 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Unsupervised Downscaling of Climate Models via Domain Alignment: Application to Wind Fields
Apr 03, 2026General Circulation Models (GCMs) are widely used for future climate projections, but their coarse spatial resolution and systematic biases limit their direct use for impact studies. This limitation is particularly critical for wind-related applications, such as wind energy, which require spatially coherent, multivariate, and physically plausible near-surface wind fields. Classical statistical downscaling and bias correction methods partly address this issue. Still, they struggle to preserve spatial structure, inter-variable consistency, and robustness under climate change, especially in high-dimensional settings. Recent advances in generative machine learning offer new opportunities for downscaling and bias correction, eliminating the need for explicitly paired low- and high-resolution datasets. However, many existing approaches remain difficult to interpret and challenging to deploy in operational climate impact studies. In this work, we apply SerpentFlow, an interpretable, generative, domain alignment framework, to the multivariate downscaling and bias correction of wind variables from GCM outputs. This is a method that generates low-resolution/high-resolution training data pairs by separating large-scale spatial patterns from small-scale variability. Large-scale components are aligned across climate model and observational domains. Conditional fine-scale variability is then learned using a flow-matching generative model. We apply the approach to multiple wind variables downscaling, including average and maximal wind speed, zonal and meridional components, and compare it with widely used multivariate bias correction methods. Results show improved spatial coherence, inter-variable consistency, and robustness under future climate conditions, highlighting the potential of interpretable generative models for wind and energy applications.
Flickering Multi-Armed Bandits
Feb 19, 2026We introduce Flickering Multi-Armed Bandits (FMAB), a new MAB framework where the set of available arms (or actions) can change at each round, and the available set at any time may depend on the agent's previously selected arm. We model this constrained, evolving availability using random graph processes, where arms are nodes and the agent's movement is restricted to its local neighborhood. We analyze this problem under two random graph models: an i.i.d. Erdős--Rényi (ER) process and an Edge-Markovian process. We propose and analyze a two-phase algorithm that employs a lazy random walk for exploration to efficiently identify the optimal arm, followed by a navigation and commitment phase for exploitation. We establish high-probability and expected sublinear regret bounds for both graph settings. We show that the exploration cost of our algorithm is near-optimal by establishing a matching information-theoretic lower bound for this problem class, highlighting the fundamental cost of exploration under local-move constraints. We complement our theoretical guarantees with numerical simulations, including a scenario of a robotic ground vehicle scouting a disaster-affected region.
A Unified Framework for Locality in Scalable MARL
Feb 19, 2026Scalable Multi-Agent Reinforcement Learning (MARL) is fundamentally challenged by the curse of dimensionality. A common solution is to exploit locality, which hinges on an Exponential Decay Property (EDP) of the value function. However, existing conditions that guarantee the EDP are often conservative, as they are based on worst-case, environment-only bounds (e.g., supremums over actions) and fail to capture the regularizing effect of the policy itself. In this work, we establish that locality can also be a \emph{policy-dependent} phenomenon. Our central contribution is a novel decomposition of the policy-induced interdependence matrix, $H^π$, which decouples the environment's sensitivity to state ($E^{\mathrm{s}}$) and action ($E^{\mathrm{a}}$) from the policy's sensitivity to state ($Π(π)$). This decomposition reveals that locality can be induced by a smooth policy (small $Π(π)$) even when the environment is strongly action-coupled, exposing a fundamental locality-optimality tradeoff. We use this framework to derive a general spectral condition $ρ(E^{\mathrm{s}}+E^{\mathrm{a}}Π(π)) < 1$ for exponential decay, which is strictly tighter than prior norm-based conditions. Finally, we leverage this theory to analyze a provably-sound localized block-coordinate policy improvement framework with guarantees tied directly to this spectral radius.
Multi-Agent Lipschitz Bandits
Feb 18, 2026We study the decentralized multi-player stochastic bandit problem over a continuous, Lipschitz-structured action space where hard collisions yield zero reward. Our objective is to design a communication-free policy that maximizes collective reward, with coordination costs that are independent of the time horizon $T$. We propose a modular protocol that first solves the multi-agent coordination problem -- identifying and seating players on distinct high-value regions via a novel maxima-directed search -- and then decouples the problem into $N$ independent single-player Lipschitz bandits. We establish a near-optimal regret bound of $\tilde{O}(T^{(d+1)/(d+2)})$ plus a $T$-independent coordination cost, matching the single-player rate. To our knowledge, this is the first framework providing such guarantees, and it extends to general distance-threshold collision models.
