 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Head LatentMoE and Head Parallel: Communication-Efficient and Deterministic MoE Parallelism
Feb 04, 2026Large language models have transformed many applications but remain expensive to train. Sparse Mixture of Experts (MoE) addresses this through conditional computation, with Expert Parallel (EP) as the standard distributed training method. However, EP has three limitations: communication cost grows linearly with the number of activated experts $k$, load imbalance affects latency and memory usage, and data-dependent communication requires metadata exchange. We propose Multi-Head LatentMoE and Head Parallel (HP), a new architecture and parallelism achieving $O(1)$ communication cost regardless of $k$, completely balanced traffic, and deterministic communication, all while remaining compatible with EP. To accelerate Multi-Head LatentMoE, we propose IO-aware routing and expert computation. Compared to MoE with EP, Multi-Head LatentMoE with HP trains up to $1.61\times$ faster while having identical performance. With doubled granularity, it achieves higher overall performance while still being $1.11\times$ faster. Our method makes multi-billion-parameter foundation model research more accessible.
GEO-Bench-2: From Performance to Capability, Rethinking Evaluation in Geospatial AI
Nov 19, 2025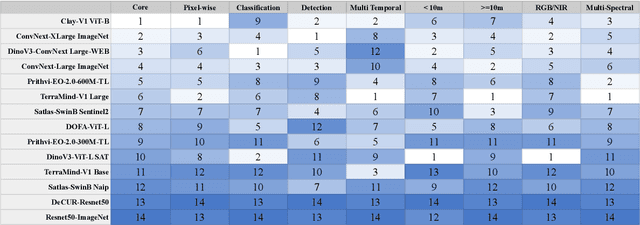
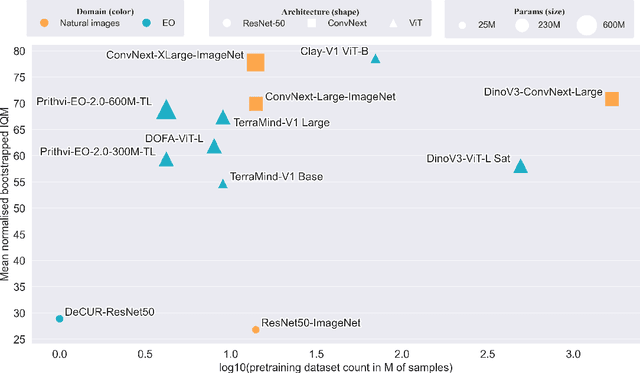
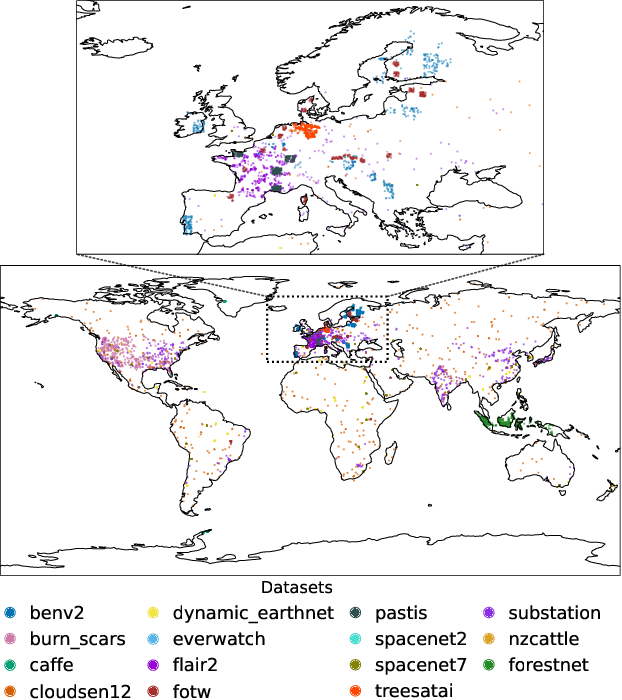
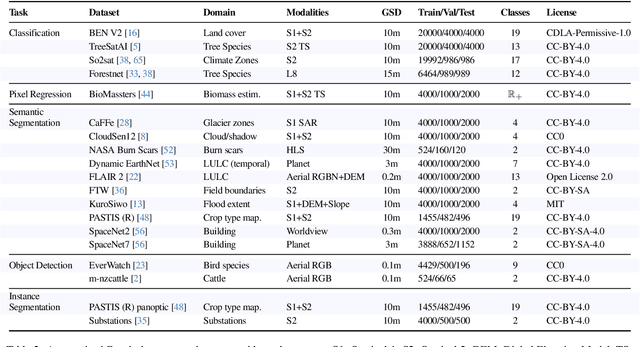
Geospatial Foundation Models (GeoFMs) are transforming Earth Observation (EO), but evaluation lacks standardized protocols. GEO-Bench-2 addresses this with a comprehensive framework spanning classification, segmentation, regression, object detection, and instance segmentation across 19 permissively-licensed datasets. We introduce ''capability'' groups to rank models on datasets that share common characteristics (e.g., resolution, bands, temporality). This enables users to identify which models excel in each capability and determine which areas need improvement in future work. To support both fair comparison and methodological innovation, we define