 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight-sharing Supernet for Searching Specialized Acoustic Event Classification Networks Across Device Constraints
Mar 18, 2023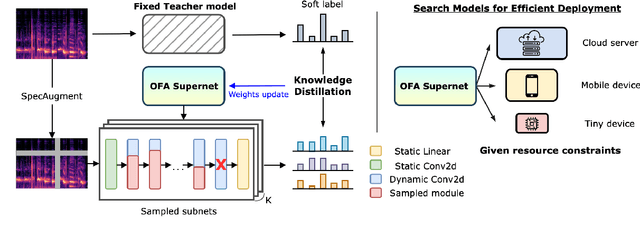



Acoustic Event Classification (AEC) has been widely used in devices such as smart speakers and mobile phones for home safety or accessibility support. As AEC models run on more and more devices with diverse computation resource constraints, it became increasingly expensive to develop models that are tuned to achieve optimal accuracy/computation trade-off for each given computation resource constraint. In this paper, we introduce a Once-For-All (OFA) Neural Architecture Search (NAS) framework for AEC. Specifically, we first train a weight-sharing supernet that supports different model architectures, followed by automatically searching for a model given specific computational resource constraints. Our experimental results showed that by just training once, the resulting model from NAS significantly outperforms both models trained individually from scratch and knowledge distillation (25.4% and 7.3% relative improvement). We also found that the benefit of weight-sharing supernet training of ultra-small models comes not only from searching but from optimization.
Federated Self-Supervised Learning for Acoustic Event Classification
Mar 22, 2022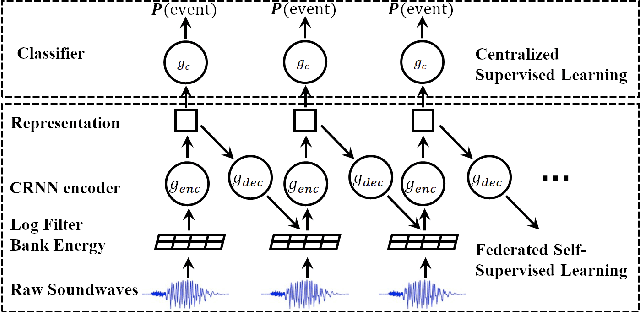

