survival analysis integrating clinical text, tabular covariates, and genomic profiles using locally deployable large language models (LLMs). As many institutions face tight computational and privacy constraints, this setting motivates the use of lightweight, on-premises models. Our approach jointly estimates calibrated survival probabilities and generates concise, evidence-grounded prognosis text via teacher-student distillation and principled multimodal fusion. On a TCGA cohort, it outperforms standard baselines, avoids reliance on cloud services and associated privacy concerns, and reduces the risk of hallucinated or miscalibrated estimates that can be observed in base LLMs.
Var-JEPA: A Variational Formulation of the Joint-Embedding Predictive Architecture -- Bridging Predictive and Generative Self-Supervised Learning
Mar 20, 2026The Joint-Embedding Predictive Architecture (JEPA) is often seen as a non-generative alternative to likelihood-based self-supervised learning, emphasizing prediction in representation space rather than reconstruction in observation space. We argue that the resulting separation from probabilistic generative modeling is largely rhetorical rather than structural: the canonical JEPA design, coupled encoders with a context-to-target predictor, mirrors the variational posteriors and learned conditional priors obtained when variational inference is applied to a particular class of coupled latent-variable models, and standard JEPA can be viewed as a deterministic specialization in which regularization is imposed via architectural and training heuristics rather than an explicit likelihood. Building on this view, we derive the Variational JEPA (Var-JEPA), which makes the latent generative structure explicit by optimizing a single Evidence Lower Bound (ELBO). This yields meaningful representations without ad-hoc anti-collapse regularizers and allows principled uncertainty quantification in the latent space. We instantiate the framework for tabular data (Var-T-JEPA) and achieve strong representation learning and downstream performance, consistently improving over T-JEPA while remaining competitive with strong raw-feature baselines.
VAE-MS: An Asymmetric Variational Autoencoder for Mutational Signature Extraction
Feb 24, 2026Mutational signature analysis has emerged as a powerful method for uncovering the underlying biological processes driving cancer development. However, the signature extraction process, typically performed using non-negative matrix factorization (NMF), often lacks reliability and clinical applicability. To address these limitations, several solutions have been introduced, including the use of neural networks to achieve more accurate estimates and probabilistic methods to better capture natural variation in the data. In this work, we introduce a Variational Autoencoder for Mutational Signatures (VAE-MS), a novel model that leverages both an asymmetric architecture and probabilistic methods for the extraction of mutational signatures. VAE-MS is compared to with three state-of-the-art models for mutational signature extraction: SigProfilerExtractor, the NMF-based gold standard; MUSE-XAE, an autoencoder that employs an asymmetric design without probabilistic components; and SigneR, a Bayesian NMF model, to illustrate the strength in combining a nonlinear extraction with a probabilistic model. In the ability to reconstruct input data and generalize to unseen data, models with probabilistic components (VAE-MS, SigneR) dramatically outperformed models without (SigProfilerExtractor, MUSE-XAE). The NMF-baed models (SigneR, SigProfilerExtractor) had the most accurate reconstructions in simulated data, while VAE-MS reconstructed more accurately on real cancer data. Upon evaluating the ability to extract signatures consistently, no model exhibited a clear advantage over the others. Software for VAE-MS is available at https://github.com/CLINDA-AAU/VAE-MS.
Bootstrapping-based Regularisation for Reducing Individual Prediction Instability in Clinical Risk Prediction Models
Feb 11, 2026Clinical prediction models are increasingly used to support patient care, yet many deep learning-based approaches remain unstable, as their predictions can vary substantially when trained on different samples from the same population. Such instability undermines reliability and limits clinical adoption. In this study, we propose a novel bootstrapping-based regularisation framework that embeds the bootstrapping process directly into the training of deep neural networks. This approach constrains prediction variability across resampled datasets, producing a single model with inherent stability properties. We evaluated models constructed using the proposed regularisation approach against conventional and ensemble models using simulated data and three clinical datasets: GUSTO-I, Framingham, and SUPPORT. Across all datasets, our model exhibited improved prediction stability, with lower mean absolute differences (e.g., 0.019 vs. 0.059 in GUSTO-I; 0.057 vs. 0.088 in Framingham) and markedly fewer significantly deviating predictions. Importantly, discriminative performance and feature importance consistency were maintained, with high SHAP correlations between models (e.g., 0.894 for GUSTO-I; 0.965 for Framingham). While ensemble models achieved greater stability, we show that this came at the expense of interpretability, as each constituent model used predictors in different ways. By regularising predictions to align with bootstrapped distributions, our approach allows prediction models to be developed that achieve greater robustness and reproducibility without sacrificing interpretability. This method provides a practical route toward more reliable and clinically trustworthy deep learning models, particularly valuable in data-limited healthcare settings.
