 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted learning of heterogeneous treatment effect curves for right censored or left truncated time-to-event data
Mar 27, 2026In recent years, there has been growing interest in causal machine learning estimators for quantifying subject-specific effects of a binary treatment on time-to-event outcomes. Estimation approaches have been proposed which attenuate the inherent regularisation bias in machine learning predictions, with each of these estimators addressing measured confounding, right censoring, and in some cases, left truncation. However, the existing approaches are found to exhibit suboptimal finite-sample performance, with none of the existing estimators fully leveraging the temporal structure of the data, yielding non-smooth treatment effects over time. We address these limitations by introducing surv-iTMLE, a targeted learning procedure for estimating the difference in the conditional survival probabilities under two treatments. Unlike existing estimators, surv-iTMLE accommodates both left truncation and right censoring while enforcing smoothness and boundedness of the estimated treatment effect curve over time. Through extensive simulation studies under both right censoring and left truncation scenarios, we demonstrate that surv-iTMLE outperforms existing methods in terms of bias and smoothness of time-varying effect estimates in finite samples. We then illustrate surv-iTMLE's practical utility by exploring heterogeneity in the effects of immunotherapy on survival among non-small cell lung cancer (NSCLC) patients, revealing clinically meaningful temporal patterns that existing estimators may obscure.
Causal machine learning for heterogeneous treatment effects in the presence of missing outcome data
Dec 27, 2024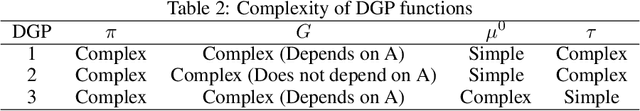
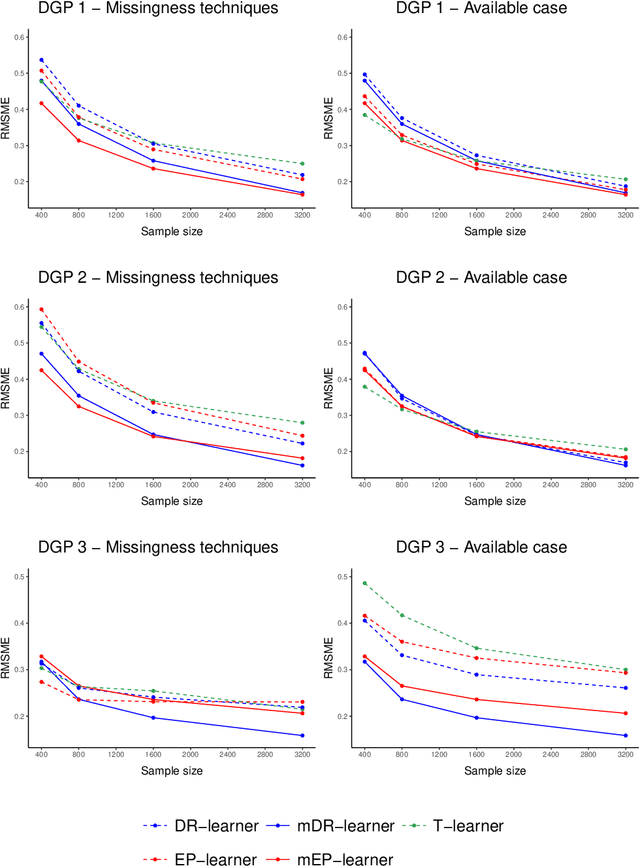

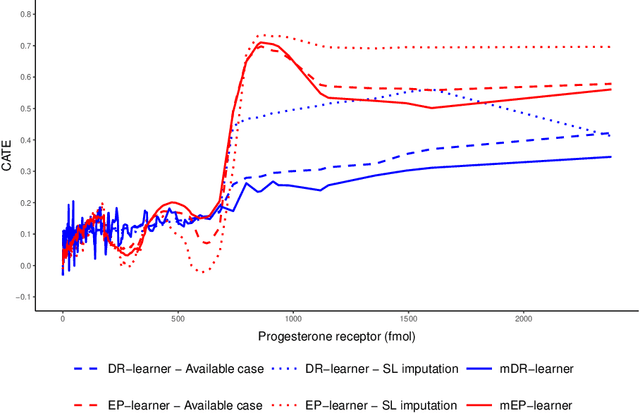
When estimating heterogeneous treatment effects, missing outcome data can complicate treatment effect estimation, causing certain subgroups of the population to be poorly represented. In this work, we discuss this commonly overlooked problem and consider the impact that missing at random (MAR) outcome data has on causal machine learning estimators for the conditional average treatment effect (CATE). We then propose two de-biased machine learning estimators for the CATE, the mDR-learner and mEP-learner, which address the issue of under-representation by integrating inverse probability of censoring weights into the DR-learner and EP-learner respectively. We show that under reasonable conditions, these estimators are oracle efficient, and illustrate their favorable performance through simulated data settings, comparing them to existing CATE estimators, including comparison to estimators which use common missing data techniques. Guidance on the implementation of these estimators is provided and we present an example of their application using the ACTG175 trial, exploring treatment effect heterogeneity when comparing Zidovudine mono-therapy against alternative antiretroviral therapies among HIV-1-infected individuals.
Explainable AI for survival analysis: a median-SHAP approach
Jan 30, 2024With the adoption of machine learning into routine clinical practice comes the need for Explainable AI methods tailored to medical applications. Shapley values have sparked wide interest for locally explaining models. Here, we demonstrate their interpretation strongly depends on both the summary statistic and the estimator for it, which in turn define what we identify as an 'anchor point'. We show that the convention of using a mean anchor point may generate misleading interpretations for survival analysis and introduce median-SHAP, a method for explaining black-box models predicting individual survival times.
PWSHAP: A Path-Wise Explanation Model for Targeted Variables
Jun 26, 2023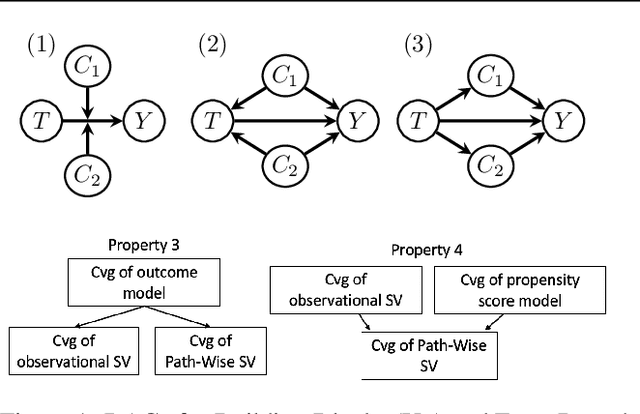
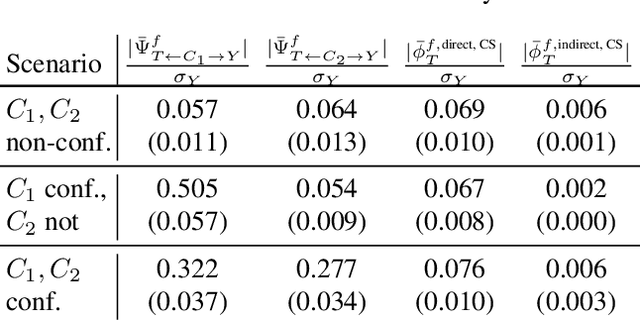

