 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025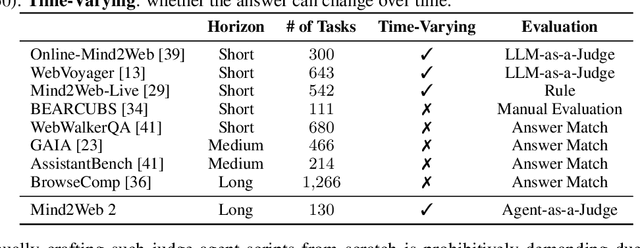
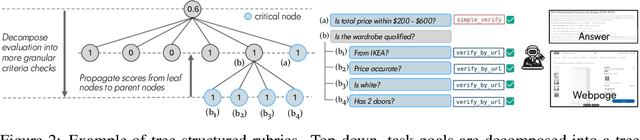

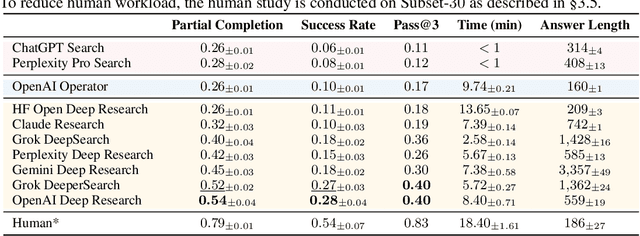
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
Weight-sharing Supernet for Searching Specialized Acoustic Event Classification Networks Across Device Constraints
Mar 18, 2023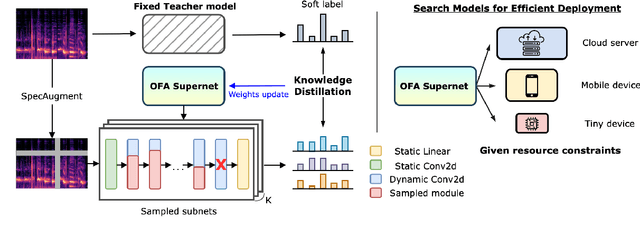



Acoustic Event Classification (AEC) has been widely used in devices such as smart speakers and mobile phones for home safety or accessibility support. As AEC models run on more and more devices with diverse computation resource constraints, it became increasingly expensive to develop models that are tuned to achieve optimal accuracy/computation trade-off for each given computation resource constraint. In this paper, we introduce a Once-For-All (OFA) Neural Architecture Search (NAS) framework for AEC. Specifically, we first train a weight-sharing supernet that supports different model architectures, followed by automatically searching for a model given specific computational resource constraints. Our experimental results showed that by just training once, the resulting model from NAS significantly outperforms both models trained individually from scratch and knowledge distillation (25.4% and 7.3% relative improvement). We also found that the benefit of weight-sharing supernet training of ultra-small models comes not only from searching but from optimization.
Federated Self-Supervised Learning for Acoustic Event Classification
Mar 22, 2022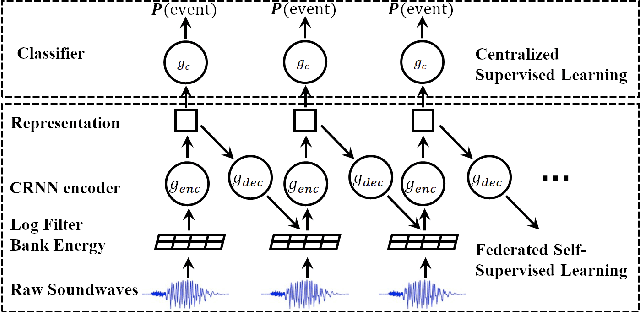

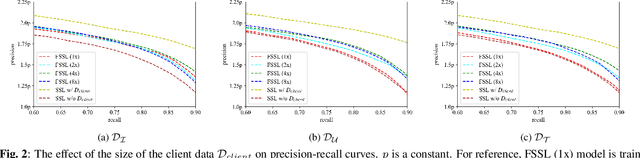
Standard acoustic event classification (AEC) solutions require large-scale collection of data from client devices for model optimization. Federated learning (FL) is a compelling framework that decouples data collection and model training to enhance customer privacy. In this work, we investigate the feasibility of applying FL to improve AEC performance while no customer data can be directly uploaded to the server. We assume no pseudo labels can be inferred from on-device user inputs, aligning with the typical use cases of AEC. We adapt self-supervised learning to the FL framework for on-device continual learning of representations, and it results in improved performance of the downstream AEC classifiers without labeled/pseudo-labeled data available. Compared to the baseline w/o FL, the proposed method improves precision up to 20.3\% relatively while maintaining the recall. Our work differs from prior work in FL in that our approach does not require user-generated learning targets, and the data we use is collected from our Beta program and is de-identified, to maximally simulate the production settings.