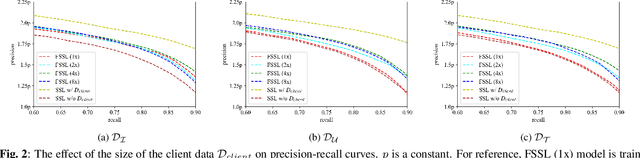
Standard acoustic event classification (AEC) solutions require large-scale collection of data from client devices for model optimization. Federated learning (FL) is a compelling framework that decouples data collection and model training to enhance customer privacy. In this work, we investigate the feasibility of applying FL to improve AEC performance while no customer data can be directly uploaded to the server. We assume no pseudo labels can be inferred from on-device user inputs, aligning with the typical use cases of AEC. We adapt self-supervised learning to the FL framework for on-device continual learning of representations, and it results in improved performance of the downstream AEC classifiers without labeled/pseudo-labeled data available. Compared to the baseline w/o FL, the proposed method improves precision up to 20.3\% relatively while maintaining the recall. Our work differs from prior work in FL in that our approach does not require user-generated learning targets, and the data we use is collected from our Beta program and is de-identified, to maximally simulate the production settings.
Multi-Task Self-Supervised Pre-Training for Music Classification
Feb 05, 2021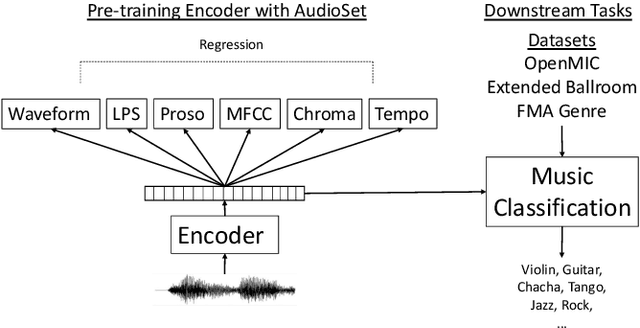
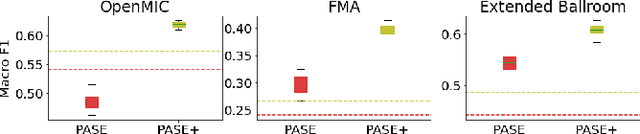
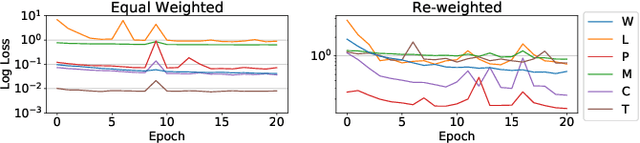
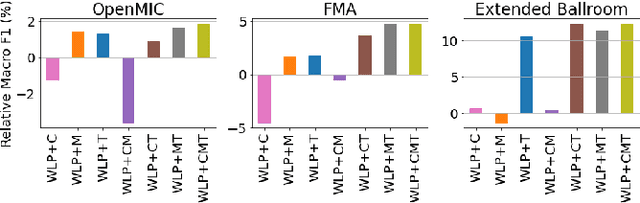
Deep learning is very data hungry, and supervised learning especially requires massive labeled data to work well. Machine listening research often suffers from limited labeled data problem, as human annotations are costly to acquire, and annotations for audio are time consuming and less intuitive. Besides, models learned from labeled dataset often embed biases specific to that particular dataset. Therefore, unsupervised learning techniques become popular approaches in solving machine listening problems. Particularly, a self-supervised learning technique utilizing reconstructions of multiple hand-crafted audio features has shown promising results when it is applied to speech domain such as emotion recognition and automatic speech recognition (ASR). In this paper, we apply self-supervised and multi-task learning methods for pre-training music encoders, and explore various design choices including encoder architectures, weighting mechanisms to combine losses from multiple tasks, and worker selections of pretext tasks. We investigate how these design choices interact with various downstream music classification tasks. We find that using various music specific workers altogether with weighting mechanisms to balance the losses during pre-training helps improve and generalize to the downstream tasks.
On Front-end Gain Invariant Modeling for Wake Word Spotting
Oct 13, 2020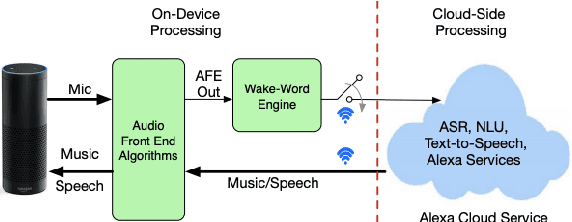
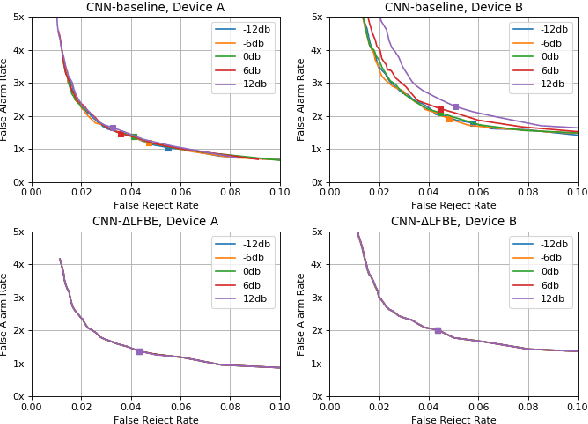
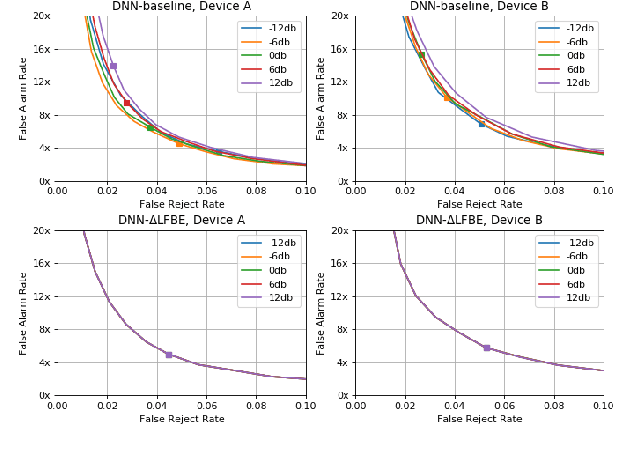
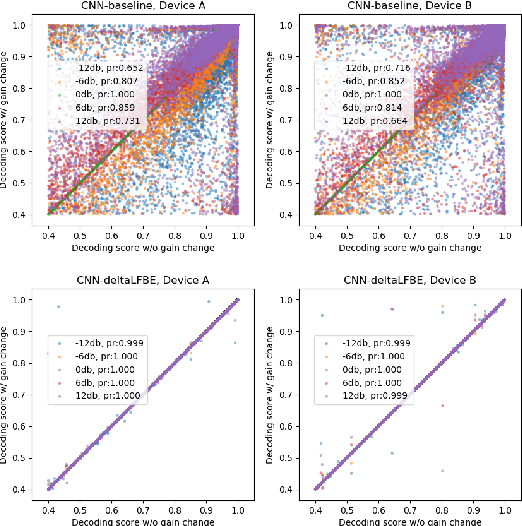
Wake word (WW) spotting is challenging in far-field due to the complexities and variations in acoustic conditions and the environmental interference in signal transmission. A suite of carefully designed and optimized audio front-end (AFE) algorithms help mitigate these challenges and provide better quality audio signals to the downstream modules such as WW spotter. Since the WW model is trained with the AFE-processed audio data, its performance is sensitive to AFE variations, such as gain changes. In addition, when deploying to new devices, the WW performance is not guaranteed because the AFE is unknown to the WW model. To address these issues, we propose a novel approach to use a new feature called $\Delta$LFBE to decouple the AFE gain variations from the WW model. We modified the neural network architectures to accommodate the delta computation, with the feature extraction module unchanged. We evaluate our WW models using data collected from real household settings and showed the models with the $\Delta$LFBE is robust to AFE gain changes. Specifically, when AFE gain changes up to $\pm$12dB, the baseline CNN model lost up to relative 19.0% in false alarm rate or 34.3% in false reject rate, while the model with $\Delta$LFBE demonstrates no performance loss.
Few-shot acoustic event detection via meta-learning
Feb 21, 2020



