 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal machine learning for heterogeneous treatment effects in the presence of missing outcome data
Paper and Code
Dec 27, 2024
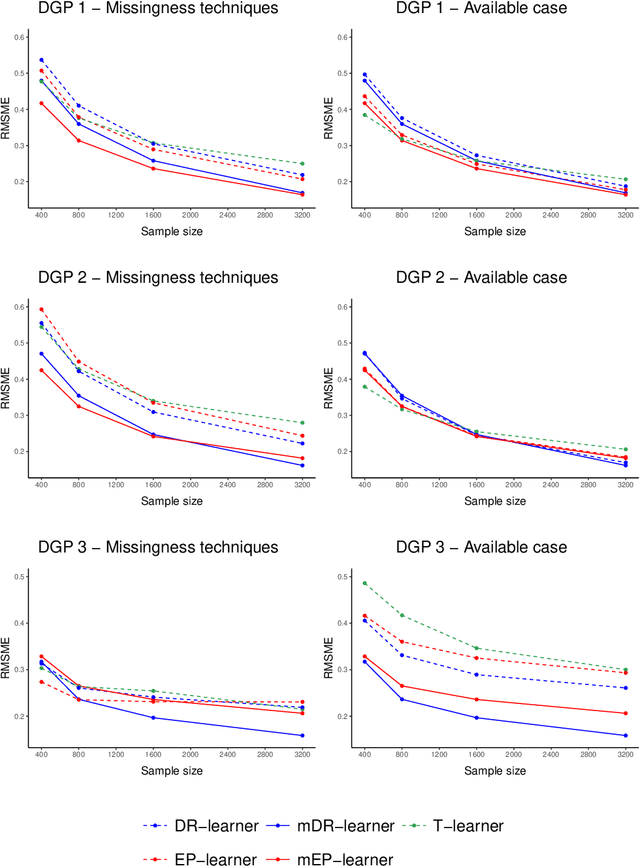

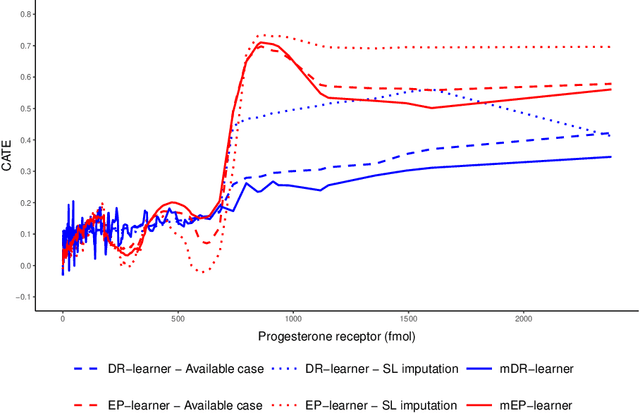
When estimating heterogeneous treatment effects, missing outcome data can complicate treatment effect estimation, causing certain subgroups of the population to be poorly represented. In this work, we discuss this commonly overlooked problem and consider the impact that missing at random (MAR) outcome data has on causal machine learning estimators for the conditional average treatment effect (CATE). We then propose two de-biased machine learning estimators for the CATE, the mDR-learner and mEP-learner, which address the issue of under-representation by integrating inverse probability of censoring weights into the DR-learner and EP-learner respectively. We show that under reasonable conditions, these estimators are oracle efficient, and illustrate their favorable performance through simulated data settings, comparing them to existing CATE estimators, including comparison to estimators which use common missing data techniques. Guidance on the implementation of these estimators is provided and we present an example of their application using the ACTG175 trial, exploring treatment effect heterogeneity when comparing Zidovudine mono-therapy against alternative antiretroviral therapies among HIV-1-infected individuals.