Sentiment-Aware Automatic Speech Recognition pre-training for enhanced Speech Emotion Recognition
Jan 27, 2022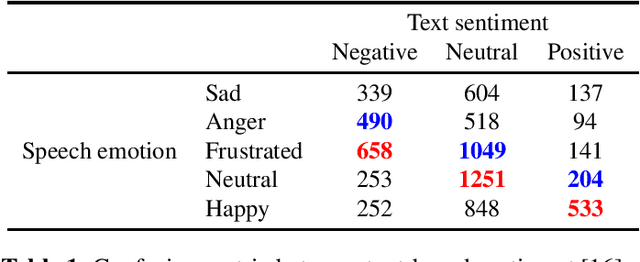
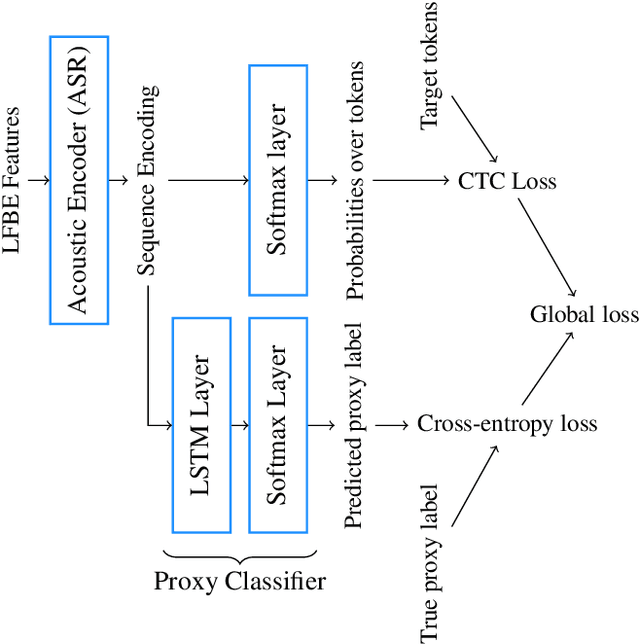
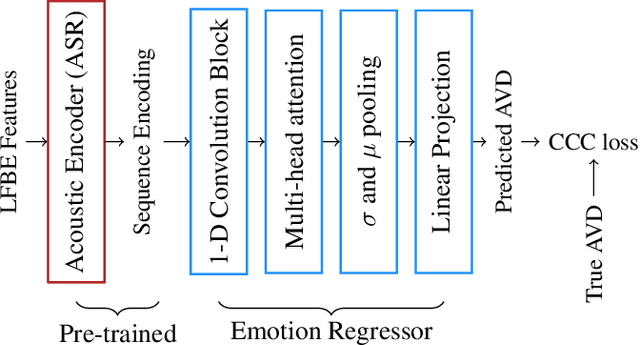
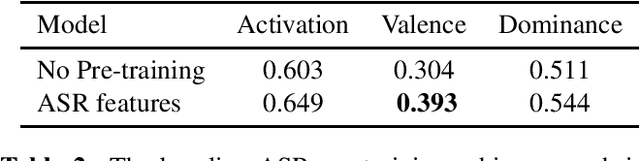
We propose a novel multi-task pre-training method for Speech Emotion Recognition (SER). We pre-train SER model simultaneously on Automatic Speech Recognition (ASR) and sentiment classification tasks to make the acoustic ASR model more ``emotion aware''. We generate targets for the sentiment classification using text-to-sentiment model trained on publicly available data. Finally, we fine-tune the acoustic ASR on emotion annotated speech data. We evaluated the proposed approach on the MSP-Podcast dataset, where we achieved the best reported concordance correlation coefficient (CCC) of 0.41 for valence prediction.
