Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment-Aware Automatic Speech Recognition pre-training for enhanced Speech Emotion Recognition
Paper and Code
Jan 27, 2022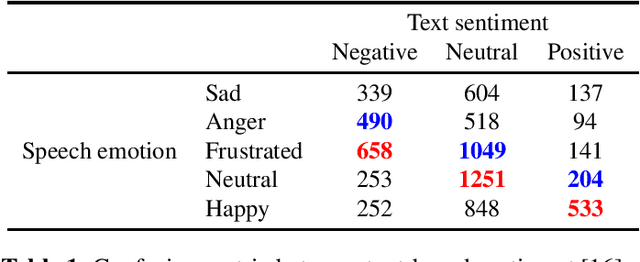
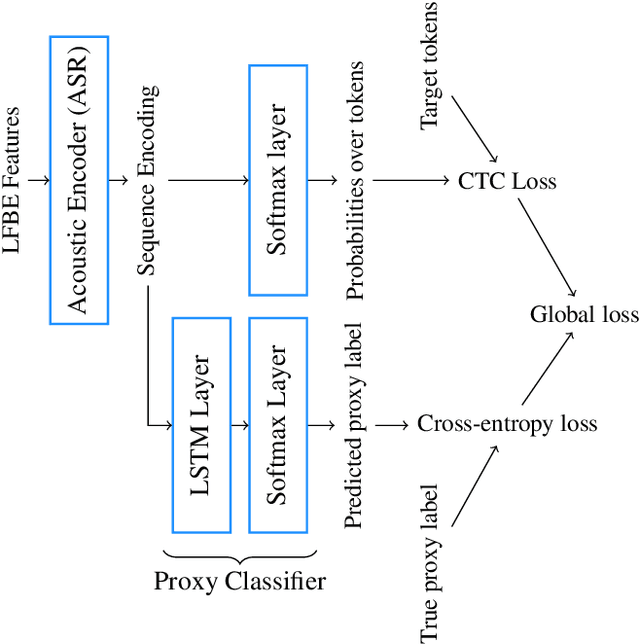
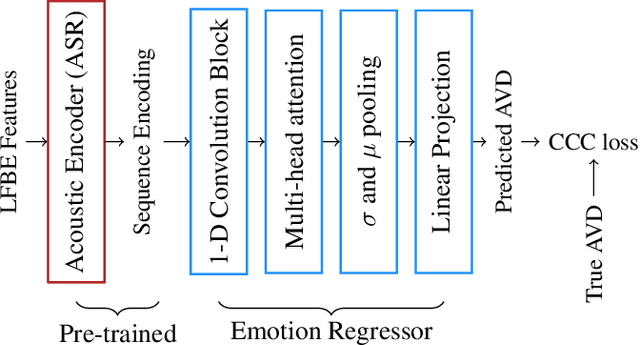
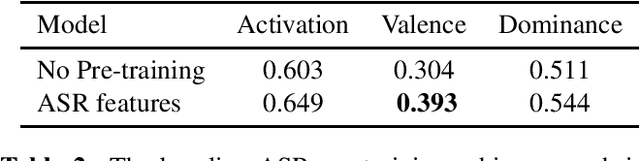
We propose a novel multi-task pre-training method for Speech Emotion Recognition (SER). We pre-train SER model simultaneously on Automatic Speech Recognition (ASR) and sentiment classification tasks to make the acoustic ASR model more ``emotion aware''. We generate targets for the sentiment classification using text-to-sentiment model trained on publicly available data. Finally, we fine-tune the acoustic ASR on emotion annotated speech data. We evaluated the proposed approach on the MSP-Podcast dataset, where we achieved the best reported concordance correlation coefficient (CCC) of 0.41 for valence prediction.
* ICASSP 2022
View paper on