 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Nonasymptotic Confidence Intervals for Treatment Effects in Randomized Experiments
Jan 16, 2026We study nonasymptotic (finite-sample) confidence intervals for treatment effects in randomized experiments. In the existing literature, the effective sample sizes of nonasymptotic confidence intervals tend to be looser than the corresponding central-limit-theorem-based confidence intervals by a factor depending on the square root of the propensity score. We show that this performance gap can be closed, designing nonasymptotic confidence intervals that have the same effective sample size as their asymptotic counterparts. Our approach involves systematic exploitation of negative dependence or variance adaptivity (or both). We also show that the nonasymptotic rates that we achieve are unimprovable in an information-theoretic sense.
Evaluation and Incident Prevention in an Enterprise AI Assistant
Apr 11, 2025



Enterprise AI Assistants are increasingly deployed in domains where accuracy is paramount, making each erroneous output a potentially significant incident. This paper presents a comprehensive framework for monitoring, benchmarking, and continuously improving such complex, multi-component systems under active development by multiple teams. Our approach encompasses three key elements: (1) a hierarchical ``severity'' framework for incident detection that identifies and categorizes errors while attributing component-specific error rates, facilitating targeted improvements; (2) a scalable and principled methodology for benchmark construction, evaluation, and deployment, designed to accommodate multiple development teams, mitigate overfitting risks, and assess the downstream impact of system modifications; and (3) a continual improvement strategy leveraging multidimensional evaluation, enabling the identification and implementation of diverse enhancement opportunities. By adopting this holistic framework, organizations can systematically enhance the reliability and performance of their AI Assistants, ensuring their efficacy in critical enterprise environments. We conclude by discussing how this multifaceted evaluation approach opens avenues for various classes of enhancements, paving the way for more robust and trustworthy AI systems.
Towards Representation Learning for Weighting Problems in Design-Based Causal Inference
Sep 24, 2024Reweighting a distribution to minimize a distance to a target distribution is a powerful and flexible strategy for estimating a wide range of causal effects, but can be challenging in practice because optimal weights typically depend on knowledge of the underlying data generating process. In this paper, we focus on design-based weights, which do not incorporate outcome information; prominent examples include prospective cohort studies, survey weighting, and the weighting portion of augmented weighting estimators. In such applications, we explore the central role of representation learning in finding desirable weights in practice. Unlike the common approach of assuming a well-specified representation, we highlight the error due to the choice of a representation and outline a general framework for finding suitable representations that minimize this error. Building on recent work that combines balancing weights and neural networks, we propose an end-to-end estimation procedure that learns a flexible representation, while retaining promising theoretical properties. We show that this approach is competitive in a range of common causal inference tasks.
The Impossibility of Fair LLMs
May 28, 2024The need for fair AI is increasingly clear in the era of general-purpose systems such as ChatGPT, Gemini, and other large language models (LLMs). However, the increasing complexity of human-AI interaction and its social impacts have raised questions of how fairness standards could be applied. Here, we review the technical frameworks that machine learning researchers have used to evaluate fairness, such as group fairness and fair representations, and find that their application to LLMs faces inherent limitations. We show that each framework either does not logically extend to LLMs or presents a notion of fairness that is intractable for LLMs, primarily due to the multitudes of populations affected, sensitive attributes, and use cases. To address these challenges, we develop guidelines for the more realistic goal of achieving fairness in particular use cases: the criticality of context, the responsibility of LLM developers, and the need for stakeholder participation in an iterative process of design and evaluation. Moreover, it may eventually be possible and even necessary to use the general-purpose capabilities of AI systems to address fairness challenges as a form of scalable AI-assisted alignment.
Continuous Treatment Effects with Surrogate Outcomes
Jan 31, 2024In many real-world causal inference applications, the primary outcomes (labels) are often partially missing, especially if they are expensive or difficult to collect. If the missingness depends on covariates (i.e., missingness is not completely at random), analyses based on fully-observed samples alone may be biased. Incorporating surrogates, which are fully observed post-treatment variables related to the primary outcome, can improve estimation in this case. In this paper, we study the role of surrogates in estimating continuous treatment effects and propose a doubly robust method to efficiently incorporate surrogates in the analysis, which uses both labeled and unlabeled data and does not suffer from the above selection bias problem. Importantly, we establish asymptotic normality of the proposed estimator and show possible improvements on the variance compared with methods that solely use labeled data. Extensive simulations show our methods enjoy appealing empirical performance.
