 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconfounding Scores and Representation Learning for Causal Effect Estimation with Weak Overlap
Apr 01, 2026Overlap, also known as positivity, is a key condition for causal treatment effect estimation. Many popular estimators suffer from high variance and become brittle when features differ strongly across treatment groups. This is especially challenging in high dimensions: the curse of dimensionality can make overlap implausible. To address this, we propose a class of feature representations called deconfounding scores, which preserve both identification and the target of estimation; the classical propensity and prognostic scores are two special cases. We characterize the problem of finding a representation with better overlap as minimizing an overlap divergence under a deconfounding score constraint. We then derive closed-form expressions for a class of deconfounding scores under a broad family of generalized linear models with Gaussian features and show that prognostic scores are overlap-optimal within this class. We conduct extensive experiments to assess this behavior empirically.
Predicting fixed-sample test decisions enables anytime-valid inference
Feb 14, 2026Statistical hypothesis tests typically use prespecified sample sizes, yet data often arrive sequentially. Interim analyses invalidate classical error guarantees, while existing sequential methods require rigid testing preschedules or incur substantial losses in statistical power. We introduce a simple procedure that transforms any fixed-sample hypothesis test into an anytime-valid test while ensuring Type-I error control and near-optimal power with substantial sample savings when the null hypothesis is false. At each step, the procedure predicts the probability that a classical test would reject the null hypothesis at its fixed-sample size, treating future observations as missing data under the null hypothesis. Thresholding this probability yields an anytime-valid stopping rule. In areas such as clinical trials, stopping early and safely can ensure that subjects receive the best treatments and accelerate the development of effective therapies.
Confidence in the Reasoning of Large Language Models
Dec 19, 2024



There is a growing literature on reasoning by large language models (LLMs), but the discussion on the uncertainty in their responses is still lacking. Our aim is to assess the extent of confidence that LLMs have in their answers and how it correlates with accuracy. Confidence is measured (i) qualitatively in terms of persistence in keeping their answer when prompted to reconsider, and (ii) quantitatively in terms of self-reported confidence score. We investigate the performance of three LLMs -- GPT4o, GPT4-turbo and Mistral -- on two benchmark sets of questions on causal judgement and formal fallacies and a set of probability and statistical puzzles and paradoxes. Although the LLMs show significantly better performance than random guessing, there is a wide variability in their tendency to change their initial answers. There is a positive correlation between qualitative confidence and accuracy, but the overall accuracy for the second answer is often worse than for the first answer. There is a strong tendency to overstate the self-reported confidence score. Confidence is only partially explained by the underlying token-level probability. The material effects of prompting on qualitative confidence and the strong tendency for overconfidence indicate that current LLMs do not have any internally coherent sense of confidence.
Fields of The World: A Machine Learning Benchmark Dataset For Global Agricultural Field Boundary Segmentation
Sep 24, 2024



Crop field boundaries are foundational datasets for agricultural monitoring and assessments but are expensive to collect manually. Machine learning (ML) methods for automatically extracting field boundaries from remotely sensed images could help realize the demand for these datasets at a global scale. However, current ML methods for field instance segmentation lack sufficient geographic coverage, accuracy, and generalization capabilities. Further, research on improving ML methods is restricted by the lack of labeled datasets representing the diversity of global agricultural fields. We present Fields of The World (FTW) -- a novel ML benchmark dataset for agricultural field instance segmentation spanning 24 countries on four continents (Europe, Africa, Asia, and South America). FTW is an order of magnitude larger than previous datasets with 70,462 samples, each containing instance and semantic segmentation masks paired with multi-date, multi-spectral Sentinel-2 satellite images. We provide results from baseline models for the new FTW benchmark, show that models trained on FTW have better zero-shot and fine-tuning performance in held-out countries than models that aren't pre-trained with diverse datasets, and show positive qualitative zero-shot results of FTW models in a real-world scenario -- running on Sentinel-2 scenes over Ethiopia.
