 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Demand-Driven Perspective on Generative Audio AI
Jul 10, 2023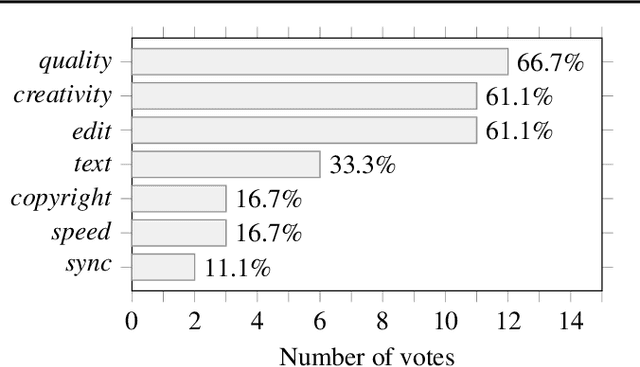
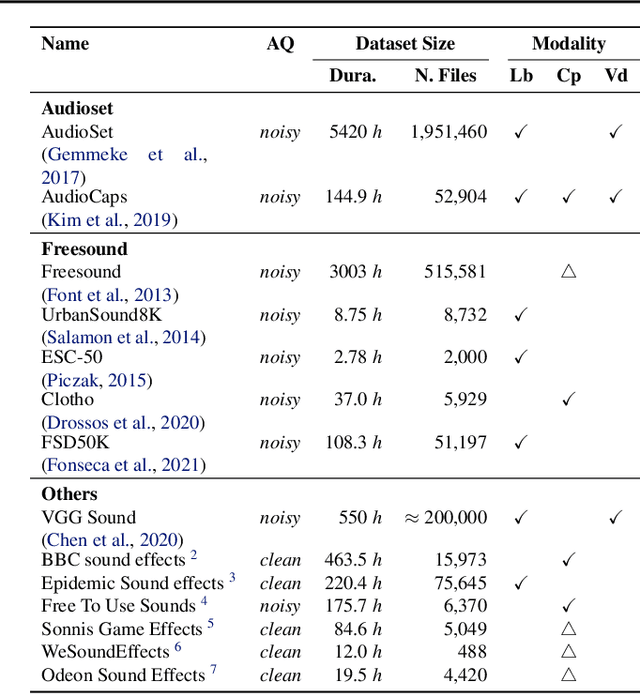
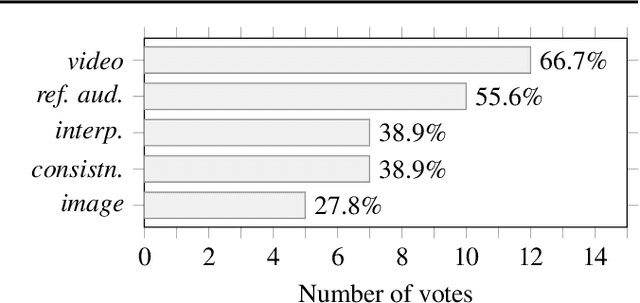

To achieve successful deployment of AI research, it is crucial to understand the demands of the industry. In this paper, we present the results of a survey conducted with professional audio engineers, in order to determine research priorities and define various research tasks. We also summarize the current challenges in audio quality and controllability based on the survey. Our analysis emphasizes that the availability of datasets is currently the main bottleneck for achieving high-quality audio generation. Finally, we suggest potential solutions for some revealed issues with empirical evidence.
FALL-E: A Foley Sound Synthesis Model and Strategies
Jun 16, 2023This paper introduces FALL-E, a foley synthesis system and its training/inference strategies. The FALL-E model employs a cascaded approach comprising low-resolution spectrogram generation, spectrogram super-resolution, and a vocoder. We trained every sound-related model from scratch using our extensive datasets, and utilized a pre-trained language model. We conditioned the model with dataset-specific texts, enabling it to learn sound quality and recording environment based on text input. Moreover, we leveraged external language models to improve text descriptions of our datasets and performed prompt engineering for quality, coherence, and diversity. FALL-E was evaluated by an objective measure as well as listening tests in the DCASE 2023 challenge Task 7. The submission achieved the second place on average, while achieving the best score for diversity, second place for audio quality, and third place for class fitness.
A Proposal for Foley Sound Synthesis Challenge
Jul 21, 2022"Foley" refers to sound effects that are added to multimedia during post-production to enhance its perceived acoustic properties, e.g., by simulating the sounds of footsteps, ambient environmental sounds, or visible objects on the screen. While foley is traditionally produced by foley artists, there is increasing interest in automatic or machine-assisted techniques building upon recent advances in sound synthesis and generative models. To foster more participation in this growing research area, we propose a challenge for automatic foley synthesis. Through case studies on successful previous challenges in audio and machine learning, we set the goals of the proposed challenge: rigorous, unified, and efficient evaluation of different foley synthesis systems, with an overarching goal of drawing active participation from the research community. We outline the details and design considerations of a foley sound synthesis challenge, including task definition, dataset requirements, and evaluation criteria.
ReCAB-VAE: Gumbel-Softmax Variational Inference Based on Analytic Divergence
May 09, 2022
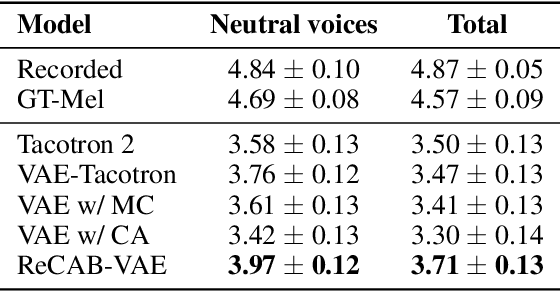