a prescriptive yet flexible evaluation protocol. This not only ensures consistency in benchmarking but also facilitates research into model adaptation strategies, a key and open challenge in advancing GeoFMs for downstream tasks. Our experiments show that no single model dominates across all tasks, confirming the specificity of the choices made during architecture design and pretraining. While models pretrained on natural images (ConvNext ImageNet, DINO V3) excel on high-resolution tasks, EO-specific models (TerraMind, Prithvi, and Clay) outperform them on multispectral applications such as agriculture and disaster response. These findings demonstrate that optimal model choice depends on task requirements, data modalities, and constraints. This shows that the goal of a single GeoFM model that performs well across all tasks remains open for future research. GEO-Bench-2 enables informed, reproducible GeoFM evaluation tailored to specific use cases. Code, data, and leaderboard for GEO-Bench-2 are publicly released under a permissive license.
OlmoEarth: Stable Latent Image Modeling for Multimodal Earth Observation
Nov 17, 2025Earth observation data presents a unique challenge: it is spatial like images, sequential like video or text, and highly multimodal. We present OlmoEarth: a multimodal, spatio-temporal foundation model that employs a novel self-supervised learning formulation, masking strategy, and loss all designed for the Earth observation domain. OlmoEarth achieves state-of-the-art performance compared to 12 other foundation models across a variety of research benchmarks and real-world tasks from external partners. When evaluating embeddings OlmoEarth achieves the best performance on 15 out of 24 tasks, and with full fine-tuning it is the best on 19 of 29 tasks. We deploy OlmoEarth as the backbone of an end-to-end platform for data collection, labeling, training, and inference of Earth observation models. The OlmoEarth Platform puts frontier foundation models and powerful data management tools into the hands of non-profits and NGOs working to solve the world's biggest problems. OlmoEarth source code, training data, and pre-trained weights are available at $\href{https://github.com/allenai/olmoearth_pretrain}{\text{https://github.com/allenai/olmoearth_pretrain}}$.
