 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Sensitivity of Pre-trained Audio Embeddings to Common Effects
Jan 27, 2025



In recent years, foundation models have significantly advanced data-driven systems across various domains. Yet, their underlying properties, especially when functioning as feature extractors, remain under-explored. In this paper, we investigate the sensitivity to audio effects of audio embeddings extracted from widely-used foundation models, including OpenL3, PANNs, and CLAP. We focus on audio effects as the source of sensitivity due to their prevalent presence in large audio datasets. By applying parameterized audio effects (gain, low-pass filtering, reverberation, and bitcrushing), we analyze the correlation between the deformation trajectories and the effect strength in the embedding space. We propose to quantify the dimensionality and linearizability of the deformation trajectories induced by audio effects using canonical correlation analysis. We find that there exists a direction along which the embeddings move monotonically as the audio effect strength increases, but that the subspace containing the displacements is generally high-dimensional. This shows that pre-trained audio embeddings do not globally linearize the effects. Our empirical results on instrument classification downstream tasks confirm that projecting out the estimated deformation directions cannot generally improve the robustness of pre-trained embeddings to audio effects.
Sound Scene Synthesis at the DCASE 2024 Challenge
Jan 15, 2025This paper presents Task 7 at the DCASE 2024 Challenge: sound scene synthesis. Recent advances in sound synthesis and generative models have enabled the creation of realistic and diverse audio content. We introduce a standardized evaluation framework for comparing different sound scene synthesis systems, incorporating both objective and subjective metrics. The challenge attracted four submissions, which are evaluated using the Fr\'echet Audio Distance (FAD) and human perceptual ratings. Our analysis reveals significant insights into the current capabilities and limitations of sound scene synthesis systems, while also highlighting areas for future improvement in this rapidly evolving field.
Challenge on Sound Scene Synthesis: Evaluating Text-to-Audio Generation
Oct 23, 2024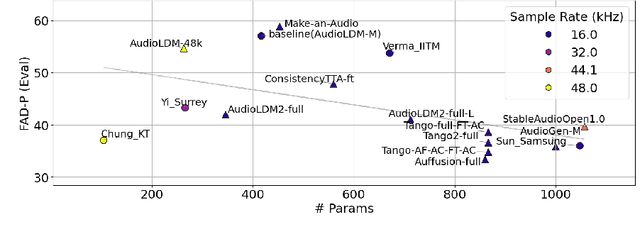
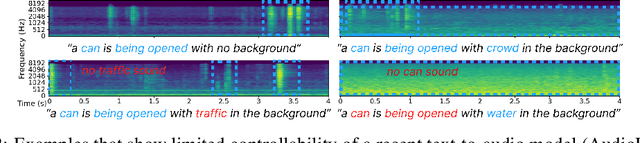
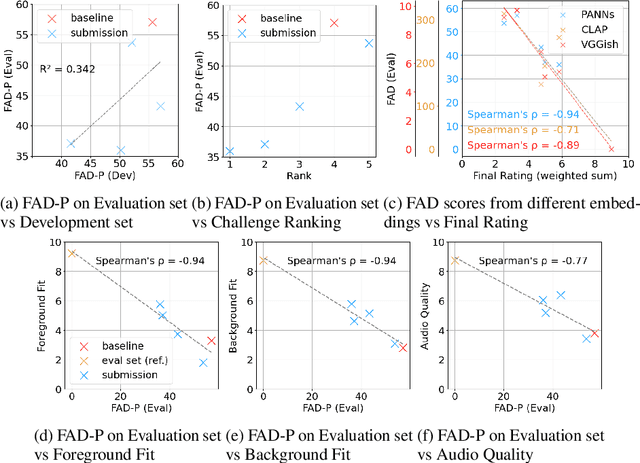
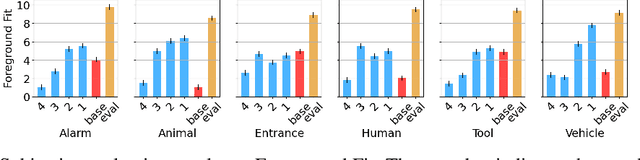
Despite significant advancements in neural text-to-audio generation, challenges persist in controllability and evaluation. This paper addresses these issues through the Sound Scene Synthesis challenge held as part of the Detection and Classification of Acoustic Scenes and Events 2024. We present an evaluation protocol combining objective metric, namely Fr\'echet Audio Distance, with perceptual assessments, utilizing a structured prompt format to enable diverse captions and effective evaluation. Our analysis reveals varying performance across sound categories and model architectures, with larger models generally excelling but innovative lightweight approaches also showing promise. The strong correlation between objective metrics and human ratings validates our evaluation approach. We discuss outcomes in terms of audio quality, controllability, and architectural considerations for text-to-audio synthesizers, providing direction for future research.