Continual learning via probabilistic exchangeable sequence modelling
Mar 26, 2025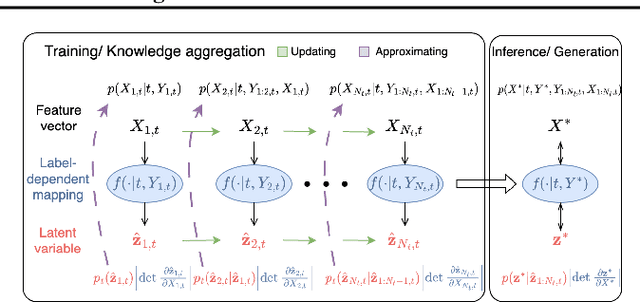
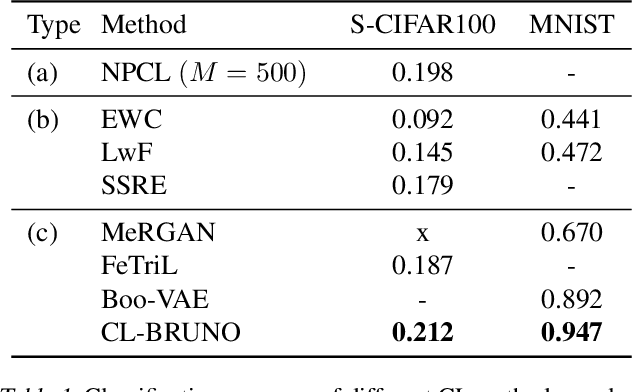
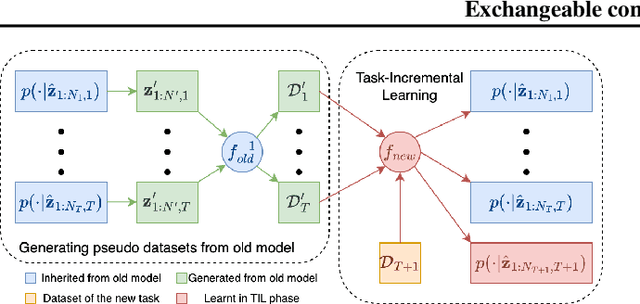
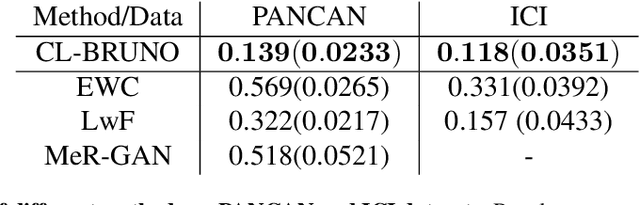
Continual learning (CL) refers to the ability to continuously learn and accumulate new knowledge while retaining useful information from past experiences. Although numerous CL methods have been proposed in recent years, it is not straightforward to deploy them directly to real-world decision-making problems due to their computational cost and lack of uncertainty quantification. To address these issues, we propose CL-BRUNO, a probabilistic, Neural Process-based CL model that performs scalable and tractable Bayesian update and prediction. Our proposed approach uses deep-generative models to create a unified probabilistic framework capable of handling different types of CL problems such as task- and class-incremental learning, allowing users to integrate information across different CL scenarios using a single model. Our approach is able to prevent catastrophic forgetting through distributional and functional regularisation without the need of retaining any previously seen samples, making it appealing to applications where data privacy or storage capacity is of concern. Experiments show that CL-BRUNO outperforms existing methods on both natural image and biomedical data sets, confirming its effectiveness in real-world applications.
A Transformer-based survival model for prediction of all-cause mortality in heart failure patients: a multi-cohort study
Mar 16, 2025



We developed and validated TRisk, a Transformer-based AI model predicting 36-month mortality in heart failure patients by analysing temporal patient journeys from UK electronic health records (EHR). Our study included 403,534 heart failure patients (ages 40-90) from 1,418 English general practices, with 1,063 practices for model derivation and 355 for external validation. TRisk was compared against the MAGGIC-EHR model across various patient subgroups. With median follow-up of 9 months, TRisk achieved a concordance index of 0.845 (95% confidence interval: [0.841, 0.849]), significantly outperforming MAGGIC-EHR's 0.728 (0.723, 0.733) for predicting 36-month all-cause mortality. TRisk showed more consistent performance across sex, age, and baseline characteristics, suggesting less bias. We successfully adapted TRisk to US hospital data through transfer learning, achieving a C-index of 0.802 (0.789, 0.816) with 21,767 patients. Explainability analyses revealed TRisk captured established risk factors while identifying underappreciated predictors like cancers and hepatic failure that were important across both cohorts. Notably, cancers maintained strong prognostic value even a decade after diagnosis. TRisk demonstrated well-calibrated mortality prediction across both healthcare systems. Our findings highlight the value of tracking longitudinal health profiles and revealed risk factors not included in previous expert-driven models.