Towards Representation Learning for Weighting Problems in Design-Based Causal Inference
Sep 24, 2024Reweighting a distribution to minimize a distance to a target distribution is a powerful and flexible strategy for estimating a wide range of causal effects, but can be challenging in practice because optimal weights typically depend on knowledge of the underlying data generating process. In this paper, we focus on design-based weights, which do not incorporate outcome information; prominent examples include prospective cohort studies, survey weighting, and the weighting portion of augmented weighting estimators. In such applications, we explore the central role of representation learning in finding desirable weights in practice. Unlike the common approach of assuming a well-specified representation, we highlight the error due to the choice of a representation and outline a general framework for finding suitable representations that minimize this error. Building on recent work that combines balancing weights and neural networks, we propose an end-to-end estimation procedure that learns a flexible representation, while retaining promising theoretical properties. We show that this approach is competitive in a range of common causal inference tasks.
Is merging worth it? Securely evaluating the information gain for causal dataset acquisition
Sep 11, 2024



Merging datasets across institutions is a lengthy and costly procedure, especially when it involves private information. Data hosts may therefore want to prospectively gauge which datasets are most beneficial to merge with, without revealing sensitive information. For causal estimation this is particularly challenging as the value of a merge will depend not only on the reduction in epistemic uncertainty but also the improvement in overlap. To address this challenge, we introduce the first cryptographically secure information-theoretic approach for quantifying the value of a merge in the context of heterogeneous treatment effect estimation. We do this by evaluating the Expected Information Gain (EIG) and utilising multi-party computation to ensure it can be securely computed without revealing any raw data. As we demonstrate, this can be used with differential privacy (DP) to ensure privacy requirements whilst preserving more accurate computation than naive DP alone. To the best of our knowledge, this work presents the first privacy-preserving method for dataset acquisition tailored to causal estimation. We demonstrate the effectiveness and reliability of our method on a range of simulated and realistic benchmarks. The code is available anonymously.
On Subjective Uncertainty Quantification and Calibration in Natural Language Generation
Jun 07, 2024



Applications of large language models often involve the generation of free-form responses, in which case uncertainty quantification becomes challenging. This is due to the need to identify task-specific uncertainties (e.g., about the semantics) which appears difficult to define in general cases. This work addresses these challenges from a perspective of Bayesian decision theory, starting from the assumption that our utility is characterized by a similarity measure that compares a generated response with a hypothetical true response. We discuss how this assumption enables principled quantification of the model's subjective uncertainty and its calibration. We further derive a measure for epistemic uncertainty, based on a missing data perspective and its characterization as an excess risk. The proposed measures can be applied to black-box language models. We demonstrate the proposed methods on question answering and machine translation tasks, where they extract broadly meaningful uncertainty estimates from GPT and Gemini models and quantify their calibration.
