 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSat2Sound: A Unified Framework for Zero-Shot Soundscape Mapping
May 19, 2025We present Sat2Sound, a multimodal representation learning framework for soundscape mapping, designed to predict the distribution of sounds at any location on Earth. Existing methods for this task rely on satellite image and paired geotagged audio samples, which often fail to capture the diversity of sound sources at a given location. To address this limitation, we enhance existing datasets by leveraging a Vision-Language Model (VLM) to generate semantically rich soundscape descriptions for locations depicted in satellite images. Our approach incorporates contrastive learning across audio, audio captions, satellite images, and satellite image captions. We hypothesize that there is a fixed set of soundscape concepts shared across modalities. To this end, we learn a shared codebook of soundscape concepts and represent each sample as a weighted average of these concepts. Sat2Sound achieves state-of-the-art performance in cross-modal retrieval between satellite image and audio on two datasets: GeoSound and SoundingEarth. Additionally, building on Sat2Sound's ability to retrieve detailed soundscape captions, we introduce a novel application: location-based soundscape synthesis, which enables immersive acoustic experiences. Our code and models will be publicly available.
RANGE: Retrieval Augmented Neural Fields for Multi-Resolution Geo-Embeddings
Feb 27, 2025The choice of representation for geographic location significantly impacts the accuracy of models for a broad range of geospatial tasks, including fine-grained species classification, population density estimation, and biome classification. Recent works like SatCLIP and GeoCLIP learn such representations by contrastively aligning geolocation with co-located images. While these methods work exceptionally well, in this paper, we posit that the current training strategies fail to fully capture the important visual features. We provide an information theoretic perspective on why the resulting embeddings from these methods discard crucial visual information that is important for many downstream tasks. To solve this problem, we propose a novel retrieval-augmented strategy called RANGE. We build our method on the intuition that the visual features of a location can be estimated by combining the visual features from multiple similar-looking locations. We evaluate our method across a wide variety of tasks. Our results show that RANGE outperforms the existing state-of-the-art models with significant margins in most tasks. We show gains of up to 13.1\% on classification tasks and 0.145 $R^2$ on regression tasks. All our code will be released on GitHub. Our models will be released on HuggingFace.
TaxaBind: A Unified Embedding Space for Ecological Applications
Nov 01, 2024
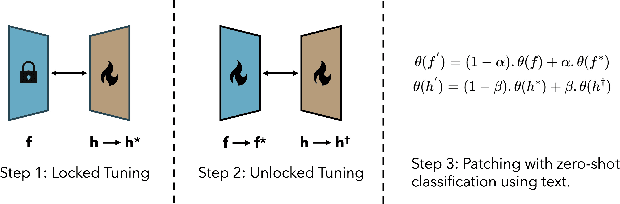

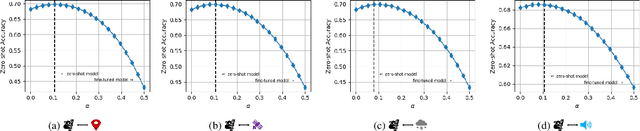
We present TaxaBind, a unified embedding space for characterizing any species of interest. TaxaBind is a multimodal embedding space across six modalities: ground-level images of species, geographic location, satellite image, text, audio, and environmental features, useful for solving ecological problems. To learn this joint embedding space, we leverage ground-level images of species as a binding modality. We propose multimodal patching, a technique for effectively distilling the knowledge from various modalities into the binding modality. We construct two large datasets for pretraining: iSatNat with species images and satellite images, and iSoundNat with species images and audio. Additionally, we introduce TaxaBench-8k, a diverse multimodal dataset with six paired modalities for evaluating deep learning models on ecological tasks. Experiments with TaxaBind demonstrate its strong zero-shot and emergent capabilities on a range of tasks including species classification, cross-model retrieval, and audio classification. The datasets and models are made available at https://github.com/mvrl/TaxaBind.
Fields of The World: A Machine Learning Benchmark Dataset For Global Agricultural Field Boundary Segmentation
Sep 24, 2024