Wave-LSTM: Multi-scale analysis of somatic whole genome copy number profiles
Aug 22, 2024Changes in the number of copies of certain parts of the genome, known as copy number alterations (CNAs), due to somatic mutation processes are a hallmark of many cancers. This genomic complexity is known to be associated with poorer outcomes for patients but describing its contribution in detail has been difficult. Copy number alterations can affect large regions spanning whole chromosomes or the entire genome itself but can also be localised to only small segments of the genome and no methods exist that allow this multi-scale nature to be quantified. In this paper, we address this using Wave-LSTM, a signal decomposition approach designed to capture the multi-scale structure of complex whole genome copy number profiles. Using wavelet-based source separation in combination with deep learning-based attention mechanisms. We show that Wave-LSTM can be used to derive multi-scale representations from copy number profiles which can be used to decipher sub-clonal structures from single-cell copy number data and to improve survival prediction performance from patient tumour profiles.
Disentangling shared and private latent factors in multimodal Variational Autoencoders
Mar 10, 2024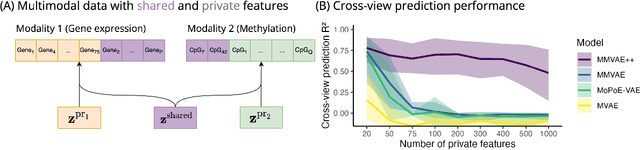
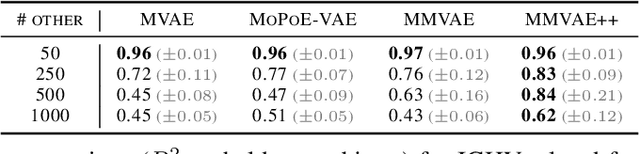
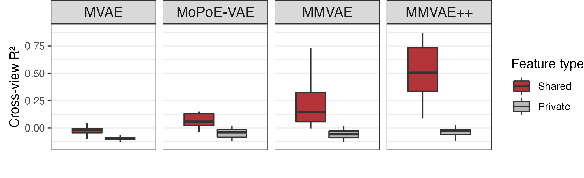

Generative models for multimodal data permit the identification of latent factors that may be associated with important determinants of observed data heterogeneity. Common or shared factors could be important for explaining variation across modalities whereas other factors may be private and important only for the explanation of a single modality. Multimodal Variational Autoencoders, such as MVAE and MMVAE, are a natural choice for inferring those underlying latent factors and separating shared variation from private. In this work, we investigate their capability to reliably perform this disentanglement. In particular, we highlight a challenging problem setting where modality-specific variation dominates the shared signal. Taking a cross-modal prediction perspective, we demonstrate limitations of existing models, and propose a modification how to make them more robust to modality-specific variation. Our findings are supported by experiments on synthetic as well as various real-world multi-omics data sets.
A Multi-Resolution Framework for U-Nets with Applications to Hierarchical VAEs
Jan 19, 2023U-Net architectures are ubiquitous in state-of-the-art deep learning, however their regularisation properties and relationship to wavelets are understudied. In this paper, we formulate a multi-resolution framework which identifies U-Nets as finite-dimensional truncations of models on an infinite-dimensional function space. We provide theoretical results which prove that average pooling corresponds to projection within the space of square-integrable functions and show that U-Nets with average pooling implicitly learn a Haar wavelet basis representation of the data. We then leverage our framework to identify state-of-the-art hierarchical VAEs (HVAEs), which have a U-Net architecture, as a type of two-step forward Euler discretisation of multi-resolution diffusion processes which flow from a point mass, introducing sampling instabilities. We also demonstrate that HVAEs learn a representation of time which allows for improved parameter efficiency through weight-sharing. We use this observation to achieve state-of-the-art HVAE performance with half the number of parameters of existing models, exploiting the properties of our continuous-time formulation.