Contrastive Unsupervised Learning for Speech Emotion Recognition
Feb 12, 2021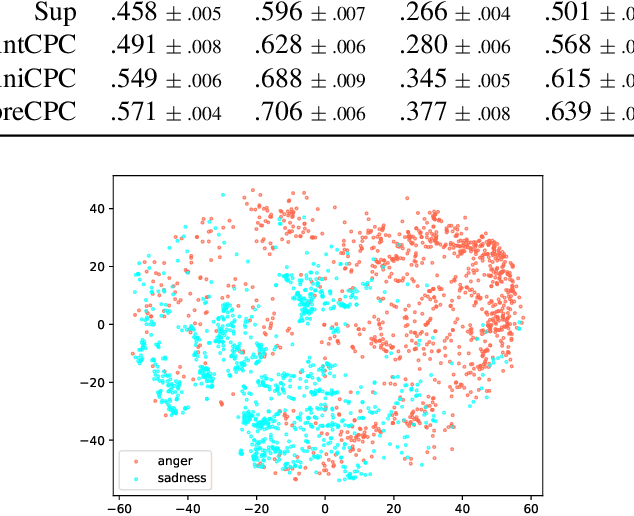

Speech emotion recognition (SER) is a key technology to enable more natural human-machine communication. However, SER has long suffered from a lack of public large-scale labeled datasets. To circumvent this problem, we investigate how unsupervised representation learning on unlabeled datasets can benefit SER. We show that the contrastive predictive coding (CPC) method can learn salient representations from unlabeled datasets, which improves emotion recognition performance. In our experiments, this method achieved state-of-the-art concordance correlation coefficient (CCC) performance for all emotion primitives (activation, valence, and dominance) on IEMOCAP. Additionally, on the MSP- Podcast dataset, our method obtained considerable performance improvements compared to baselines.
Compression of Acoustic Event Detection Models With Quantized Distillation
Jul 01, 2019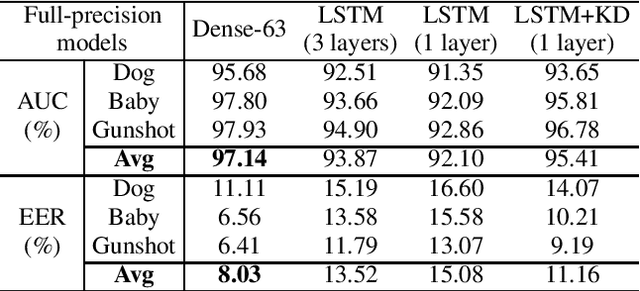


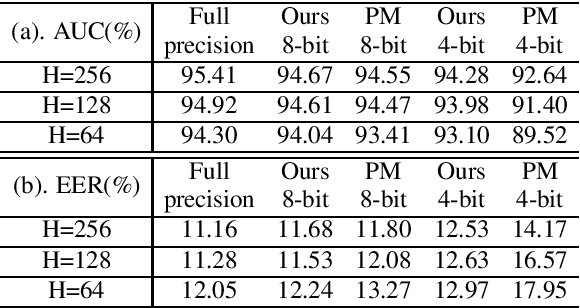
Acoustic Event Detection (AED), aiming at detecting categories of events based on audio signals, has found application in many intelligent systems. Recently deep neural network significantly advances this field and reduces detection errors to a large scale. However how to efficiently execute deep models in AED has received much less attention. Meanwhile state-of-the-art AED models are based on large deep models, which are computational demanding and challenging to deploy on devices with constrained computational resources. In this paper, we present a simple yet effective compression approach which jointly leverages knowledge distillation and quantization to compress larger network (teacher model) into compact network (student model). Experimental results show proposed technique not only lowers error rate of original compact network by 15% through distillation but also further reduces its model size to a large extent (2% of teacher, 12% of full-precision student) through quantization.
Compression of Acoustic Event Detection Models with Low-rank Matrix Factorization and Quantization Training
May 02, 2019
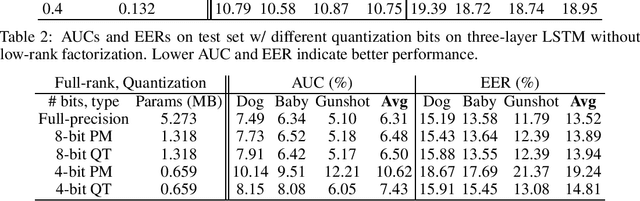

In this paper, we present a compression approach based on the combination of low-rank matrix factorization and quantization training, to reduce complexity for neural network based acoustic event detection (AED) models. Our experimental results show this combined compression approach is very effective. For a three-layer long short-term memory (LSTM) based AED model, the original model size can be reduced to 1% with negligible loss of accuracy. Our approach enables the feasibility of deploying AED for resource-constraint applications.