Spatial Scaper: A Library to Simulate and Augment Soundscapes for Sound Event Localization and Detection in Realistic Rooms
Jan 19, 2024Sound event localization and detection (SELD) is an important task in machine listening. Major advancements rely on simulated data with sound events in specific rooms and strong spatio-temporal labels. SELD data is simulated by convolving spatialy-localized room impulse responses (RIRs) with sound waveforms to place sound events in a soundscape. However, RIRs require manual collection in specific rooms. We present SpatialScaper, a library for SELD data simulation and augmentation. Compared to existing tools, SpatialScaper emulates virtual rooms via parameters such as size and wall absorption. This allows for parameterized placement (including movement) of foreground and background sound sources. SpatialScaper also includes data augmentation pipelines that can be applied to existing SELD data. As a case study, we use SpatialScaper to add rooms to the DCASE SELD data. Training a model with our data led to progressive performance improves as a direct function of acoustic diversity. These results show that SpatialScaper is valuable to train robust SELD models.
Leveraging Geometrical Acoustic Simulations of Spatial Room Impulse Responses for Improved Sound Event Detection and Localization
Sep 06, 2023As deeper and more complex models are developed for the task of sound event localization and detection (SELD), the demand for annotated spatial audio data continues to increase. Annotating field recordings with 360$^{\circ}$ video takes many hours from trained annotators, while recording events within motion-tracked laboratories are bounded by cost and expertise. Because of this, localization models rely on a relatively limited amount of spatial audio data in the form of spatial room impulse response (SRIR) datasets, which limits the progress of increasingly deep neural network based approaches. In this work, we demonstrate that simulated geometrical acoustics can provide an appealing solution to this problem. We use simulated geometrical acoustics to generate a novel SRIR dataset that can train a SELD model to provide similar performance to that of a real SRIR dataset. Furthermore, we demonstrate using simulated data to augment existing datasets, improving on benchmarks set by state of the art SELD models. We explore the potential and limitations of geometric acoustic simulation for localization and event detection. We also propose further studies to verify the limitations of this method, as well as further methods to generate synthetic data for SELD tasks without the need to record more data.
Transfer Learning and Bias Correction with Pre-trained Audio Embeddings
Jul 20, 2023



Deep neural network models have become the dominant approach to a large variety of tasks within music information retrieval (MIR). These models generally require large amounts of (annotated) training data to achieve high accuracy. Because not all applications in MIR have sufficient quantities of training data, it is becoming increasingly common to transfer models across domains. This approach allows representations derived for one task to be applied to another, and can result in high accuracy with less stringent training data requirements for the downstream task. However, the properties of pre-trained audio embeddings are not fully understood. Specifically, and unlike traditionally engineered features, the representations extracted from pre-trained deep networks may embed and propagate biases from the model's training regime. This work investigates the phenomenon of bias propagation in the context of pre-trained audio representations for the task of instrument recognition. We first demonstrate that three different pre-trained representations (VGGish, OpenL3, and YAMNet) exhibit comparable performance when constrained to a single dataset, but differ in their ability to generalize across datasets (OpenMIC and IRMAS). We then investigate dataset identity and genre distribution as potential sources of bias. Finally, we propose and evaluate post-processing countermeasures to mitigate the effects of bias, and improve generalization across datasets.
