 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^3$: Structured Sparsity Specification
Apr 13, 2026We introduce the Structured Sparsity Specification (S$^3$), an algebraic framework for defining, composing, and implementing structured sparse patterns. S$^3$ specifies sparsity through three components: a View that reshapes the tensor via layout composition, a Block specification that defines the atomic pruning unit, and the sparsity decision Scope. Both Block and Scope support Coupling across tensors for coordinated sparsification. S$^3$ enables precise specification of diverse sparsity structures, from fine-grained N:M patterns to coarse channel pruning, and integrates seamlessly with Optimal Brain Damage (OBD) and Surgeon (OBS). We formalize the framework mathematically, demonstrate its expressiveness on canonical patterns, and validate it experimentally via structured OBS and OBD implementations built entirely on S$^3$, which surpasses well-established second order heuristics on output reconstruction across common configurations.
Deep Clustering via Probabilistic Ratio-Cut Optimization
Feb 05, 2025We propose a novel approach for optimizing the graph ratio-cut by modeling the binary assignments as random variables. We provide an upper bound on the expected ratio-cut, as well as an unbiased estimate of its gradient, to learn the parameters of the assignment variables in an online setting. The clustering resulting from our probabilistic approach (PRCut) outperforms the Rayleigh quotient relaxation of the combinatorial problem, its online learning extensions, and several widely used methods. We demonstrate that the PRCut clustering closely aligns with the similarity measure and can perform as well as a supervised classifier when label-based similarities are provided. This novel approach can leverage out-of-the-box self-supervised representations to achieve competitive performance and serve as an evaluation method for the quality of these representations.
* Proceedings of the 28th International Conference on Artificial Intelligence and Statistics (AISTATS) 2025, Mai Khao, Thailand. PMLR: Volume 258
Reinforcement Learning with Options and State Representation
Mar 25, 2024



The current thesis aims to explore the reinforcement learning field and build on existing methods to produce improved ones to tackle the problem of learning in high-dimensional and complex environments. It addresses such goals by decomposing learning tasks in a hierarchical fashion known as Hierarchical Reinforcement Learning. We start in the first chapter by getting familiar with the Markov Decision Process framework and presenting some of its recent techniques that the following chapters use. We then proceed to build our Hierarchical Policy learning as an answer to the limitations of a single primitive policy. The hierarchy is composed of a manager agent at the top and employee agents at the lower level. In the last chapter, which is the core of this thesis, we attempt to learn lower-level elements of the hierarchy independently of the manager level in what is known as the "Eigenoption". Based on the graph structure of the environment, Eigenoptions allow us to build agents that are aware of the geometric and dynamic properties of the environment. Their decision-making has a special property: it is invariant to symmetric transformations of the environment, allowing as a consequence to greatly reduce the complexity of the learning task.
Sentiment-Aware Automatic Speech Recognition pre-training for enhanced Speech Emotion Recognition
Jan 27, 2022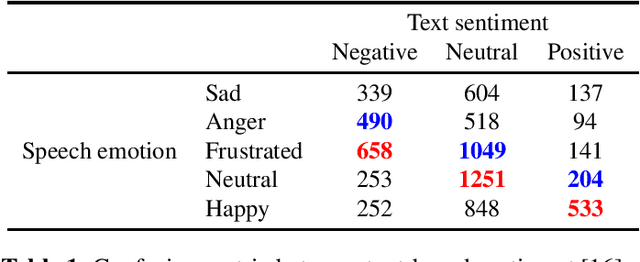
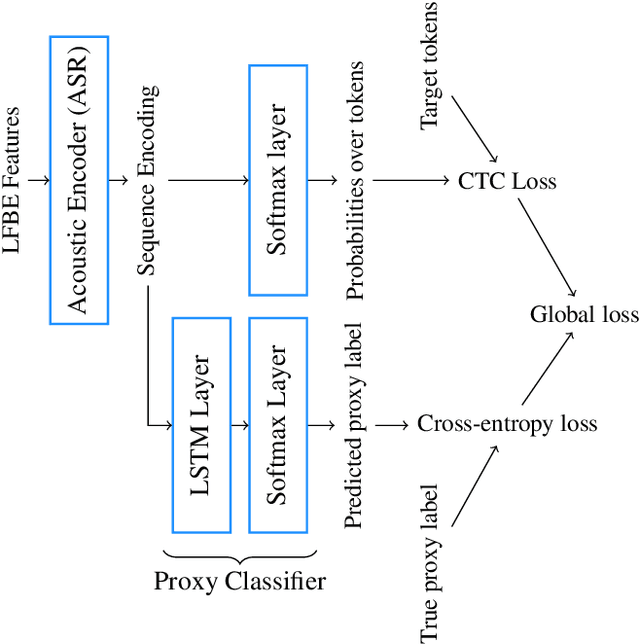
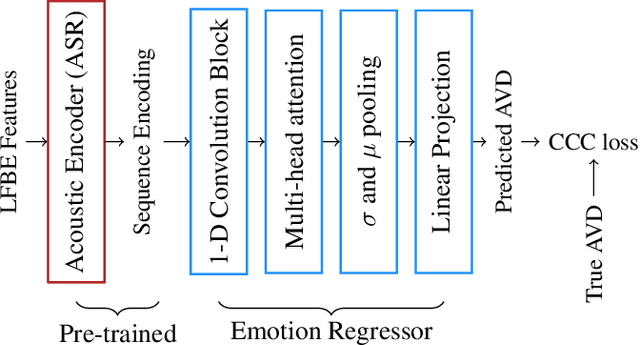
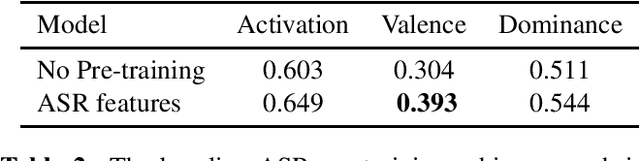
We propose a novel multi-task pre-training method for Speech Emotion Recognition (SER). We pre-train SER model simultaneously on Automatic Speech Recognition (ASR) and sentiment classification tasks to make the acoustic ASR model more ``emotion aware''. We generate targets for the sentiment classification using text-to-sentiment model trained on publicly available data. Finally, we fine-tune the acoustic ASR on emotion annotated speech data. We evaluated the proposed approach on the MSP-Podcast dataset, where we achieved the best reported concordance correlation coefficient (CCC) of 0.41 for valence prediction.