Semi-supervised Acoustic Event Detection based on tri-training
Apr 29, 2019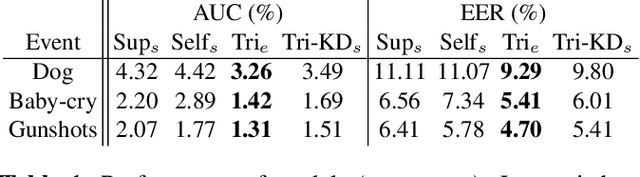


This paper presents our work of training acoustic event detection (AED) models using unlabeled dataset. Recent acoustic event detectors are based on large-scale neural networks, which are typically trained with huge amounts of labeled data. Labels for acoustic events are expensive to obtain, and relevant acoustic event audios can be limited, especially for rare events. In this paper we leverage an Internet-scale unlabeled dataset with potential domain shift to improve the detection of acoustic events. Based on the classic tri-training approach, our proposed method shows accuracy improvement over both the supervised training baseline, and semisupervised self-training set-up, in all pre-defined acoustic event detection tasks. As our approach relies on ensemble models, we further show the improvements can be distilled to a single model via knowledge distillation, with the resulting single student model maintaining high accuracy of teacher ensemble models.
Learning Spatiotemporal Features for Infrared Action Recognition with 3D Convolutional Neural Networks
May 18, 2017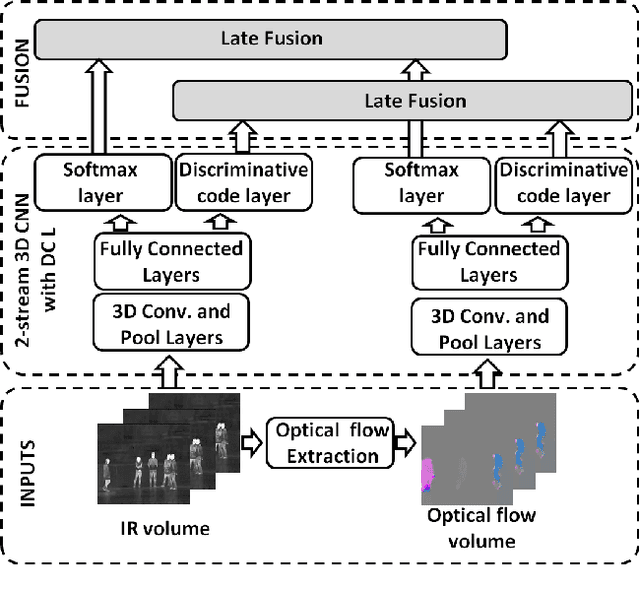
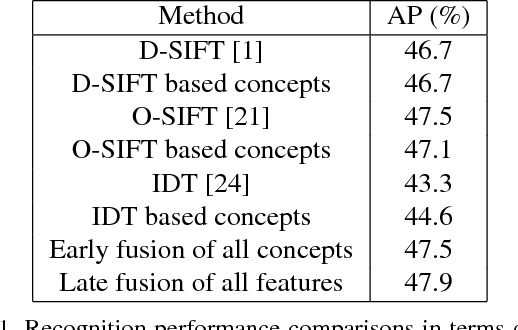
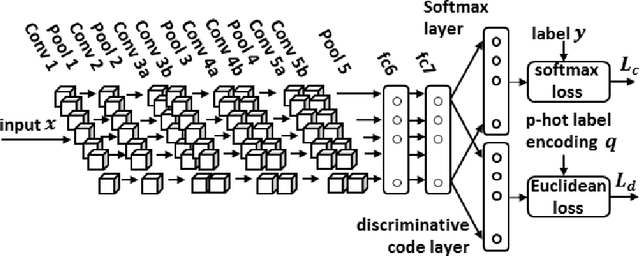
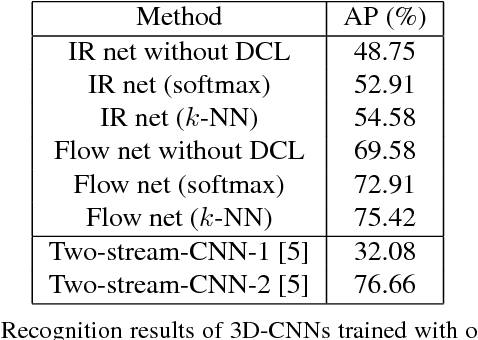
Infrared (IR) imaging has the potential to enable more robust action recognition systems compared to visible spectrum cameras due to lower sensitivity to lighting conditions and appearance variability. While the action recognition task on videos collected from visible spectrum imaging has received much attention, action recognition in IR videos is significantly less explored. Our objective is to exploit imaging data in this modality for the action recognition task. In this work, we propose a novel two-stream 3D convolutional neural network (CNN) architecture by introducing the discriminative code layer and the corresponding discriminative code loss function. The proposed network processes IR image and the IR-based optical flow field sequences. We pretrain the 3D CNN