 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinWeaver: An LLM-Based Foundation Model Framework for Pan-Cancer Digital Twins
Jan 28, 2026Precision oncology requires forecasting clinical events and trajectories, yet modeling sparse, multi-modal clinical time series remains a critical challenge. We introduce TwinWeaver, an open-source framework that serializes longitudinal patient histories into text, enabling unified event prediction as well as forecasting with large language models, and use it to build Genie Digital Twin (GDT) on 93,054 patients across 20 cancer types. In benchmarks, GDT significantly reduces forecasting error, achieving a median Mean Absolute Scaled Error (MASE) of 0.87 compared to 0.97 for the strongest time-series baseline (p<0.001). Furthermore, GDT improves risk stratification, achieving an average concordance index (C-index) of 0.703 across survival, progression, and therapy switching tasks, surpassing the best baseline of 0.662. GDT also generalizes to out-of-distribution clinical trials, matching trained baselines at zero-shot and surpassing them with fine-tuning, achieving a median MASE of 0.75-0.88 and outperforming the strongest baseline in event prediction with an average C-index of 0.672 versus 0.648. Finally, TwinWeaver enables an interpretable clinical reasoning extension, providing a scalable and transparent foundation for longitudinal clinical modeling.
Solar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
TalkPlay-Tools: Conversational Music Recommendation with LLM Tool Calling
Oct 02, 2025



While the recent developments in large language models (LLMs) have successfully enabled generative recommenders with natural language interactions, their recommendation behavior is limited, leaving other simpler yet crucial components such as metadata or attribute filtering underutilized in the system. We propose an LLM-based music recommendation system with tool calling to serve as a unified retrieval-reranking pipeline. Our system positions an LLM as an end-to-end recommendation system that interprets user intent, plans tool invocations, and orchestrates specialized components: boolean filters (SQL), sparse retrieval (BM25), dense retrieval (embedding similarity), and generative retrieval (semantic IDs). Through tool planning, the system predicts which types of tools to use, their execution order, and the arguments needed to find music matching user preferences, supporting diverse modalities while seamlessly integrating multiple database filtering methods. We demonstrate that this unified tool-calling framework achieves competitive performance across diverse recommendation scenarios by selectively employing appropriate retrieval methods based on user queries, envisioning a new paradigm for conversational music recommendation systems.
KAD: No More FAD! An Effective and Efficient Evaluation Metric for Audio Generation
Feb 21, 2025Although being widely adopted for evaluating generated audio signals, the Fr\'echet Audio Distance (FAD) suffers from significant limitations, including reliance on Gaussian assumptions, sensitivity to sample size, and high computational complexity. As an alternative, we introduce the Kernel Audio Distance (KAD), a novel, distribution-free, unbiased, and computationally efficient metric based on Maximum Mean Discrepancy (MMD). Through analysis and empirical validation, we demonstrate KAD's advantages: (1) faster convergence with smaller sample sizes, enabling reliable evaluation with limited data; (2) lower computational cost, with scalable GPU acceleration; and (3) stronger alignment with human perceptual judgments. By leveraging advanced embeddings and characteristic kernels, KAD captures nuanced differences between real and generated audio. Open-sourced in the kadtk toolkit, KAD provides an efficient, reliable, and perceptually aligned benchmark for evaluating generative audio models.
TALKPLAY: Multimodal Music Recommendation with Large Language Models
Feb 20, 2025



We present TalkPlay, a multimodal music recommendation system that reformulates the recommendation task as large language model token generation. TalkPlay represents music through an expanded token vocabulary that encodes multiple modalities - audio, lyrics, metadata, semantic tags, and playlist co-occurrence. Using these rich representations, the model learns to generate recommendations through next-token prediction on music recommendation conversations, that requires learning the associations natural language query and response, as well as music items. In other words, the formulation transforms music recommendation into a natural language understanding task, where the model's ability to predict conversation tokens directly optimizes query-item relevance. Our approach eliminates traditional recommendation-dialogue pipeline complexity, enabling end-to-end learning of query-aware music recommendations. In the experiment, TalkPlay is successfully trained and outperforms baseline methods in various aspects, demonstrating strong context understanding as a conversational music recommender.
Sound Scene Synthesis at the DCASE 2024 Challenge
Jan 15, 2025This paper presents Task 7 at the DCASE 2024 Challenge: sound scene synthesis. Recent advances in sound synthesis and generative models have enabled the creation of realistic and diverse audio content. We introduce a standardized evaluation framework for comparing different sound scene synthesis systems, incorporating both objective and subjective metrics. The challenge attracted four submissions, which are evaluated using the Fr\'echet Audio Distance (FAD) and human perceptual ratings. Our analysis reveals significant insights into the current capabilities and limitations of sound scene synthesis systems, while also highlighting areas for future improvement in this rapidly evolving field.
