 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented balancing weights as linear regression
Apr 27, 2023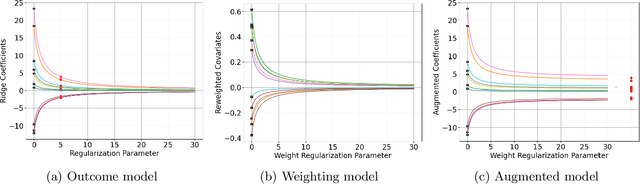
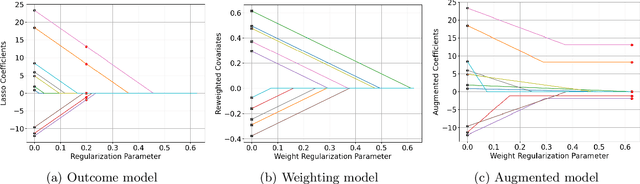
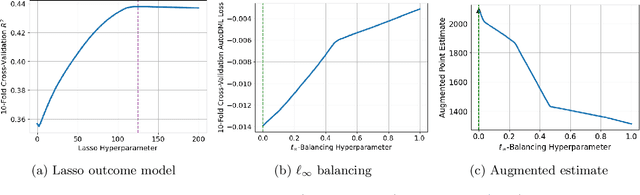
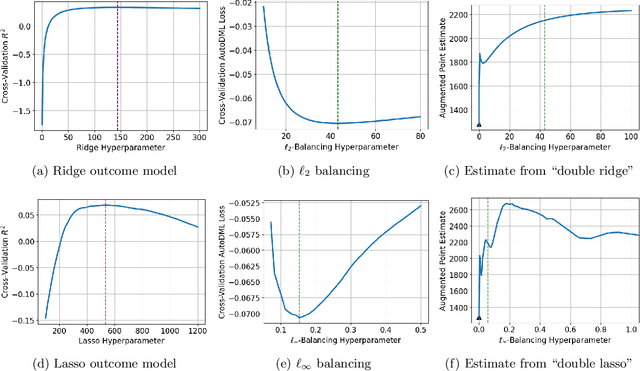
We provide a novel characterization of augmented balancing weights, also known as Automatic Debiased Machine Learning (AutoDML). These estimators combine outcome modeling with balancing weights, which estimate inverse propensity score weights directly. When the outcome and weighting models are both linear in some (possibly infinite) basis, we show that the augmented estimator is equivalent to a single linear model with coefficients that combine the original outcome model coefficients and OLS; in many settings, the augmented estimator collapses to OLS alone. We then extend these results to specific choices of outcome and weighting models. We first show that the combined estimator that uses (kernel) ridge regression for both outcome and weighting models is equivalent to a single, undersmoothed (kernel) ridge regression; this also holds when considering asymptotic rates. When the weighting model is instead lasso regression, we give closed-form expressions for special cases and demonstrate a ``double selection'' property. Finally, we generalize these results to linear estimands via the Riesz representer. Our framework ``opens the black box'' on these increasingly popular estimators and provides important insights into estimation choices for augmented balancing weights.
Assumption-lean inference for generalised linear model parameters
Jun 15, 2020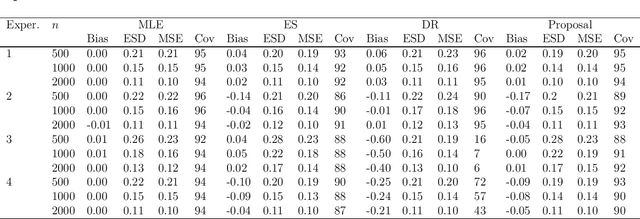
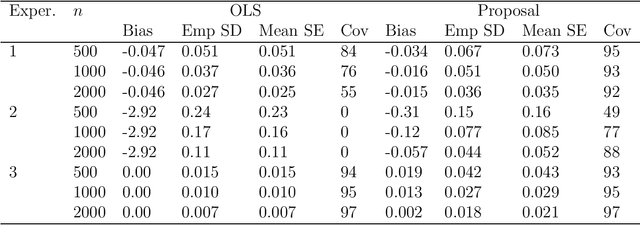
Inference for the parameters indexing generalised linear models is routinely based on the assumption that the model is correct and a priori specified. This is unsatisfactory because the chosen model is usually the result of a data-adaptive model selection process, which may induce excess uncertainty that is not usually acknowledged. Moreover, the assumptions encoded in the chosen model rarely represent some a priori known, ground truth, making standard inferences prone to bias, but also failing to give a pure reflection of the information that is contained in the data. Inspired by developments on assumption-free inference for so-called projection parameters, we here propose novel nonparametric definitions of main effect estimands and effect modification estimands. These reduce to standard main effect and effect modification parameters in generalised linear models when these models are correctly specified, but have the advantage that they continue to capture respectively the primary (conditional) association between two variables, or the degree to which two variables interact (in a statistical sense) in their effect on outcome, even when these models are misspecified. We achieve an assumption-lean inference for these estimands (and thus for the underlying regression parameters) by deriving their influence curve under the nonparametric model and invoking flexible data-adaptive (e.g., machine learning) procedures.