We study few-shot acoustic event detection (AED) in this paper. Few-shot learning enables detection of new events with very limited labeled data. Compared to other research areas like computer vision, few-shot learning for audio recognition has been under-studied. We formulate few-shot AED problem and explore different ways of utilizing traditional supervised methods for this setting as well as a variety of meta-learning approaches, which are conventionally used to solve few-shot classification problem. Compared to supervised baselines, meta-learning models achieve superior performance, thus showing its effectiveness on generalization to new audio events. Our analysis including impact of initialization and domain discrepancy further validate the advantage of meta-learning approaches in few-shot AED.
Compression of Acoustic Event Detection Models With Quantized Distillation
Jul 01, 2019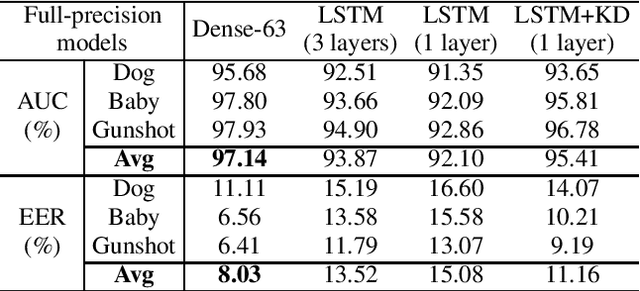


Acoustic Event Detection (AED), aiming at detecting categories of events based on audio signals, has found application in many intelligent systems. Recently deep neural network significantly advances this field and reduces detection errors to a large scale. However how to efficiently execute deep models in AED has received much less attention. Meanwhile state-of-the-art AED models are based on large deep models, which are computational demanding and challenging to deploy on devices with constrained computational resources. In this paper, we present a simple yet effective compression approach which jointly leverages knowledge distillation and quantization to compress larger network (teacher model) into compact network (student model). Experimental results show proposed technique not only lowers error rate of original compact network by 15% through distillation but also further reduces its model size to a large extent (2% of teacher, 12% of full-precision student) through quantization.
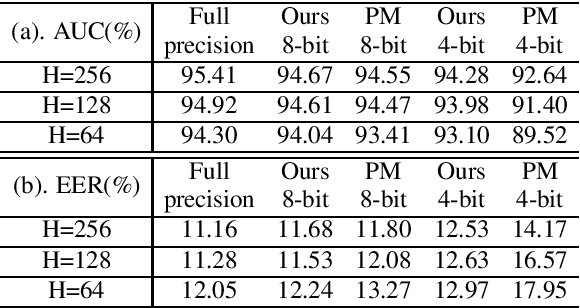
Compression of Acoustic Event Detection Models with Low-rank Matrix Factorization and Quantization Training
May 02, 2019
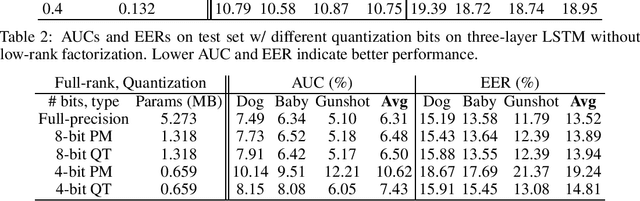

In this paper, we present a compression approach based on the combination of low-rank matrix factorization and quantization training, to reduce complexity for neural network based acoustic event detection (AED) models. Our experimental results show this combined compression approach is very effective. For a three-layer long short-term memory (LSTM) based AED model, the original model size can be reduced to 1% with negligible loss of accuracy. Our approach enables the feasibility of deploying AED for resource-constraint applications.
Semi-supervised Acoustic Event Detection based on tri-training
Apr 29, 2019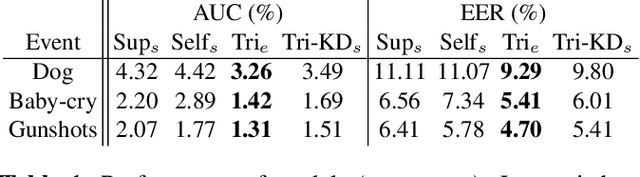


