 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoGenBench: A Synthetic Multi-Camera Benchmark for Stereo Generation under Controlled Baseline Regimes
May 22, 2026Stereo image and video generation, stereo geometry estimation, and condition-controlled view synthesis require paired data in which the variables that determine binocular geometry -- camera baseline, intrinsics, scene depth, and camera motion -- are known and controllable. Existing stereo resources provide subsets of these variables, but resources commonly used for stereo generation evaluation do not, to our knowledge, provide scene-paired, calibrated multi-baseline right-view ground truth with jointly recorded intrinsics, dense metric depth, and per-frame poses in a single controlled source. We introduce StereoGenBench, a synthetic Unreal Engine benchmark designed to make baseline-regime sensitivity and target-camera consistency measurable under matched scene content. Each scene is rendered with a rigid six-camera lateral array, yielding up to 15 calibrated view pairs; adjacent baselines are sampled from inter-pupillary to wide-baseline regimes; focal length is sampled independently; and every view is released with RGB, metric depth, intrinsics, per-pair baselines, and per-frame poses. The splits include two evaluation families for narrow and wide baseline regimes and a train-only family for broader all-pairs coverage. We release the dataset, evaluation code, reference results, Croissant metadata, and generation code/configuration for extension with compatible assets. The dataset is available at https://huggingface.co/datasets/stereo-dataset/stereo-dataset
deadtrees.earth-aerial: A Multi-Resolution Aerial Image Dataset for Tree Cover and Mortality Detection
May 19, 2026Forests worldwide are increasingly threatened by climate change and disturbances such as fire, pests, and pathogens, creating an urgent need for scalable monitoring of tree cover and tree mortality. Aerial imagery from drones and aircraft is a key data source for detailed and large-scale mapping of tree crowns and mortality. However, related progress is limited by the lack of globally representative, harmonized datasets for joint segmentation of tree cover and mortality. We introduce two novel, open, machine-learning-ready datasets to enable joint segmentation of tree cover and tree mortality from centimeter-scale aerial imagery for the first time at global scales. With DTE-aerial-train, we provide a training dataset comprising 385K image patches of size 1024x1024 pixels, with resolutions ranging from 2.5 to 20 cm. It includes multi-class expert-annotated and -audited pseudo-labels for tree cover and mortality. With DTE-aerial-bench, we provide a geographically balanced benchmark test set of 25 globally distributed orthoimages totaling 525 patches with high-quality expert annotations for both tree cover and mortality. Both the training and benchmark datasets span tropical, temperate, boreal, and dryland biomes and cover a wide range of forest structures and mortality patterns. Using the benchmark test set for evaluation, we establish strong reference baselines that improve mortality segmentation across all biomes and scales with significant gains in challenging regions, such as boreal forests, where the F1 score increases from 0.40 to 0.58 with around 45% relative improvement. All data, models, and code will be publicly released under permissive open-source licenses. An interactive visualization of the benchmark dataset is available at deadtrees.earth/releases/dte-aerial-bench.
PRUE: A Practical Recipe for Field Boundary Segmentation at Scale
Mar 28, 2026Large-scale maps of field boundaries are essential for agricultural monitoring tasks. Existing deep learning approaches for satellite-based field mapping are sensitive to illumination, spatial scale, and changes in geographic location. We conduct the first systematic evaluation of segmentation and geospatial foundation models (GFMs) for global field boundary delineation using the Fields of The World (FTW) benchmark. We evaluate 18 models under unified experimental settings, showing that a U-Net semantic segmentation model outperforms instance-based and GFM alternatives on a suite of performance and deployment metrics. We propose a new segmentation approach that combines a U-Net backbone, composite loss functions, and targeted data augmentations to enhance performance and robustness under real-world conditions. Our model achieves a 76\% IoU and 47\% object-F1 on FTW, an increase of 6\% and 9\% over the previous baseline. Our approach provides a practical framework for reliable, scalable, and reproducible field boundary delineation across model design, training, and inference. We release all models and model-derived field boundary datasets for five countries.