Foley Sound Synthesis at the DCASE 2023 Challenge
Apr 26, 2023


The addition of Foley sound effects during post-production is a common technique used to enhance the perceived acoustic properties of multimedia content. Traditionally, Foley sound has been produced by human Foley artists, which involves manual recording and mixing of sound. However, recent advances in sound synthesis and generative models have generated interest in machine-assisted or automatic Foley synthesis techniques. To promote further research in this area, we have organized a challenge in DCASE 2023: Task 7 - Foley Sound Synthesis. Our challenge aims to provide a standardized evaluation framework that is both rigorous and efficient, allowing for the evaluation of different Foley synthesis systems. Through this challenge, we hope to encourage active participation from the research community and advance the state-of-the-art in automatic Foley synthesis. In this technical report, we provide a detailed overview of the Foley sound synthesis challenge, including task definition, dataset, baseline, evaluation scheme and criteria, and discussion.
A Proposal for Foley Sound Synthesis Challenge
Jul 21, 2022"Foley" refers to sound effects that are added to multimedia during post-production to enhance its perceived acoustic properties, e.g., by simulating the sounds of footsteps, ambient environmental sounds, or visible objects on the screen. While foley is traditionally produced by foley artists, there is increasing interest in automatic or machine-assisted techniques building upon recent advances in sound synthesis and generative models. To foster more participation in this growing research area, we propose a challenge for automatic foley synthesis. Through case studies on successful previous challenges in audio and machine learning, we set the goals of the proposed challenge: rigorous, unified, and efficient evaluation of different foley synthesis systems, with an overarching goal of drawing active participation from the research community. We outline the details and design considerations of a foley sound synthesis challenge, including task definition, dataset requirements, and evaluation criteria.
Diarization of Legal Proceedings. Identifying and Transcribing Judicial Speech from Recorded Court Audio
Apr 03, 2021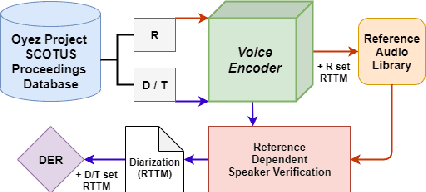

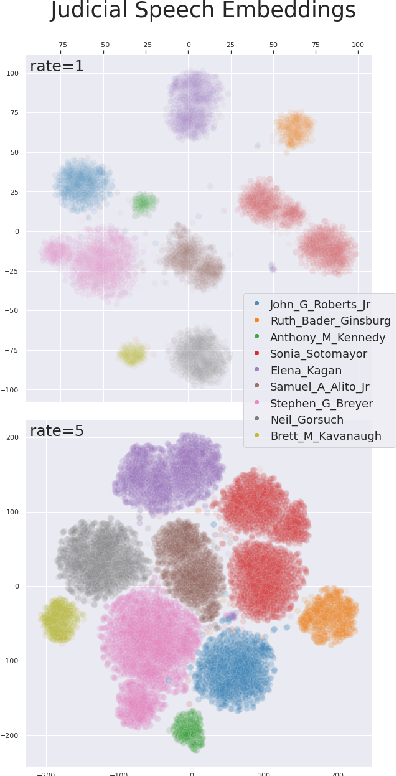
