 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Bias-Driven Stratification for Interpretable Causal Effect Estimation
Jan 31, 2024Interpretability and transparency are essential for incorporating causal effect models from observational data into policy decision-making. They can provide trust for the model in the absence of ground truth labels to evaluate the accuracy of such models. To date, attempts at transparent causal effect estimation consist of applying post hoc explanation methods to black-box models, which are not interpretable. Here, we present BICauseTree: an interpretable balancing method that identifies clusters where natural experiments occur locally. Our approach builds on decision trees with a customized objective function to improve balancing and reduce treatment allocation bias. Consequently, it can additionally detect subgroups presenting positivity violations, exclude them, and provide a covariate-based definition of the target population we can infer from and generalize to. We evaluate the method's performance using synthetic and realistic datasets, explore its bias-interpretability tradeoff, and show that it is comparable with existing approaches.
Replay For Safety
Dec 08, 2021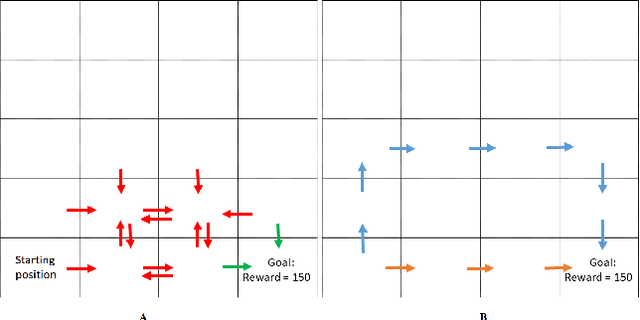

Experience replay \citep{lin1993reinforcement, mnih2015human} is a widely used technique to achieve efficient use of data and improved performance in RL algorithms. In experience replay, past transitions are stored in a memory buffer and re-used during learning. Various suggestions for sampling schemes from the replay buffer have been suggested in previous works, attempting to optimally choose those experiences which will most contribute to the convergence to an optimal policy. Here, we give some conditions on the replay sampling scheme that will ensure convergence, focusing on the well-known Q-learning algorithm in the tabular setting. After establishing sufficient conditions for convergence, we turn to suggest a slightly different usage for experience replay - replaying memories in a biased manner as a means to change the properties of the resulting policy. We initiate a rigorous study of experience replay as a tool to control and modify the properties of the resulting policy. In particular, we show that using an appropriate biased sampling scheme can allow us to achieve a \emph{safe} policy. We believe that using experience replay as a biasing mechanism that allows controlling the resulting policy in desirable ways is an idea with promising potential for many applications.
Convergence Results For Q-Learning With Experience Replay
Dec 08, 2021


A commonly used heuristic in RL is experience replay (e.g.~\citet{lin1993reinforcement, mnih2015human}), in which a learner stores and re-uses past trajectories as if they were sampled online. In this work, we initiate a rigorous study of this heuristic in the setting of tabular Q-learning. We provide a convergence rate guarantee, and discuss how it compares to the convergence of Q-learning depending on important parameters such as the frequency and number of replay iterations. We also provide theoretical evidence showing when we might expect this heuristic to strictly improve performance, by introducing and analyzing a simple class of MDPs. Finally, we provide some experiments to support our theoretical findings.
Online Learning with Local Permutations and Delayed Feedback
Mar 13, 2017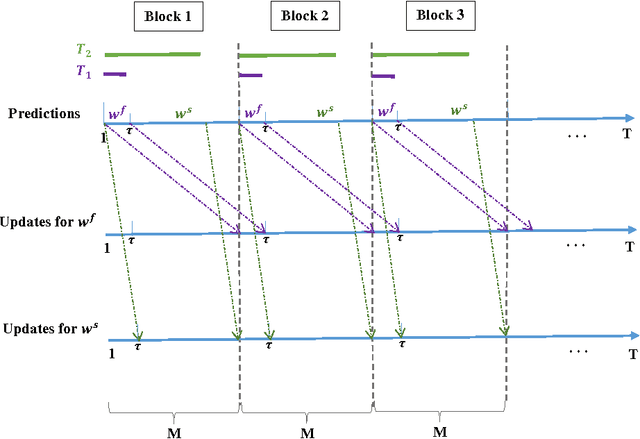