Augmented balancing weights as linear regression
Apr 27, 2023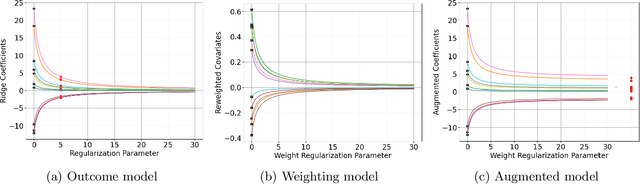
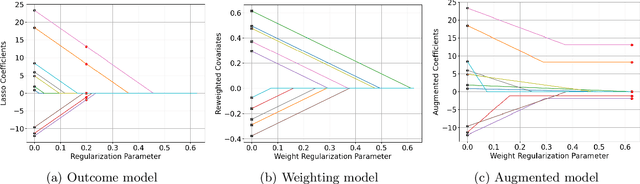
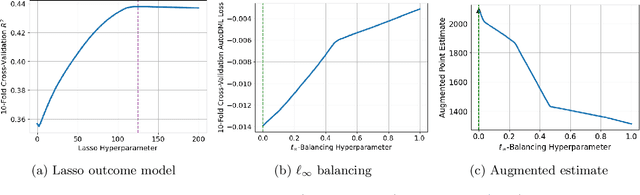
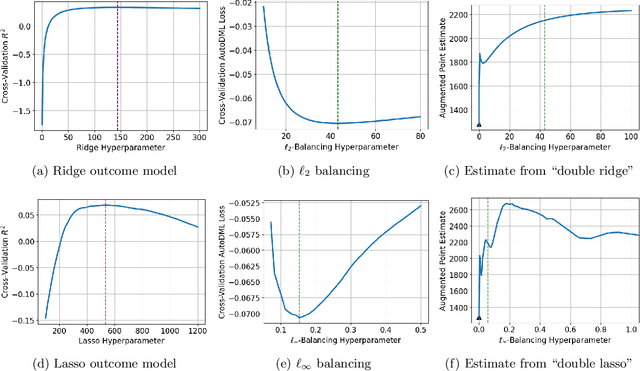
We provide a novel characterization of augmented balancing weights, also known as Automatic Debiased Machine Learning (AutoDML). These estimators combine outcome modeling with balancing weights, which estimate inverse propensity score weights directly. When the outcome and weighting models are both linear in some (possibly infinite) basis, we show that the augmented estimator is equivalent to a single linear model with coefficients that combine the original outcome model coefficients and OLS; in many settings, the augmented estimator collapses to OLS alone. We then extend these results to specific choices of outcome and weighting models. We first show that the combined estimator that uses (kernel) ridge regression for both outcome and weighting models is equivalent to a single, undersmoothed (kernel) ridge regression; this also holds when considering asymptotic rates. When the weighting model is instead lasso regression, we give closed-form expressions for special cases and demonstrate a ``double selection'' property. Finally, we generalize these results to linear estimands via the Riesz representer. Our framework ``opens the black box'' on these increasingly popular estimators and provides important insights into estimation choices for augmented balancing weights.
Outcome Assumptions and Duality Theory for Balancing Weights
Mar 17, 2022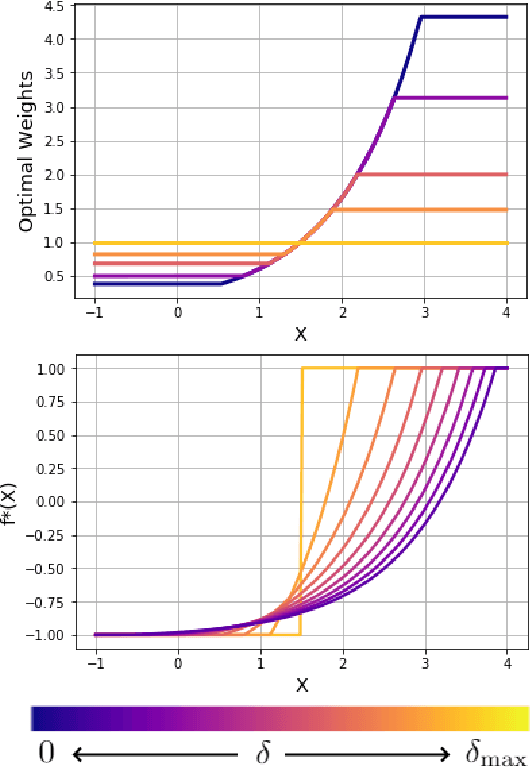
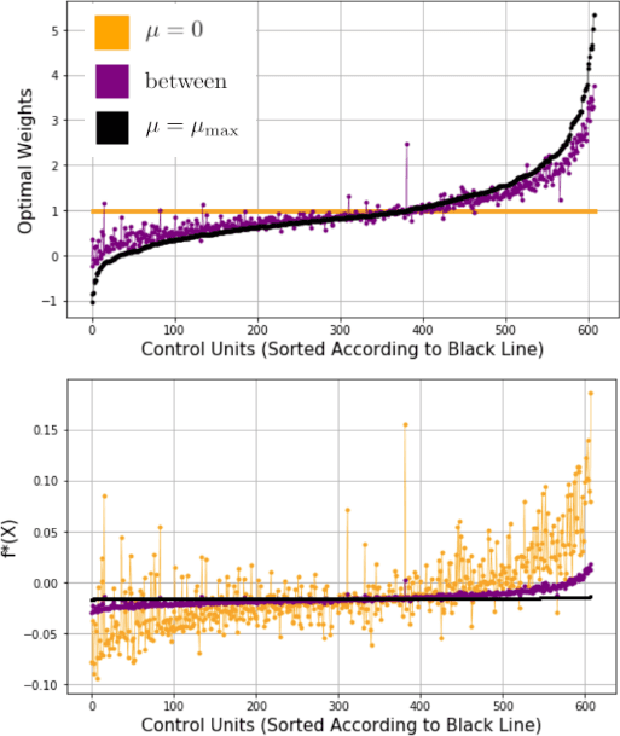
We study balancing weight estimators, which reweight outcomes from a source population to estimate missing outcomes in a target population. These estimators minimize the worst-case error by making an assumption about the outcome model. In this paper, we show that this outcome assumption has two immediate implications. First, we can replace the minimax optimization problem for balancing weights with a simple convex loss over the assumed outcome function class. Second, we can replace the commonly-made overlap assumption with a more appropriate quantitative measure, the minimum worst-case bias. Finally, we show conditions under which the weights remain robust when our assumptions on the outcomes are wrong.