DataS^3: Dataset Subset Selection for Specialization
Apr 22, 2025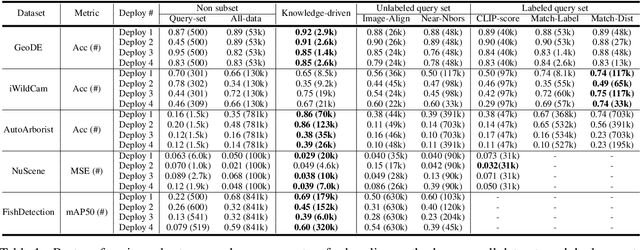
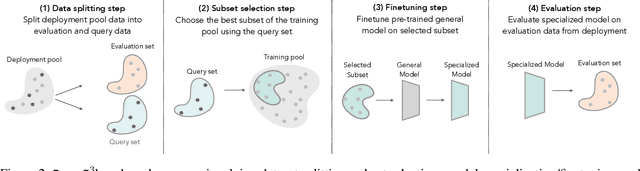
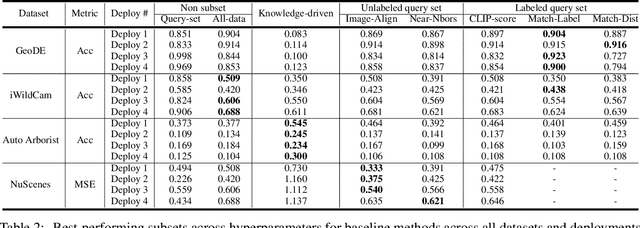
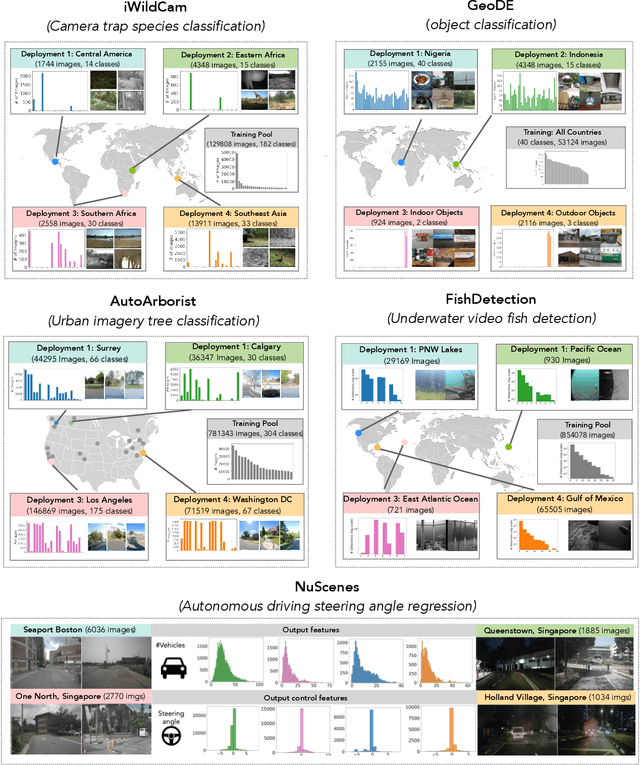
In many real-world machine learning (ML) applications (e.g. detecting broken bones in x-ray images, detecting species in camera traps), in practice models need to perform well on specific deployments (e.g. a specific hospital, a specific national park) rather than the domain broadly. However, deployments often have imbalanced, unique data distributions. Discrepancy between the training distribution and the deployment distribution can lead to suboptimal performance, highlighting the need to select deployment-specialized subsets from the available training data. We formalize dataset subset selection for specialization (DS3): given a training set drawn from a general distribution and a (potentially unlabeled) query set drawn from the desired deployment-specific distribution, the goal is to select a subset of the training data that optimizes deployment performance. We introduce DataS^3; the first dataset and benchmark designed specifically for the DS3 problem. DataS^3 encompasses diverse real-world application domains, each with a set of distinct deployments to specialize in. We conduct a comprehensive study evaluating algorithms from various families--including coresets, data filtering, and data curation--on DataS^3, and find that general-distribution methods consistently fail on deployment-specific tasks. Additionally, we demonstrate the existence of manually curated (deployment-specific) expert subsets that outperform training on all available data with accuracy gains up to 51.3 percent. Our benchmark highlights the critical role of tailored dataset curation in enhancing performance and training efficiency on deployment-specific distributions, which we posit will only become more important as global, public datasets become available across domains and ML models are deployed in the real world.