GenOpticalFlow: A Generative Approach to Unsupervised Optical Flow Learning
Mar 23, 2026Optical flow estimation is a fundamental problem in computer vision, yet the reliance on expensive ground-truth annotations limits the scalability of supervised approaches. Although unsupervised and semi-supervised methods alleviate this issue, they often suffer from unreliable supervision signals based on brightness constancy and smoothness assumptions, leading to inaccurate motion estimation in complex real-world scenarios. To overcome these limitations, we introduce \textbf{\modelname}, a novel framework that synthesizes large-scale, perfectly aligned frame--flow data pairs for supervised optical flow training without human annotations. Specifically, our method leverages a pre-trained depth estimation network to generate pseudo optical flows, which serve as conditioning inputs for a next-frame generation model trained to produce high-fidelity, pixel-aligned subsequent frames. This process enables the creation of abundant, high-quality synthetic data with precise motion correspondence. Furthermore, we propose an \textit{inconsistent pixel filtering} strategy that identifies and removes unreliable pixels in generated frames, effectively enhancing fine-tuning performance on real-world datasets. Extensive experiments on KITTI2012, KITTI2015, and Sintel demonstrate that \textbf{\modelname} achieves competitive or superior results compared to existing unsupervised and semi-supervised approaches, highlighting its potential as a scalable and annotation-free solution for optical flow learning. We will release our code upon acceptance.
PhysAlign: Physics-Coherent Image-to-Video Generation through Feature and 3D Representation Alignment
Mar 14, 2026Video Diffusion Models (VDMs) offer a promising approach for simulating dynamic scenes and environments, with broad applications in robotics and media generation. However, existing models often generate temporally incoherent content that violates basic physical intuition, significantly limiting their practical applicability. We propose PhysAlign, an efficient framework for physics-coherent image-to-video (I2V) generation that explicitly addresses this limitation. To overcome the critical scarcity of physics-annotated videos, we first construct a fully controllable synthetic data generation pipeline based on rigid-body simulation, yielding a highly-curated dataset with accurate, fine-grained physics and 3D annotations. Leveraging this data, PhysAlign constructs a unified physical latent space by coupling explicit 3D geometry constraints with a Gram-based spatio-temporal relational alignment that extracts kinematic priors from video foundation models. Extensive experiments demonstrate that PhysAlign significantly outperforms existing VDMs on tasks requiring complex physical reasoning and temporal stability, without compromising zero-shot visual quality. PhysAlign shows the potential to bridge the gap between raw visual synthesis and rigid-body kinematics, establishing a practical paradigm for genuinely physics-grounded video generation. The project page is available at https://physalign.github.io/PhysAlign.
GeoDiT: Point-Conditioned Diffusion Transformer for Satellite Image Synthesis
Mar 02, 2026We introduce GeoDiT, a diffusion transformer designed for text-to-satellite image generation with point-based control. Existing controlled satellite image generative models often require pixel-level maps that are time-consuming to acquire, yet semantically limited. To address this limitation, we introduce a novel point-based conditioning framework that controls the generation process through the spatial location of the points and the textual description associated with each point, providing semantically rich control signals. This approach enables flexible, annotation-friendly, and computationally simple inference for satellite image generation. To this end, we introduce an adaptive local attention mechanism that effectively regularizes the attention scores based on the input point queries. We systematically evaluate various domain-specific design choices for training GeoDiT, including the selection of satellite image representation for alignment and geolocation representation for conditioning. Our experiments demonstrate that GeoDiT achieves impressive generation performance, surpassing the state-of-the-art remote sensing generative models.
SimLBR: Learning to Detect Fake Images by Learning to Detect Real Images
Feb 23, 2026The rapid advancement of generative models has made the detection of AI-generated images a critical challenge for both research and society. Recent works have shown that most state-of-the-art fake image detection methods overfit to their training data and catastrophically fail when evaluated on curated hard test sets with strong distribution shifts. In this work, we argue that it is more principled to learn a tight decision boundary around the real image distribution and treat the fake category as a sink class. To this end, we propose SimLBR, a simple and efficient framework for fake image detection using Latent Blending Regularization (LBR). Our method significantly improves cross-generator generalization, achieving up to +24.85\% accuracy and +69.62\% recall on the challenging Chameleon benchmark. SimLBR is also highly efficient, training orders of magnitude faster than existing approaches. Furthermore, we emphasize the need for reliability-oriented evaluation in fake image detection, introducing risk-adjusted metrics and worst-case estimates to better assess model robustness. All code and models will be released on HuggingFace and GitHub.