This paper presents our work of training acoustic event detection (AED) models using unlabeled dataset. Recent acoustic event detectors are based on large-scale neural networks, which are typically trained with huge amounts of labeled data. Labels for acoustic events are expensive to obtain, and relevant acoustic event audios can be limited, especially for rare events. In this paper we leverage an Internet-scale unlabeled dataset with potential domain shift to improve the detection of acoustic events. Based on the classic tri-training approach, our proposed method shows accuracy improvement over both the supervised training baseline, and semisupervised self-training set-up, in all pre-defined acoustic event detection tasks. As our approach relies on ensemble models, we further show the improvements can be distilled to a single model via knowledge distillation, with the resulting single student model maintaining high accuracy of teacher ensemble models.
Patch-Based Image Hallucination for Super Resolution with Detail Reconstruction from Similar Sample Images
Jun 03, 2018

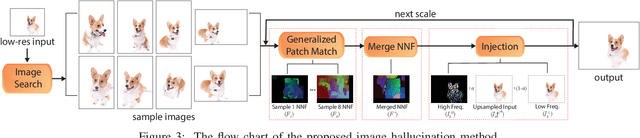

Image hallucination and super-resolution have been studied for decades, and many approaches have been proposed to upsample low-resolution images using information from the images themselves, multiple example images, or large image databases. However, most of this work has focused exclusively on small magnification levels because the algorithms simply sharpen the blurry edges in the upsampled images - no actual new detail is typically reconstructed in the final result. In this paper, we present a patch-based algorithm for image hallucination which, for the first time, properly synthesizes novel high frequency detail. To do this, we pose the synthesis problem as a patch-based optimization which inserts coherent, high-frequency detail from contextually-similar images of the same physical scene/subject provided from either a personal image collection or a large online database. The resulting image is visually plausible and contains coherent high frequency information. We demonstrate the robustness of our algorithm by testing it on a large number of images and show that its performance is considerably superior to all state-of-the-art approaches, a result that is verified to be statistically significant through a randomized user study.
Localization-Aware Active Learning for Object Detection
Jan 16, 2018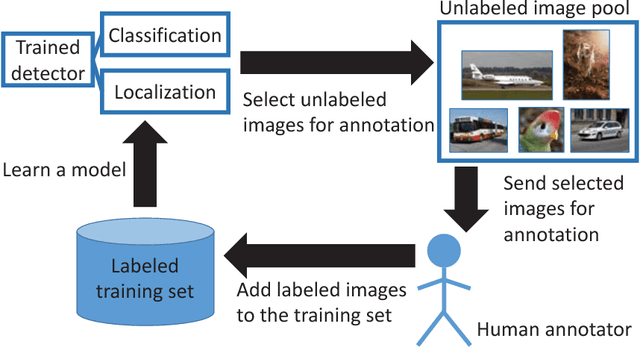


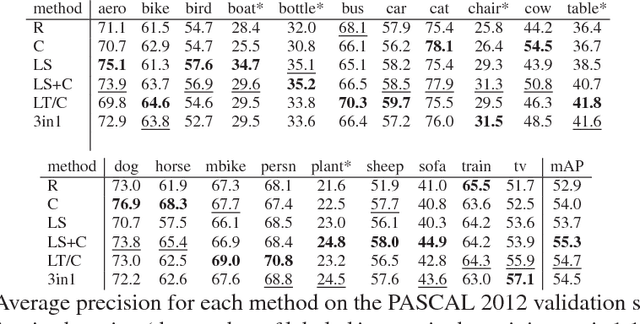
Active learning - a class of algorithms that iteratively searches for the most informative samples to include in a training dataset - has been shown to be effective at annotating data for image classification. However, the use of active learning for object detection is still largely unexplored as determining informativeness of an object-location hypothesis is more difficult. In this paper, we address this issue and present two metrics for measuring the informativeness of an object hypothesis, which allow us to leverage active learning to reduce the amount of annotated data needed to achieve a target object detection performance. Our first metric measures 'localization tightness' of an object hypothesis, which is based on the overlapping ratio between the region proposal and the final prediction. Our second metric measures 'localization stability' of an object hypothesis, which is based on the variation of predicted object locations when input images are corrupted by noise. Our experimental results show that by augmenting a conventional active-learning algorithm designed for classification with the proposed metrics, the amount of labeled training data required can be reduced up to 25%. Moreover, on PASCAL 2007 and 2012 datasets our localization-stability method has an average relative improvement of 96.5% and 81.9% over the baseline method using classification only.