Predictive black-box models can exhibit high accuracy but their opaque nature hinders their uptake in safety-critical deployment environments. Explanation methods (XAI) can provide confidence for decision-making through increased transparency. However, existing XAI methods are not tailored towards models in sensitive domains where one predictor is of special interest, such as a treatment effect in a clinical model, or ethnicity in policy models. We introduce Path-Wise Shapley effects (PWSHAP), a framework for assessing the targeted effect of a binary (e.g.~treatment) variable from a complex outcome model. Our approach augments the predictive model with a user-defined directed acyclic graph (DAG). The method then uses the graph alongside on-manifold Shapley values to identify effects along causal pathways whilst maintaining robustness to adversarial attacks. We establish error bounds for the identified path-wise Shapley effects and for Shapley values. We show PWSHAP can perform local bias and mediation analyses with faithfulness to the model. Further, if the targeted variable is randomised we can quantify local effect modification. We demonstrate the resolution, interpretability, and true locality of our approach on examples and a real-world experiment.
On Locality of Local Explanation Models
Jun 24, 2021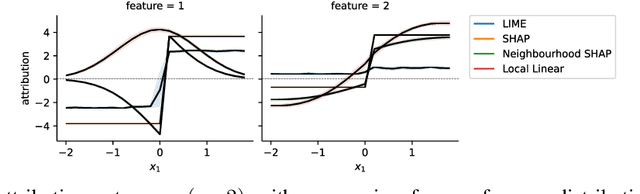
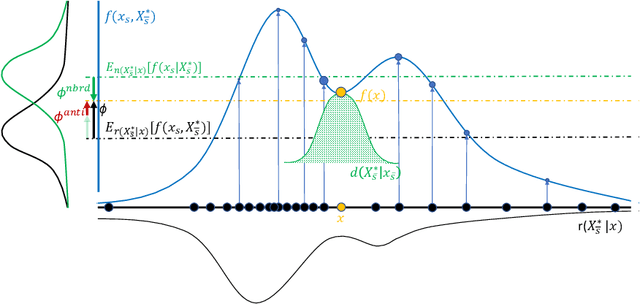

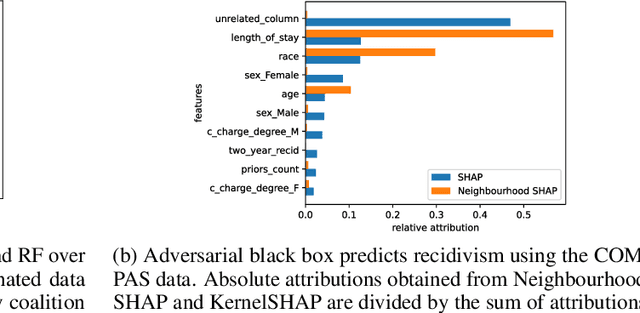
Shapley values provide model agnostic feature attributions for model outcome at a particular instance by simulating feature absence under a global population distribution. The use of a global population can lead to potentially misleading results when local model behaviour is of interest. Hence we consider the formulation of neighbourhood reference distributions that improve the local interpretability of Shapley values. By doing so, we find that the Nadaraya-Watson estimator, a well-studied kernel regressor, can be expressed as a self-normalised importance sampling estimator. Empirically, we observe that Neighbourhood Shapley values identify meaningful sparse feature relevance attributions that provide insight into local model behaviour, complimenting conventional Shapley analysis. They also increase on-manifold explainability and robustness to the construction of adversarial classifiers.