The Gumbel-softmax distribution, or Concrete distribution, is often used to relax the discrete characteristics of a categorical distribution and enable back-propagation through differentiable reparameterization. Although it reliably yields low variance gradients, it still relies on a stochastic sampling process for optimization. In this work, we present a relaxed categorical analytic bound (ReCAB), a novel divergence-like metric which corresponds to the upper bound of the Kullback-Leibler divergence (KLD) of a relaxed categorical distribution. The proposed metric is easy to implement because it has a closed form solution, and empirical results show that it is close to the actual KLD. Along with this new metric, we propose a relaxed categorical analytic bound variational autoencoder (ReCAB-VAE) that successfully models both continuous and relaxed discrete latent representations. We implement an emotional text-to-speech synthesis system based on the proposed framework, and show that the proposed system flexibly and stably controls emotion expressions with better speech quality compared to baselines that use stochastic estimation or categorical distribution approximation.
Facetron: Multi-speaker Face-to-Speech Model based on Cross-modal Latent Representations
Jul 26, 2021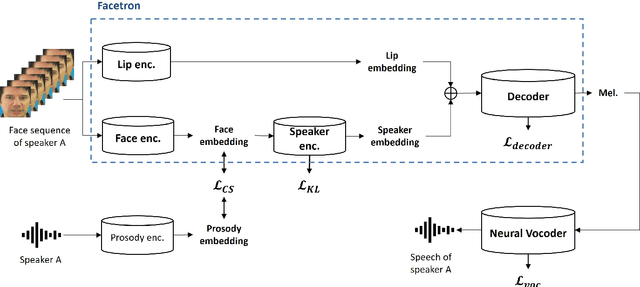
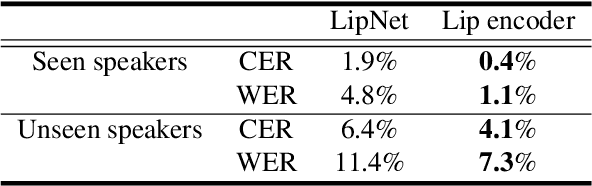
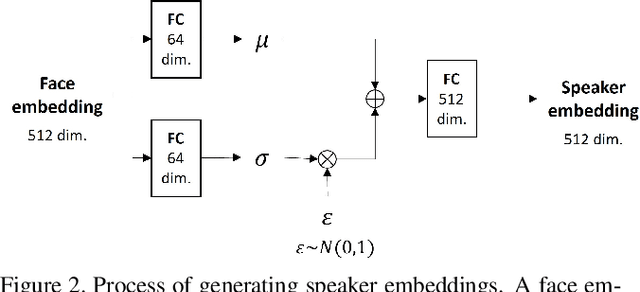

In this paper, we propose an effective method to synthesize speaker-specific speech waveforms by conditioning on videos of an individual's face. Using a generative adversarial network (GAN) with linguistic and speaker characteristic features as auxiliary conditions, our method directly converts face images into speech waveforms under an end-to-end training framework. The linguistic features are extracted from lip movements using a lip-reading model, and the speaker characteristic features are predicted from face images using cross-modal learning with a pre-trained acoustic model. Since these two features are uncorrelated and controlled independently, we can flexibly synthesize speech waveforms whose speaker characteristics vary depending on the input face images. Therefore, our method can be regarded as a multi-speaker face-to-speech waveform model. We show the superiority of our proposed model over conventional methods in terms of both objective and subjective evaluation results. Specifically, we evaluate the performances of the linguistic feature and the speaker characteristic generation modules by measuring the accuracy of automatic speech recognition and automatic speaker/gender recognition tasks, respectively. We also evaluate the naturalness of the synthesized speech waveforms using a mean opinion score (MOS) test.