Measuring directional bias amplification in image captions using predictability
Mar 10, 2025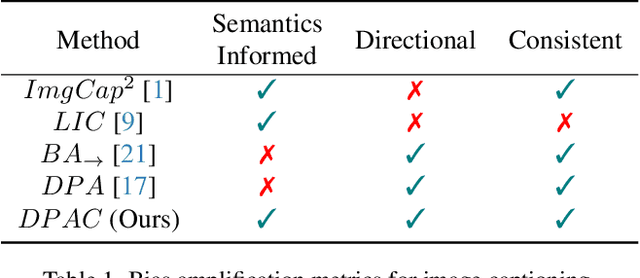
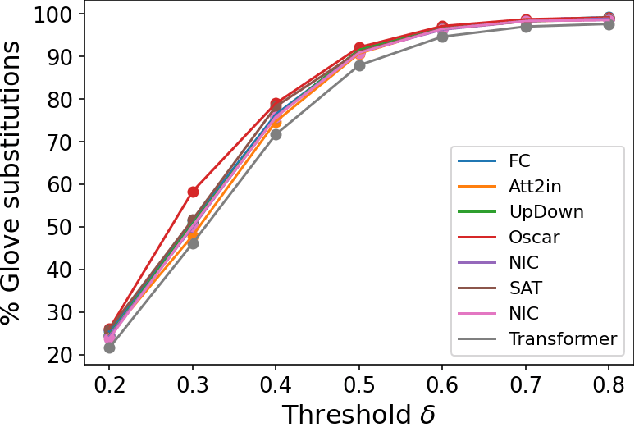
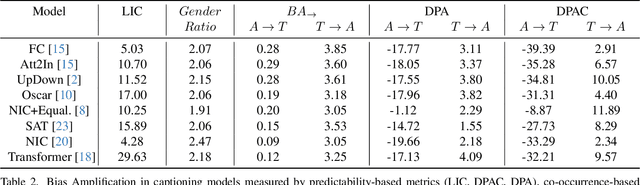
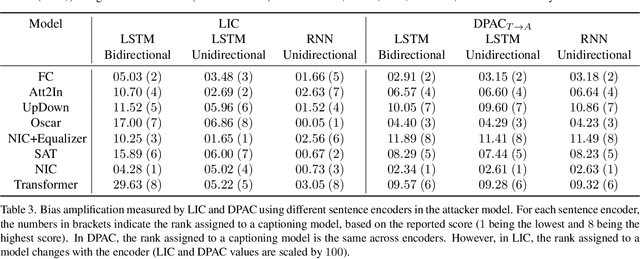
When we train models on biased ML datasets, they not only learn these biases but can inflate them at test time - a phenomenon called bias amplification. To measure bias amplification in ML datasets, many co-occurrence-based metrics have been proposed. Co-occurrence-based metrics are effective in measuring bias amplification in simple problems like image classification. However, these metrics are ineffective for complex problems like image captioning as they cannot capture the semantics of a caption. To measure bias amplification in captions, prior work introduced a predictability-based metric called Leakage in Captioning (LIC). While LIC captures the semantics and context of captions, it has limitations. LIC cannot identify the direction in which bias is amplified, poorly estimates dataset bias due to a weak vocabulary substitution strategy, and is highly sensitive to attacker models (a hyperparameter in predictability-based metrics). To overcome these issues, we propose Directional Predictability Amplification in Captioning (DPAC). DPAC measures directional bias amplification in captions, provides a better estimate of dataset bias using an improved substitution strategy, and is less sensitive to attacker models. Our experiments on the COCO captioning dataset show how DPAC is the most reliable metric to measure bias amplification in captions.
Galileo: Learning Global and Local Features in Pretrained Remote Sensing Models
Feb 13, 2025From crop mapping to flood detection, machine learning in remote sensing has a wide range of societally beneficial applications. The commonalities between remote sensing data in these applications present an opportunity for pretrained machine learning models tailored to remote sensing to reduce the labeled data and effort required to solve individual tasks. However, such models must be: (i) flexible enough to ingest input data of varying sensor modalities and shapes (i.e., of varying spatial and temporal dimensions), and (ii) able to model Earth surface phenomena of varying scales and types. To solve this gap, we present Galileo, a family of pretrained remote sensing models designed to flexibly process multimodal remote sensing data. We also introduce a novel and highly effective self-supervised learning approach to learn both large- and small-scale features, a challenge not addressed by previous models. Our Galileo models obtain state-of-the-art results across diverse remote sensing tasks.