Music Discovery Dialogue Generation Using Human Intent Analysis and Large Language Models
Nov 11, 2024A conversational music retrieval system can help users discover music that matches their preferences through dialogue. To achieve this, a conversational music retrieval system should seamlessly engage in multi-turn conversation by 1) understanding user queries and 2) responding with natural language and retrieved music. A straightforward solution would be a data-driven approach utilizing such conversation logs. However, few datasets are available for the research and are limited in terms of volume and quality. In this paper, we present a data generation framework for rich music discovery dialogue using a large language model (LLM) and user intents, system actions, and musical attributes. This is done by i) dialogue intent analysis using grounded theory, ii) generating attribute sequences via cascading database filtering, and iii) generating utterances using large language models. By applying this framework to the Million Song dataset, we create LP-MusicDialog, a Large Language Model based Pseudo Music Dialogue dataset, containing over 288k music conversations using more than 319k music items. Our evaluation shows that the synthetic dataset is competitive with an existing, small human dialogue dataset in terms of dialogue consistency, item relevance, and naturalness. Furthermore, using the dataset, we train a conversational music retrieval model and show promising results.
Challenge on Sound Scene Synthesis: Evaluating Text-to-Audio Generation
Oct 23, 2024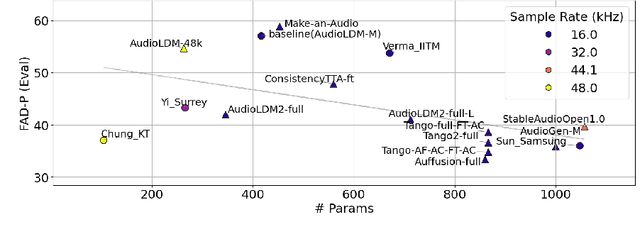
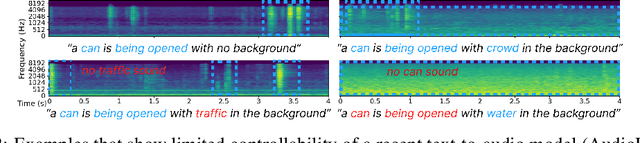
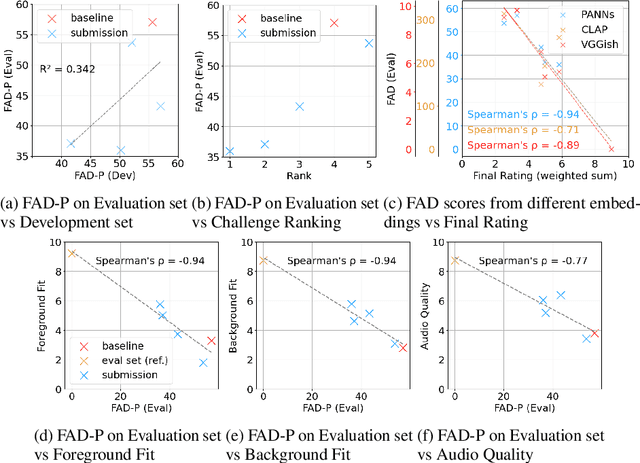
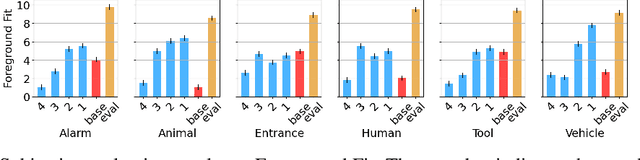
Despite significant advancements in neural text-to-audio generation, challenges persist in controllability and evaluation. This paper addresses these issues through the Sound Scene Synthesis challenge held as part of the Detection and Classification of Acoustic Scenes and Events 2024. We present an evaluation protocol combining objective metric, namely Fr\'echet Audio Distance, with perceptual assessments, utilizing a structured prompt format to enable diverse captions and effective evaluation. Our analysis reveals varying performance across sound categories and model architectures, with larger models generally excelling but innovative lightweight approaches also showing promise. The strong correlation between objective metrics and human ratings validates our evaluation approach. We discuss outcomes in terms of audio quality, controllability, and architectural considerations for text-to-audio synthesizers, providing direction for future research.