STIPP: Space-time in situ postprocessing over the French Alps using proper scoring rules
Jan 06, 2026We propose Space-time in situ postprocessing (STIPP), a machine learning model that generates spatio-temporally consistent weather forecasts for a network of station locations. Gridded forecasts from classical numerical weather prediction or data-driven models often lack the necessary precision due to unresolved local effects. Typical statistical postprocessing methods correct these biases, but often degrade spatio-temporal correlation structures in doing so. Recent works based on generative modeling successfully improve spatial correlation structures but have to forecast every lead time independently. In contrast, STIPP makes joint spatio-temporal forecasts which have increased accuracy for surface temperature, wind, relative humidity and precipitation when compared to baseline methods. It makes hourly ensemble predictions given only a six-hourly deterministic forecast, blending the boundaries of postprocessing and temporal interpolation. By leveraging a multivariate proper scoring rule for training, STIPP contributes to ongoing work data-driven atmospheric models supervised only with distribution marginals.
SerpentFlow: Generative Unpaired Domain Alignment via Shared-Structure Decomposition
Jan 05, 2026Domain alignment refers broadly to learning correspondences between data distributions from distinct domains. In this work, we focus on a setting where domains share underlying structural patterns despite differences in their specific realizations. The task is particularly challenging in the absence of paired observations, which removes direct supervision across domains. We introduce a generative framework, called SerpentFlow (SharEd-structuRe decomPosition for gEnerative domaiN adapTation), for unpaired domain alignment. SerpentFlow decomposes data within a latent space into a shared component common to both domains and a domain-specific one. By isolating the shared structure and replacing the domain-specific component with stochastic noise, we construct synthetic training pairs between shared representations and target-domain samples, thereby enabling the use of conditional generative models that are traditionally restricted to paired settings. We apply this approach to super-resolution tasks, where the shared component naturally corresponds to low-frequency content while high-frequency details capture domain-specific variability. The cutoff frequency separating low- and high-frequency components is determined automatically using a classifier-based criterion, ensuring a data-driven and domain-adaptive decomposition. By generating pseudo-pairs that preserve low-frequency structures while injecting stochastic high-frequency realizations, we learn the conditional distribution of the target domain given the shared representation. We implement SerpentFlow using Flow Matching as the generative pipeline, although the framework is compatible with other conditional generative approaches. Experiments on synthetic images, physical process simulations, and a climate downscaling task demonstrate that the method effectively reconstructs high-frequency structures consistent with underlying low-frequency patterns, supporting shared-structure decomposition as an effective strategy for unpaired domain alignment.
ArchesClimate: Probabilistic Decadal Ensemble Generation With Flow Matching
Sep 19, 2025Climate projections have uncertainties related to components of the climate system and their interactions. A typical approach to quantifying these uncertainties is to use climate models to create ensembles of repeated simulations under different initial conditions. Due to the complexity of these simulations, generating such ensembles of projections is computationally expensive. In this work, we present ArchesClimate, a deep learning-based climate model emulator that aims to reduce this cost. ArchesClimate is trained on decadal hindcasts of the IPSL-CM6A-LR climate model at a spatial resolution of approximately 2.5x1.25 degrees. We train a flow matching model following ArchesWeatherGen, which we adapt to predict near-term climate. Once trained, the model generates states at a one-month lead time and can be used to auto-regressively emulate climate model simulations of any length. We show that for up to 10 years, these generations are stable and physically consistent. We also show that for several important climate variables, ArchesClimate generates simulations that are interchangeable with the IPSL model. This work suggests that climate model emulators could significantly reduce the cost of climate model simulations.