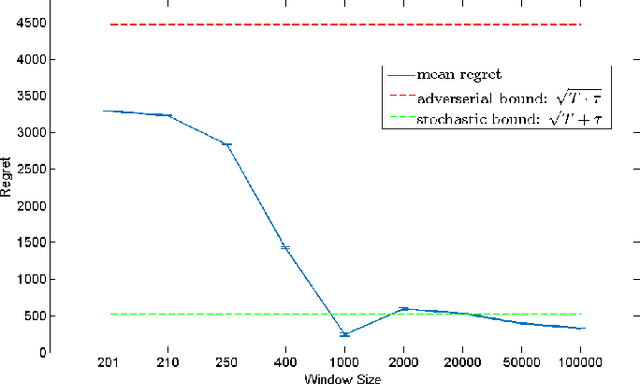
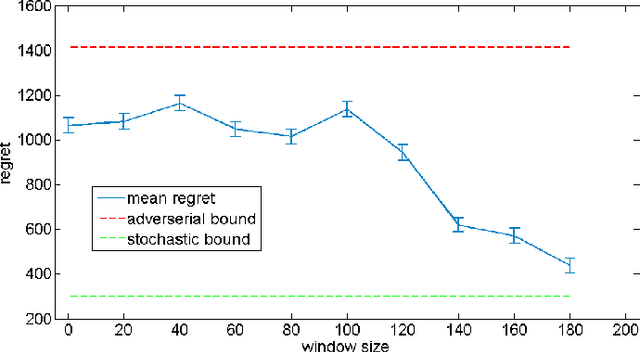
We propose an Online Learning with Local Permutations (OLLP) setting, in which the learner is allowed to slightly permute the \emph{order} of the loss functions generated by an adversary. On one hand, this models natural situations where the exact order of the learner's responses is not crucial, and on the other hand, might allow better learning and regret performance, by mitigating highly adversarial loss sequences. Also, with random permutations, this can be seen as a setting interpolating between adversarial and stochastic losses. In this paper, we consider the applicability of this setting to convex online learning with delayed feedback, in which the feedback on the prediction made in round $t$ arrives with some delay $\tau$. With such delayed feedback, the best possible regret bound is well-known to be $O(\sqrt{\tau T})$. We prove that by being able to permute losses by a distance of at most $M$ (for $M\geq \tau$), the regret can be improved to $O(\sqrt{T}(1+\sqrt{\tau^2/M}))$, using a Mirror-Descent based algorithm which can be applied for both Euclidean and non-Euclidean geometries. We also prove a lower bound, showing that for $M<\tau/3$, it is impossible to improve the standard $O(\sqrt{\tau T})$ regret bound by more than constant factors. Finally, we provide some experiments validating the performance of our algorithm.
Multi-Player Bandits -- a Musical Chairs Approach
Dec 09, 2015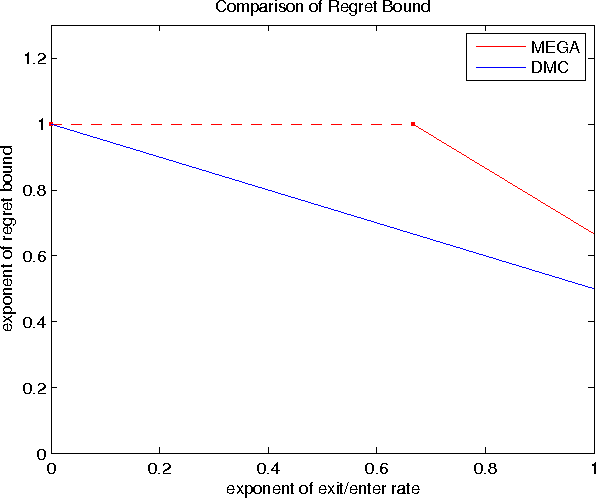
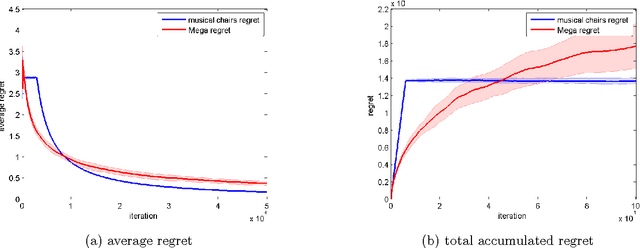
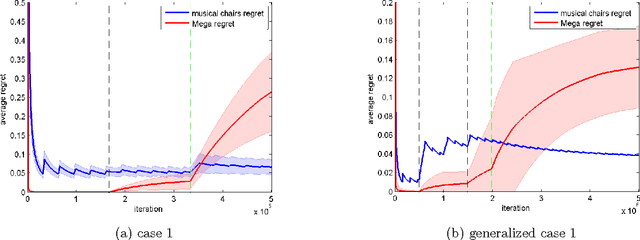

We consider a variant of the stochastic multi-armed bandit problem, where multiple players simultaneously choose from the same set of arms and may collide, receiving no reward. This setting has been motivated by problems arising in cognitive radio networks, and is especially challenging under the realistic assumption that communication between players is limited. We provide a communication-free algorithm (Musical Chairs) which attains constant regret with high probability, as well as a sublinear-regret, communication-free algorithm (Dynamic Musical Chairs) for the more difficult setting of players dynamically entering and leaving throughout the game. Moreover, both algorithms do not require prior knowledge of the number of players. To the best of our knowledge, these are the first communication-free algorithms with these types of formal guarantees. We also rigorously compare our algorithms to previous works, and complement our theoretical findings with experiments.