model on the visible spectrum Sports-1M action dataset and finetune it on the Infrared Action Recognition (InfAR) dataset. To our best knowledge, this is the first application of the 3D CNN to action recognition in the IR domain. We conduct an elaborate analysis of different fusion schemes (weighted average, single and double-layer neural nets) applied to different 3D CNN outputs. Experimental results demonstrate that our approach can achieve state-of-the-art average precision (AP) performances on the InfAR dataset: (1) the proposed two-stream 3D CNN achieves the best reported 77.5% AP, and (2) our 3D CNN model applied to the optical flow fields achieves the best reported single stream 75.42% AP.
Learning Discriminative Features via Label Consistent Neural Network
Jun 05, 2016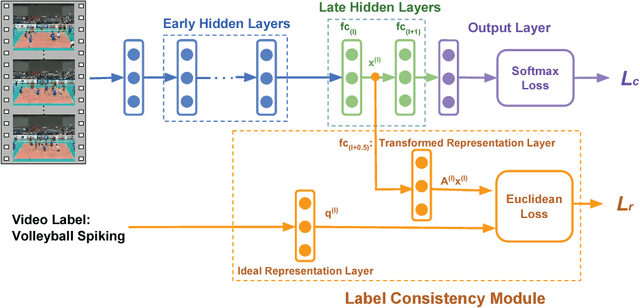
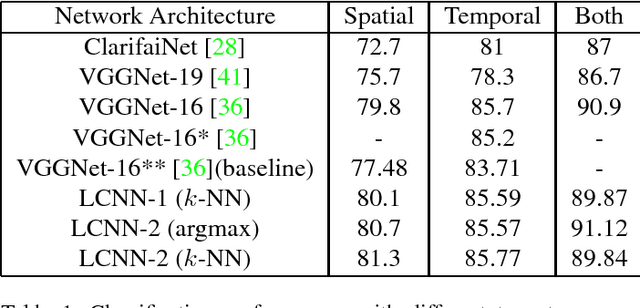

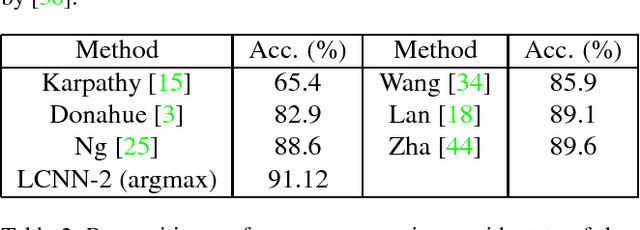
Deep Convolutional Neural Networks (CNN) enforces supervised information only at the output layer, and hidden layers are trained by back propagating the prediction error from the output layer without explicit supervision. We propose a supervised feature learning approach, Label Consistent Neural Network, which enforces direct supervision in late hidden layers. We associate each neuron in a hidden layer with a particular class label and encourage it to be activated for input signals from the same class. More specifically, we introduce a label consistency regularization called "discriminative representation error" loss for late hidden layers and combine it with classification error loss to build our overall objective function. This label consistency constraint alleviates the common problem of gradient vanishing and tends to faster convergence; it also makes the features derived from late hidden layers discriminative enough for classification even using a simple $k$-NN classifier, since input signals from the same class will have very similar representations. Experimental results demonstrate that our approach achieves state-of-the-art performances on several public benchmarks for action and object category recognition.