 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation and Incident Prevention in an Enterprise AI Assistant
Apr 11, 2025



Enterprise AI Assistants are increasingly deployed in domains where accuracy is paramount, making each erroneous output a potentially significant incident. This paper presents a comprehensive framework for monitoring, benchmarking, and continuously improving such complex, multi-component systems under active development by multiple teams. Our approach encompasses three key elements: (1) a hierarchical ``severity'' framework for incident detection that identifies and categorizes errors while attributing component-specific error rates, facilitating targeted improvements; (2) a scalable and principled methodology for benchmark construction, evaluation, and deployment, designed to accommodate multiple development teams, mitigate overfitting risks, and assess the downstream impact of system modifications; and (3) a continual improvement strategy leveraging multidimensional evaluation, enabling the identification and implementation of diverse enhancement opportunities. By adopting this holistic framework, organizations can systematically enhance the reliability and performance of their AI Assistants, ensuring their efficacy in critical enterprise environments. We conclude by discussing how this multifaceted evaluation approach opens avenues for various classes of enhancements, paving the way for more robust and trustworthy AI systems.
Minimum-Norm Interpolation Under Covariate Shift
Mar 31, 2024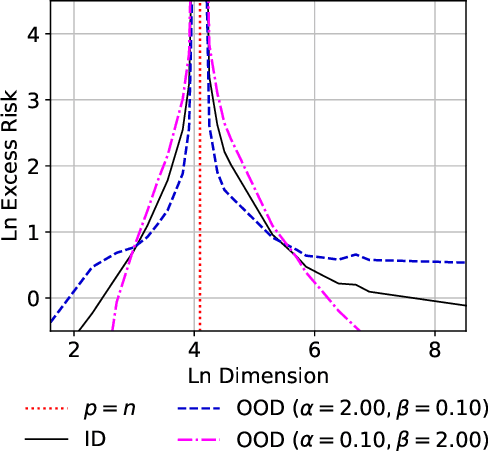
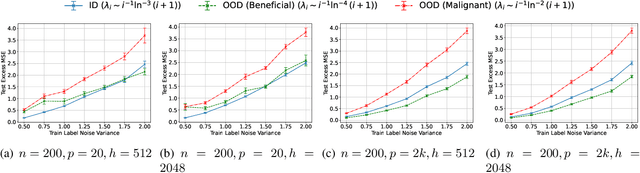
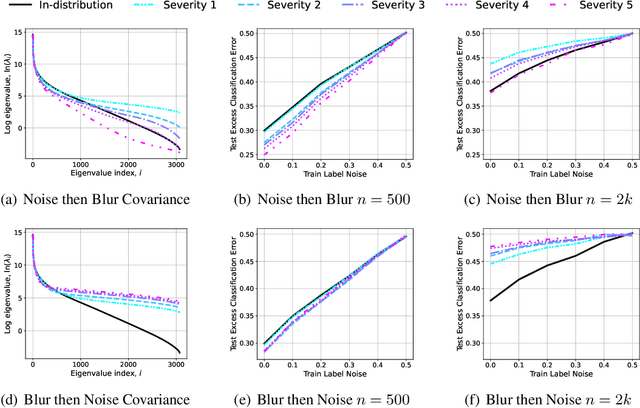
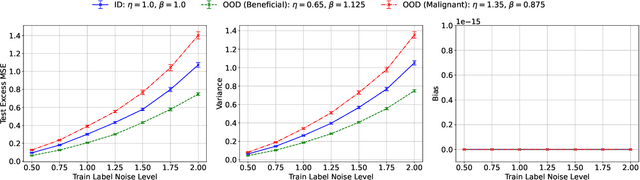
Transfer learning is a critical part of real-world machine learning deployments and has been extensively studied in experimental works with overparameterized neural networks. However, even in the simplest setting of linear regression a notable gap still exists in the theoretical understanding of transfer learning. In-distribution research on high-dimensional linear regression has led to the identification of a phenomenon known as \textit{benign overfitting}, in which linear interpolators overfit to noisy training labels and yet still generalize well. This behavior occurs under specific conditions on the source covariance matrix and input data dimension. Therefore, it is natural to wonder how such high-dimensional linear models behave under transfer learning. We prove the first non-asymptotic excess risk bounds for benignly-overfit linear interpolators in the transfer learning setting. From our analysis, we propose a taxonomy of \textit{beneficial} and \textit{malignant} covariate shifts based on the degree of overparameterization. We follow our analysis with empirical studies that show these beneficial and malignant covariate shifts for linear interpolators on real image data, and for fully-connected neural networks in settings where the input data dimension is larger than the training sample size.