Is In-Context Learning in Large Language Models Bayesian? A Martingale Perspective
Jun 02, 2024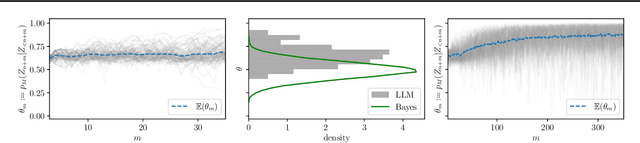
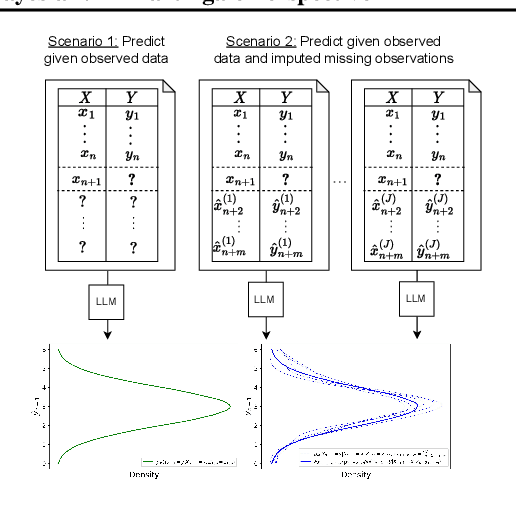
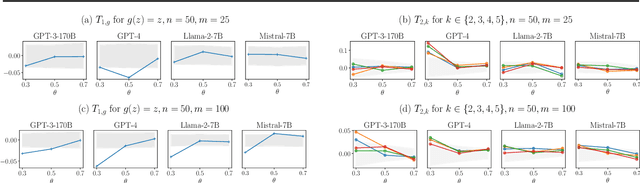
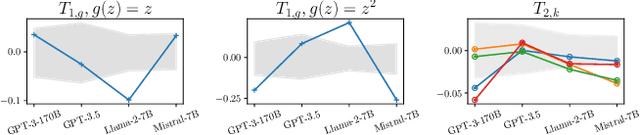
In-context learning (ICL) has emerged as a particularly remarkable characteristic of Large Language Models (LLM): given a pretrained LLM and an observed dataset, LLMs can make predictions for new data points from the same distribution without fine-tuning. Numerous works have postulated ICL as approximately Bayesian inference, rendering this a natural hypothesis. In this work, we analyse this hypothesis from a new angle through the martingale property, a fundamental requirement of a Bayesian learning system for exchangeable data. We show that the martingale property is a necessary condition for unambiguous predictions in such scenarios, and enables a principled, decomposed notion of uncertainty vital in trustworthy, safety-critical systems. We derive actionable checks with corresponding theory and test statistics which must hold if the martingale property is satisfied. We also examine if uncertainty in LLMs decreases as expected in Bayesian learning when more data is observed. In three experiments, we provide evidence for violations of the martingale property, and deviations from a Bayesian scaling behaviour of uncertainty, falsifying the hypothesis that ICL is Bayesian.
On Uncertainty Quantification for Near-Bayes Optimal Algorithms
Mar 28, 2024Bayesian modelling allows for the quantification of predictive uncertainty which is crucial in safety-critical applications. Yet for many machine learning (ML) algorithms, it is difficult to construct or implement their Bayesian counterpart. In this work we present a promising approach to address this challenge, based on the hypothesis that commonly used ML algorithms are efficient across a wide variety of tasks and may thus be near Bayes-optimal w.r.t. an unknown task distribution. We prove that it is possible to recover the Bayesian posterior defined by the task distribution, which is unknown but optimal in this setting, by building a martingale posterior using the algorithm. We further propose a practical uncertainty quantification method that apply to general ML algorithms. Experiments based on a variety of non-NN and NN algorithms demonstrate the efficacy of our method.
Approximations to the Fisher Information Metric of Deep Generative Models for Out-Of-Distribution Detection
Mar 03, 2024Likelihood-based deep generative models such as score-based diffusion models and variational autoencoders are state-of-the-art machine learning models approximating high-dimensional distributions of data such as images, text, or audio. One of many downstream tasks they can be naturally applied to is out-of-distribution (OOD) detection. However, seminal work by Nalisnick et al. which we reproduce showed that deep generative models consistently infer higher log-likelihoods for OOD data than data they were trained on, marking an open problem. In this work, we analyse using the gradient of a data point with respect to the parameters of the deep generative model for OOD detection, based on the simple intuition that OOD data should have larger gradient norms than training data. We formalise measuring the size of the gradient as approximating the Fisher information metric. We show that the Fisher information matrix (FIM) has large absolute diagonal values, motivating the use of chi-square distributed, layer-wise gradient norms as features. We combine these features to make a simple, model-agnostic and hyperparameter-free method for OOD detection which estimates the joint density of the layer-wise gradient norms for a given data point. We find that these layer-wise gradient norms are weakly correlated, rendering their combined usage informative, and prove that the layer-wise gradient norms satisfy the principle of (data representation) invariance. Our empirical results indicate that this method outperforms the Typicality test for most deep generative models and image dataset pairings.