Crop field boundaries are foundational datasets for agricultural monitoring and assessments but are expensive to collect manually. Machine learning (ML) methods for automatically extracting field boundaries from remotely sensed images could help realize the demand for these datasets at a global scale. However, current ML methods for field instance segmentation lack sufficient geographic coverage, accuracy, and generalization capabilities. Further, research on improving ML methods is restricted by the lack of labeled datasets representing the diversity of global agricultural fields. We present Fields of The World (FTW) -- a novel ML benchmark dataset for agricultural field instance segmentation spanning 24 countries on four continents (Europe, Africa, Asia, and South America). FTW is an order of magnitude larger than previous datasets with 70,462 samples, each containing instance and semantic segmentation masks paired with multi-date, multi-spectral Sentinel-2 satellite images. We provide results from baseline models for the new FTW benchmark, show that models trained on FTW have better zero-shot and fine-tuning performance in held-out countries than models that aren't pre-trained with diverse datasets, and show positive qualitative zero-shot results of FTW models in a real-world scenario -- running on Sentinel-2 scenes over Ethiopia.
PSM: Learning Probabilistic Embeddings for Multi-scale Zero-Shot Soundscape Mapping
Aug 13, 2024A soundscape is defined by the acoustic environment a person perceives at a location. In this work, we propose a framework for mapping soundscapes across the Earth. Since soundscapes involve sound distributions that span varying spatial scales, we represent locations with multi-scale satellite imagery and learn a joint representation among this imagery, audio, and text. To capture the inherent uncertainty in the soundscape of a location, we design the representation space to be probabilistic. We also fuse ubiquitous metadata (including geolocation, time, and data source) to enable learning of spatially and temporally dynamic representations of soundscapes. We demonstrate the utility of our framework by creating large-scale soundscape maps integrating both audio and text with temporal control. To facilitate future research on this task, we also introduce a large-scale dataset, GeoSound, containing over $300k$ geotagged audio samples paired with both low- and high-resolution satellite imagery. We demonstrate that our method outperforms the existing state-of-the-art on both GeoSound and the existing SoundingEarth dataset. Our dataset and code is available at https://github.com/mvrl/PSM.
GEOBIND: Binding Text, Image, and Audio through Satellite Images
Apr 17, 2024In remote sensing, we are interested in modeling various modalities for some geographic location. Several works have focused on learning the relationship between a location and type of landscape, habitability, audio, textual descriptions, etc. Recently, a common way to approach these problems is to train a deep-learning model that uses satellite images to infer some unique characteristics of the location. In this work, we present a deep-learning model, GeoBind, that can infer about multiple modalities, specifically text, image, and audio, from satellite imagery of a location. To do this, we use satellite images as the binding element and contrastively align all other modalities to the satellite image data. Our training results in a joint embedding space with multiple types of data: satellite image, ground-level image, audio, and text. Furthermore, our approach does not require a single complex dataset that contains all the modalities mentioned above. Rather it only requires multiple satellite-image paired data. While we only align three modalities in this paper, we present a general framework that can be used to create an embedding space with any number of modalities by using satellite images as the binding element. Our results show that, unlike traditional unimodal models, GeoBind is versatile and can reason about multiple modalities for a given satellite image input.
LD-SDM: Language-Driven Hierarchical Species Distribution Modeling
Dec 13, 2023



We focus on the problem of species distribution modeling using global-scale presence-only data. Most previous studies have mapped the range of a given species using geographical and environmental features alone. To capture a stronger implicit relationship between species, we encode the taxonomic hierarchy of species using a large language model. This enables range mapping for any taxonomic rank and unseen species without additional supervision. Further, we propose a novel proximity-aware evaluation metric that enables evaluating species distribution models using any pixel-level representation of ground-truth species range map. The proposed metric penalizes the predictions of a model based on its proximity to the ground truth. We describe the effectiveness of our model by systematically evaluating on the task of species range prediction, zero-shot prediction and geo-feature regression against the state-of-the-art. Results show our model outperforms the strong baselines when trained with a variety of multi-label learning losses.
Sat2Cap: Mapping Fine-Grained Textual Descriptions from Satellite Images
Jul 29, 2023



We propose a novel weakly supervised approach for creating maps using free-form textual descriptions (or captions). We refer to this new line of work of creating textual maps as zero-shot mapping. Prior works have approached mapping tasks by developing models that predict over a fixed set of attributes using overhead imagery. However, these models are very restrictive as they can only solve highly specific tasks for which they were trained. Mapping text, on the other hand, allows us to solve a large variety of mapping problems with minimal restrictions. To achieve this, we train a contrastive learning framework called Sat2Cap on a new large-scale dataset of paired overhead and ground-level images. For a given location, our model predicts the expected CLIP embedding of the ground-level scenery. Sat2Cap is also conditioned on temporal information, enabling it to learn dynamic concepts that vary over time. Our experimental results demonstrate that our models successfully capture fine-grained concepts and effectively adapt to temporal variations. Our approach does not require any text-labeled data making the training easily scalable. The code, dataset, and models will be made publicly available.