 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Attribution in Adaptive Learning
Apr 06, 2026Machine learning models increasingly generate their own training data -- online bandits, reinforcement learning, and post-training pipelines for language models are leading examples. In these adaptive settings, a single training observation both updates the learner and shifts the distribution of future data the learner will collect. Standard attribution methods, designed for static datasets, ignore this feedback. We formalize occurrence-level attribution for finite-horizon adaptive learning via a conditional interventional target, prove that replay-side information cannot recover it in general, and identify a structural class in which the target is identified from logged data.
The Role of Generator Access in Autoregressive Post-Training
Apr 06, 2026We study how generator access constrains autoregressive post-training. The central question is whether the learner is confined to fresh root-start rollouts or can return to previously built prefixes and query the next-token rule there. In the root-start regime, output sampling, generated-token log probabilities, top-$k$ reports, and full next-token distributions along sampled trajectories all reduce to one canonical experiment, limited by the on-policy probability of reaching informative prefixes. Weak prefix control breaks this barrier, and once control is available, richer observations such as conditional sampling or logits can outperform top-$1$ access. Changing only the generator interface creates an exponential gap for KL-regularized outcome-reward post-training.
Flickering Multi-Armed Bandits
Feb 19, 2026We introduce Flickering Multi-Armed Bandits (FMAB), a new MAB framework where the set of available arms (or actions) can change at each round, and the available set at any time may depend on the agent's previously selected arm. We model this constrained, evolving availability using random graph processes, where arms are nodes and the agent's movement is restricted to its local neighborhood. We analyze this problem under two random graph models: an i.i.d. Erdős--Rényi (ER) process and an Edge-Markovian process. We propose and analyze a two-phase algorithm that employs a lazy random walk for exploration to efficiently identify the optimal arm, followed by a navigation and commitment phase for exploitation. We establish high-probability and expected sublinear regret bounds for both graph settings. We show that the exploration cost of our algorithm is near-optimal by establishing a matching information-theoretic lower bound for this problem class, highlighting the fundamental cost of exploration under local-move constraints. We complement our theoretical guarantees with numerical simulations, including a scenario of a robotic ground vehicle scouting a disaster-affected region.
A Unified Framework for Locality in Scalable MARL
Feb 19, 2026Scalable Multi-Agent Reinforcement Learning (MARL) is fundamentally challenged by the curse of dimensionality. A common solution is to exploit locality, which hinges on an Exponential Decay Property (EDP) of the value function. However, existing conditions that guarantee the EDP are often conservative, as they are based on worst-case, environment-only bounds (e.g., supremums over actions) and fail to capture the regularizing effect of the policy itself. In this work, we establish that locality can also be a \emph{policy-dependent} phenomenon. Our central contribution is a novel decomposition of the policy-induced interdependence matrix, $H^π$, which decouples the environment's sensitivity to state ($E^{\mathrm{s}}$) and action ($E^{\mathrm{a}}$) from the policy's sensitivity to state ($Π(π)$). This decomposition reveals that locality can be induced by a smooth policy (small $Π(π)$) even when the environment is strongly action-coupled, exposing a fundamental locality-optimality tradeoff. We use this framework to derive a general spectral condition $ρ(E^{\mathrm{s}}+E^{\mathrm{a}}Π(π)) < 1$ for exponential decay, which is strictly tighter than prior norm-based conditions. Finally, we leverage this theory to analyze a provably-sound localized block-coordinate policy improvement framework with guarantees tied directly to this spectral radius.
Multi-Agent Lipschitz Bandits
Feb 18, 2026We study the decentralized multi-player stochastic bandit problem over a continuous, Lipschitz-structured action space where hard collisions yield zero reward. Our objective is to design a communication-free policy that maximizes collective reward, with coordination costs that are independent of the time horizon $T$. We propose a modular protocol that first solves the multi-agent coordination problem -- identifying and seating players on distinct high-value regions via a novel maxima-directed search -- and then decouples the problem into $N$ independent single-player Lipschitz bandits. We establish a near-optimal regret bound of $\tilde{O}(T^{(d+1)/(d+2)})$ plus a $T$-independent coordination cost, matching the single-player rate. To our knowledge, this is the first framework providing such guarantees, and it extends to general distance-threshold collision models.