Incentivized Lipschitz Bandits
Aug 26, 2025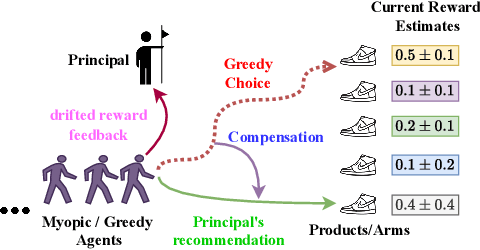
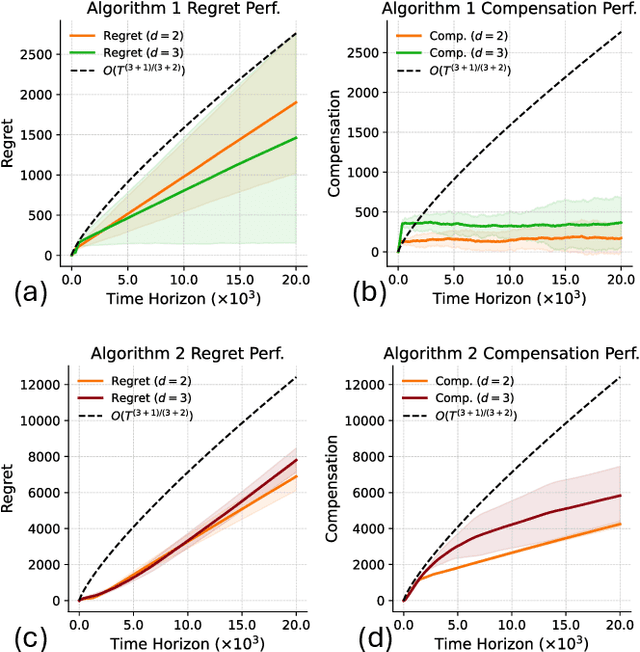
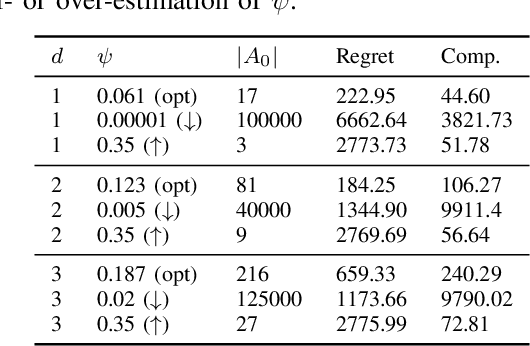
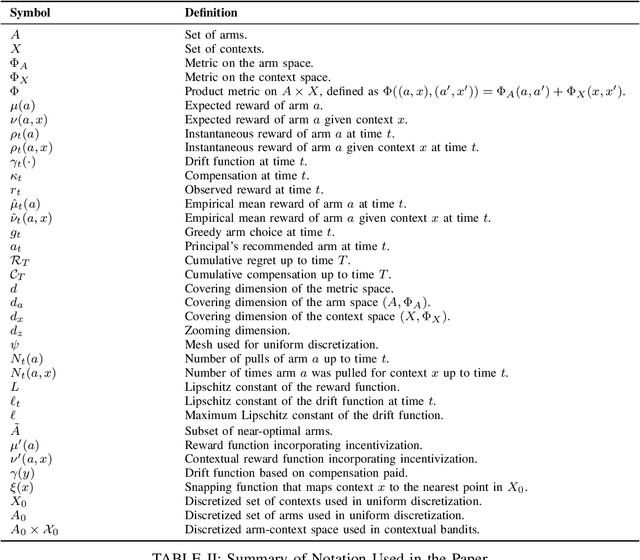
We study incentivized exploration in multi-armed bandit (MAB) settings with infinitely many arms modeled as elements in continuous metric spaces. Unlike classical bandit models, we consider scenarios where the decision-maker (principal) incentivizes myopic agents to explore beyond their greedy choices through compensation, but with the complication of reward drift--biased feedback arising due to the incentives. We propose novel incentivized exploration algorithms that discretize the infinite arm space uniformly and demonstrate that these algorithms simultaneously achieve sublinear cumulative regret and sublinear total compensation. Specifically, we derive regret and compensation bounds of $\Tilde{O}(T^{d+1/d+2})$, with $d$ representing the covering dimension of the metric space. Furthermore, we generalize our results to contextual bandits, achieving comparable performance guarantees. We validate our theoretical findings through numerical simulations.
Generating ensembles of spatially-coherent in-situ forecasts using flow matching
Apr 04, 2025We propose a machine-learning-based methodology for in-situ weather forecast postprocessing that is both spatially coherent and multivariate. Compared to previous work, our Flow MAtching Postprocessing (FMAP) better represents the correlation structures of the observations distribution, while also improving marginal performance at the stations. FMAP generates forecasts that are not bound to what is already modeled by the underlying gridded prediction and can infer new correlation structures from data. The resulting model can generate an arbitrary number of forecasts from a limited number of numerical simulations, allowing for low-cost forecasting systems. A single training is sufficient to perform postprocessing at multiple lead times, in contrast with other methods which use multiple trained networks at generation time. This work details our methodology, including a spatial attention transformer backbone trained within a flow matching generative modeling framework. FMAP shows promising performance in experiments on the EUPPBench dataset, forecasting surface temperature and wind gust values at station locations in western Europe up to five-day lead times.
Deep Clustering via Probabilistic Ratio-Cut Optimization
Feb 05, 2025We propose a novel approach for optimizing the graph ratio-cut by modeling the binary assignments as random variables. We provide an upper bound on the expected ratio-cut, as well as an unbiased estimate of its gradient, to learn the parameters of the assignment variables in an online setting. The clustering resulting from our probabilistic approach (PRCut) outperforms the Rayleigh quotient relaxation of the combinatorial problem, its online learning extensions, and several widely used methods. We demonstrate that the PRCut clustering closely aligns with the similarity measure and can perform as well as a supervised classifier when label-based similarities are provided. This novel approach can leverage out-of-the-box self-supervised representations to achieve competitive performance and serve as an evaluation method for the quality of these representations.
* Proceedings of the 28th International Conference on Artificial Intelligence and Statistics (AISTATS) 2025, Mai Khao, Thailand. PMLR: Volume 258