UniDrive-WM: Unified Understanding, Planning and Generation World Model For Autonomous Driving
Jan 07, 2026World models have become central to autonomous driving, where accurate scene understanding and future prediction are crucial for safe control. Recent work has explored using vision-language models (VLMs) for planning, yet existing approaches typically treat perception, prediction, and planning as separate modules. We propose UniDrive-WM, a unified VLM-based world model that jointly performs driving-scene understanding, trajectory planning, and trajectory-conditioned future image generation within a single architecture. UniDrive-WM's trajectory planner predicts a future trajectory, which conditions a VLM-based image generator to produce plausible future frames. These predictions provide additional supervisory signals that enhance scene understanding and iteratively refine trajectory generation. We further compare discrete and continuous output representations for future image prediction, analyzing their influence on downstream driving performance. Experiments on the challenging Bench2Drive benchmark show that UniDrive-WM produces high-fidelity future images and improves planning performance by 5.9% in L2 trajectory error and 9.2% in collision rate over the previous best method. These results demonstrate the advantages of tightly integrating VLM-driven reasoning, planning, and generative world modeling for autonomous driving. The project page is available at https://unidrive-wm.github.io/UniDrive-WM .
VectorSynth: Fine-Grained Satellite Image Synthesis with Structured Semantics
Nov 11, 2025We introduce VectorSynth, a diffusion-based framework for pixel-accurate satellite image synthesis conditioned on polygonal geographic annotations with semantic attributes. Unlike prior text- or layout-conditioned models, VectorSynth learns dense cross-modal correspondences that align imagery and semantic vector geometry, enabling fine-grained, spatially grounded edits. A vision language alignment module produces pixel-level embeddings from polygon semantics; these embeddings guide a conditional image generation framework to respect both spatial extents and semantic cues. VectorSynth supports interactive workflows that mix language prompts with geometry-aware conditioning, allowing rapid what-if simulations, spatial edits, and map-informed content generation. For training and evaluation, we assemble a collection of satellite scenes paired with pixel-registered polygon annotations spanning diverse urban scenes with both built and natural features. We observe strong improvements over prior methods in semantic fidelity and structural realism, and show that our trained vision language model demonstrates fine-grained spatial grounding. The code and data are available at https://github.com/mvrl/VectorSynth.
Beta Distribution Learning for Reliable Roadway Crash Risk Assessment
Nov 07, 2025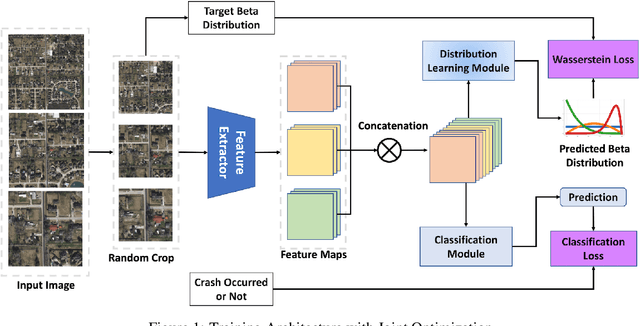

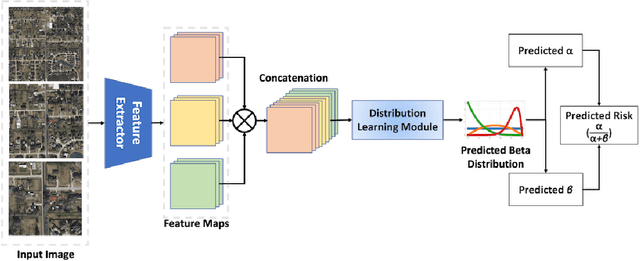

Roadway traffic accidents represent a global health crisis, responsible for over a million deaths annually and costing many countries up to 3% of their GDP. Traditional traffic safety studies often examine risk factors in isolation, overlooking the spatial complexity and contextual interactions inherent in the built environment. Furthermore, conventional Neural Network-based risk estimators typically generate point estimates without conveying model uncertainty, limiting their utility in critical decision-making. To address these shortcomings, we introduce a novel geospatial deep learning framework that leverages satellite imagery as a comprehensive spatial input. This approach enables the model to capture the nuanced spatial patterns and embedded environmental risk factors that contribute to fatal crash risks. Rather than producing a single deterministic output, our model estimates a full Beta probability distribution over fatal crash risk, yielding accurate and uncertainty-aware predictions--a critical feature for trustworthy AI in safety-critical applications. Our model outperforms baselines by achieving a 17-23% improvement in recall, a key metric for flagging potential dangers, while delivering superior calibration. By providing reliable and interpretable risk assessments from satellite imagery alone, our method enables safer autonomous navigation and offers a highly scalable tool for urban planners and policymakers to enhance roadway safety equitably and cost-effectively.