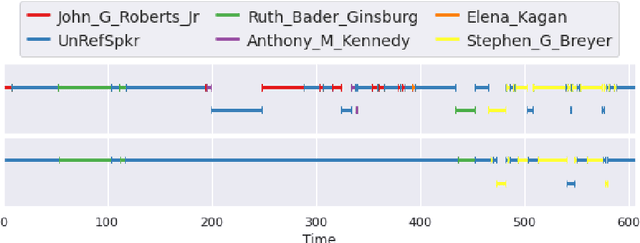
United States Courts make audio recordings of oral arguments available as public record, but these recordings rarely include speaker annotations. This paper addresses the Speech Audio Diarization problem, answering the question of "Who spoke when?" in the domain of judicial oral argument proceedings. We present a workflow for diarizing the speech of judges using audio recordings of oral arguments, a process we call Reference-Dependent Speaker Verification. We utilize a speech embedding network trained with the Generalized End-to-End Loss to encode speech into d-vectors and a pre-defined reference audio library based on annotated data. We find that by encoding reference audio for speakers and full arguments and computing similarity scores we achieve a 13.8% Diarization Error Rate for speakers covered by the reference audio library on a held-out test set. We evaluate our method on the Supreme Court of the United States oral arguments, accessed through the Oyez Project, and outline future work for diarizing legal proceedings. A code repository for this research is available at github.com/JeffT13/rd-diarization
Sound Event Detection in Urban Audio With Single and Multi-Rate PCEN
Feb 06, 2021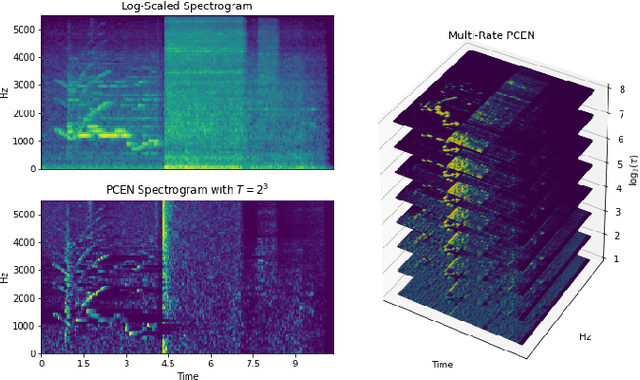
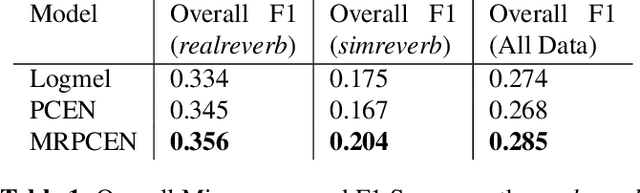
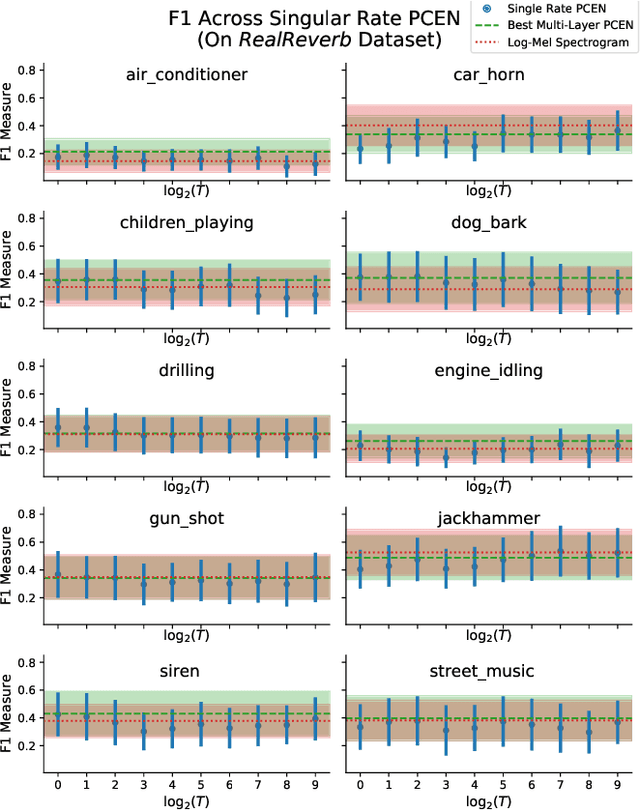
Recent literature has demonstrated that the use of per-channel energy normalization (PCEN), has significant performance improvements over traditional log-scaled mel-frequency spectrograms in acoustic sound event detection (SED) in a multi-class setting with overlapping events. However, the configuration of PCEN's parameters is sensitive to the recording environment, the characteristics of the class of events of interest, and the presence of multiple overlapping events. This leads to improvements on a class-by-class basis, but poor cross-class performance. In this article, we experiment using PCEN spectrograms as an alternative method for SED in urban audio using the UrbanSED dataset, demonstrating per-class improvements based on parameter configuration. Furthermore, we address cross-class performance with PCEN using a novel method, Multi-Rate PCEN (MRPCEN). We demonstrate cross-class SED performance with MRPCEN, demonstrating improvements to cross-class performance compared to traditional single-rate PCEN.