Making Bias Amplification in Balanced Datasets Directional and Interpretable
Dec 15, 2024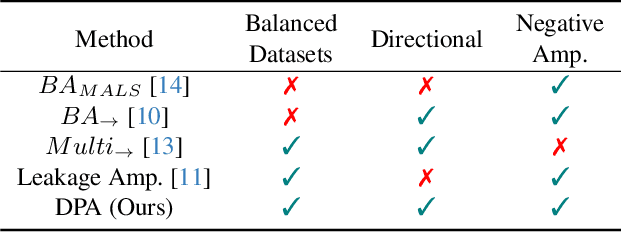
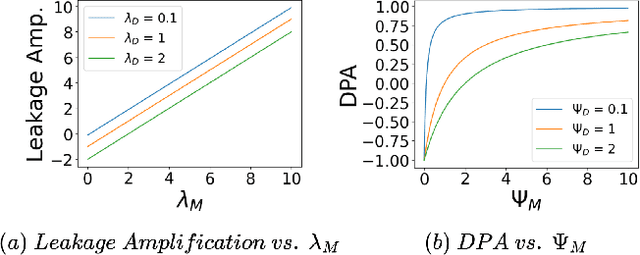

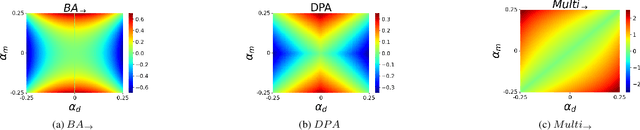
Most of the ML datasets we use today are biased. When we train models on these biased datasets, they often not only learn dataset biases but can also amplify them -- a phenomenon known as bias amplification. Several co-occurrence-based metrics have been proposed to measure bias amplification between a protected attribute A (e.g., gender) and a task T (e.g., cooking). However, these metrics fail to measure biases when A is balanced with T. To measure bias amplification in balanced datasets, recent work proposed a predictability-based metric called leakage amplification. However, leakage amplification cannot identify the direction in which biases are amplified. In this work, we propose a new predictability-based metric called directional predictability amplification (DPA). DPA measures directional bias amplification, even for balanced datasets. Unlike leakage amplification, DPA is easier to interpret and less sensitive to attacker models (a hyperparameter in predictability-based metrics). Our experiments on tabular and image datasets show that DPA is an effective metric for measuring directional bias amplification. The code will be available soon.
Classification Drives Geographic Bias in Street Scene Segmentation
Dec 15, 2024



Previous studies showed that image datasets lacking geographic diversity can lead to biased performance in models trained on them. While earlier work studied general-purpose image datasets (e.g., ImageNet) and simple tasks like image recognition, we investigated geo-biases in real-world driving datasets on a more complex task: instance segmentation. We examined if instance segmentation models trained on European driving scenes (Eurocentric models) are geo-biased. Consistent with previous work, we found that Eurocentric models were geo-biased. Interestingly, we found that geo-biases came from classification errors rather than localization errors, with classification errors alone contributing 10-90% of the geo-biases in segmentation and 19-88% of the geo-biases in detection. This showed that while classification is geo-biased, localization (including detection and segmentation) is geographically robust. Our findings show that in region-specific models (e.g., Eurocentric models), geo-biases from classification errors can be significantly mitigated by using coarser classes (e.g., grouping car, bus, and truck as 4-wheeler).
Fields of The World: A Machine Learning Benchmark Dataset For Global Agricultural Field Boundary Segmentation
Sep 24, 2024



Crop field boundaries are foundational datasets for agricultural monitoring and assessments but are expensive to collect manually. Machine learning (ML) methods for automatically extracting field boundaries from remotely sensed images could help realize the demand for these datasets at a global scale. However, current ML methods for field instance segmentation lack sufficient geographic coverage, accuracy, and generalization capabilities. Further, research on improving ML methods is restricted by the lack of labeled datasets representing the diversity of global agricultural fields. We present Fields of The World (FTW) -- a novel ML benchmark dataset for agricultural field instance segmentation spanning 24 countries on four continents (Europe, Africa, Asia, and South America). FTW is an order of magnitude larger than previous datasets with 70,462 samples, each containing instance and semantic segmentation masks paired with multi-date, multi-spectral Sentinel-2 satellite images. We provide results from baseline models for the new FTW benchmark, show that models trained on FTW have better zero-shot and fine-tuning performance in held-out countries than models that aren't pre-trained with diverse datasets, and show positive qualitative zero-shot results of FTW models in a real-world scenario -- running on Sentinel-2 scenes over Ethiopia.
Causal machine learning for sustainable agroecosystems
Aug 23, 2024

In a changing climate, sustainable agriculture is essential for food security and environmental health. However, it is challenging to understand the complex interactions among its biophysical, social, and economic components. Predictive machine learning (ML), with its capacity to learn from data, is leveraged in sustainable agriculture for applications like yield prediction and weather forecasting. Nevertheless, it cannot explain causal mechanisms and remains descriptive rather than prescriptive. To address this gap, we propose causal ML, which merges ML's data processing with causality's ability to reason about change. This facilitates quantifying intervention impacts for evidence-based decision-making and enhances predictive model robustness. We showcase causal ML through eight diverse applications that benefit stakeholders across the agri-food chain, including farmers, policymakers, and researchers.