Correlation of Fréchet Audio Distance With Human Perception of Environmental Audio Is Embedding Dependant
Mar 26, 2024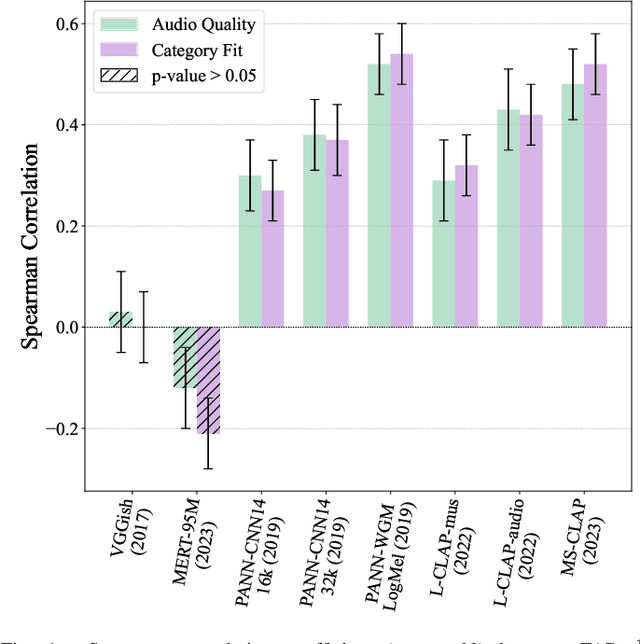
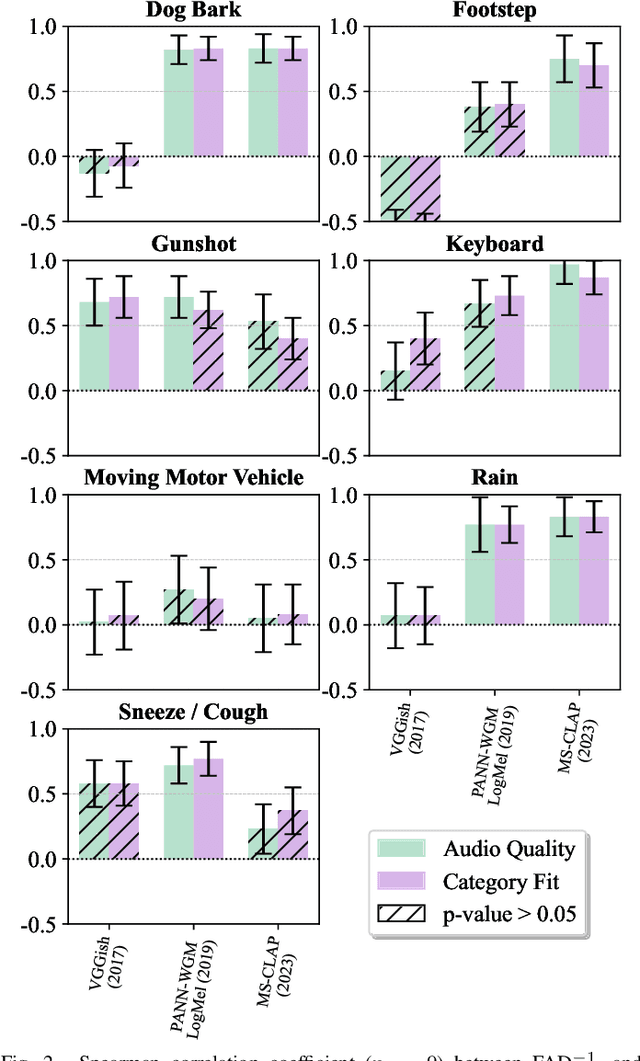
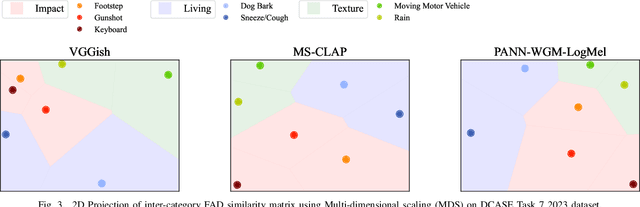
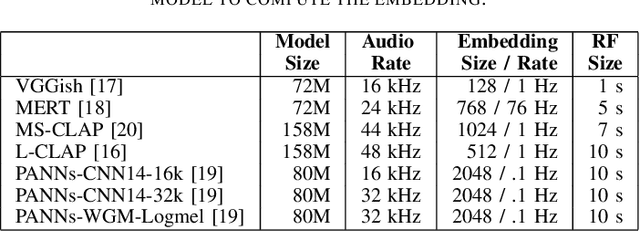
This paper explores whether considering alternative domain-specific embeddings to calculate the Fr\'echet Audio Distance (FAD) metric can help the FAD to correlate better with perceptual ratings of environmental sounds. We used embeddings from VGGish, PANNs, MS-CLAP, L-CLAP, and MERT, which are tailored for either music or environmental sound evaluation. The FAD scores were calculated for sounds from the DCASE 2023 Task 7 dataset. Using perceptual data from the same task, we find that PANNs-WGM-LogMel produces the best correlation between FAD scores and perceptual ratings of both audio quality and perceived fit with a Spearman correlation higher than 0.5. We also find that music-specific embeddings resulted in significantly lower results. Interestingly, VGGish, the embedding used for the original Fr\'echet calculation, yielded a correlation below 0.1. These results underscore the critical importance of the choice of embedding for the FAD metric design.
The Biased Journey of MSD_AUDIO.ZIP
Sep 02, 2023The equitable distribution of academic data is crucial for ensuring equal research opportunities, and ultimately further progress. Yet, due to the complexity of using the API for audio data that corresponds to the Million Song Dataset along with its misreporting (before 2016) and the discontinuation of this API (after 2016), access to this data has become restricted to those within certain affiliations that are connected peer-to-peer. In this paper, we delve into this issue, drawing insights from the experiences of 22 individuals who either attempted to access the data or played a role in its creation. With this, we hope to initiate more critical dialogue and more thoughtful consideration with regard to access privilege in the MIR community.