Incentivized Lipschitz Bandits
Aug 26, 2025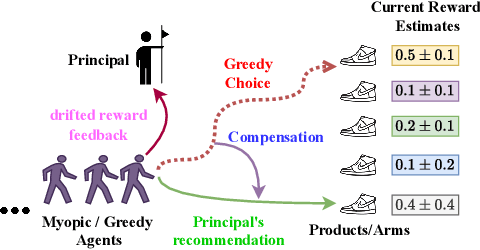
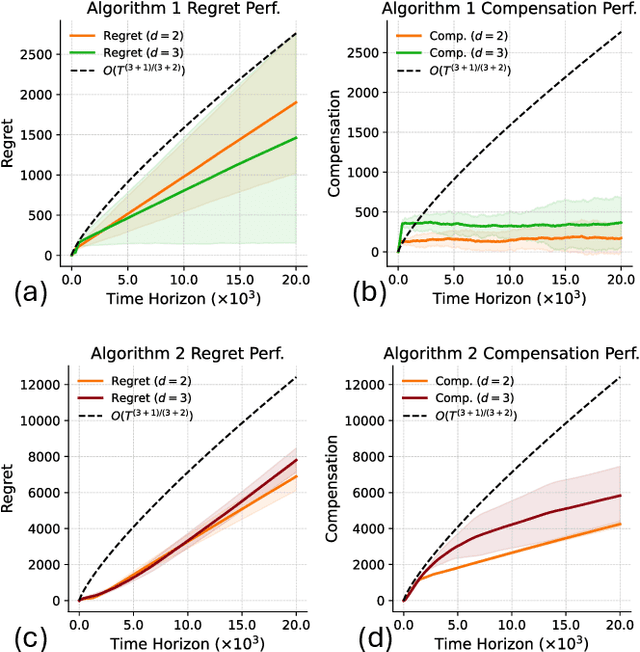
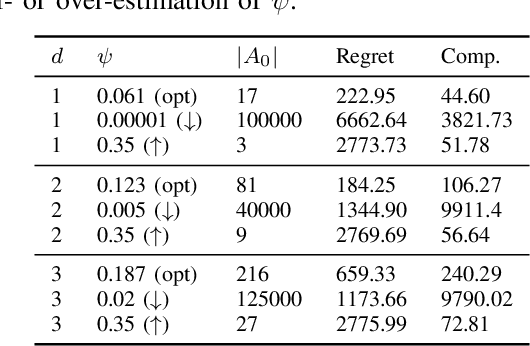
We study incentivized exploration in multi-armed bandit (MAB) settings with infinitely many arms modeled as elements in continuous metric spaces. Unlike classical bandit models, we consider scenarios where the decision-maker (principal) incentivizes myopic agents to explore beyond their greedy choices through compensation, but with the complication of reward drift--biased feedback arising due to the incentives. We propose novel incentivized exploration algorithms that discretize the infinite arm space uniformly and demonstrate that these algorithms simultaneously achieve sublinear cumulative regret and sublinear total compensation. Specifically, we derive regret and compensation bounds of $\Tilde{O}(T^{d+1/d+2})$, with $d$ representing the covering dimension of the metric space. Furthermore, we generalize our results to contextual bandits, achieving comparable performance guarantees. We validate our theoretical findings through numerical simulations.
Where Did Your Model Learn That? Label-free Influence for Self-supervised Learning
Dec 22, 2024Self-supervised learning (SSL) has revolutionized learning from large-scale unlabeled datasets, yet the intrinsic relationship between pretraining data and the learned representations remains poorly understood. Traditional supervised learning benefits from gradient-based data attribution tools like influence functions that measure the contribution of an individual data point to model predictions. However, existing definitions of influence rely on labels, making them unsuitable for SSL settings. We address this gap by introducing Influence-SSL, a novel and label-free approach for defining influence functions tailored to SSL. Our method harnesses the stability of learned representations against data augmentations to identify training examples that help explain model predictions. We provide both theoretical foundations and empirical evidence to show the utility of Influence-SSL in analyzing pre-trained SSL models. Our analysis reveals notable differences in how SSL models respond to influential data compared to supervised models. Finally, we validate the effectiveness of Influence-SSL through applications in duplicate detection, outlier identification and fairness analysis. Code is available at: \url{https://github.com/cryptonymous9/Influence-SSL}.