 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalkPlay-Tools: Conversational Music Recommendation with LLM Tool Calling
Oct 02, 2025



While the recent developments in large language models (LLMs) have successfully enabled generative recommenders with natural language interactions, their recommendation behavior is limited, leaving other simpler yet crucial components such as metadata or attribute filtering underutilized in the system. We propose an LLM-based music recommendation system with tool calling to serve as a unified retrieval-reranking pipeline. Our system positions an LLM as an end-to-end recommendation system that interprets user intent, plans tool invocations, and orchestrates specialized components: boolean filters (SQL), sparse retrieval (BM25), dense retrieval (embedding similarity), and generative retrieval (semantic IDs). Through tool planning, the system predicts which types of tools to use, their execution order, and the arguments needed to find music matching user preferences, supporting diverse modalities while seamlessly integrating multiple database filtering methods. We demonstrate that this unified tool-calling framework achieves competitive performance across diverse recommendation scenarios by selectively employing appropriate retrieval methods based on user queries, envisioning a new paradigm for conversational music recommendation systems.
PianoBind: A Multimodal Joint Embedding Model for Pop-piano Music
Sep 04, 2025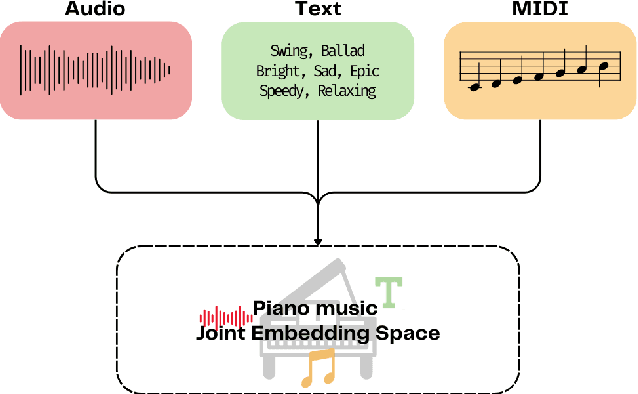

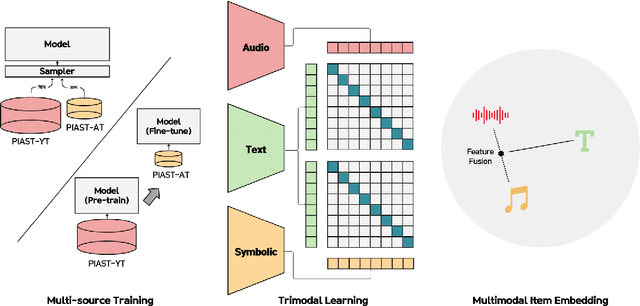

Solo piano music, despite being a single-instrument medium, possesses significant expressive capabilities, conveying rich semantic information across genres, moods, and styles. However, current general-purpose music representation models, predominantly trained on large-scale datasets, often struggle to captures subtle semantic distinctions within homogeneous solo piano music. Furthermore, existing piano-specific representation models are typically unimodal, failing to capture the inherently multimodal nature of piano music, expressed through audio, symbolic, and textual modalities. To address these limitations, we propose PianoBind, a piano-specific multimodal joint embedding model. We systematically investigate strategies for multi-source training and modality utilization within a joint embedding framework optimized for capturing fine-grained semantic distinctions in (1) small-scale and (2) homogeneous piano datasets. Our experimental results demonstrate that PianoBind learns multimodal representations that effectively capture subtle nuances of piano music, achieving superior text-to-music retrieval performance on in-domain and out-of-domain piano datasets compared to general-purpose music joint embedding models. Moreover, our design choices offer reusable insights for multimodal representation learning with homogeneous datasets beyond piano music.
Can Large Language Models Predict Audio Effects Parameters from Natural Language?
May 27, 2025
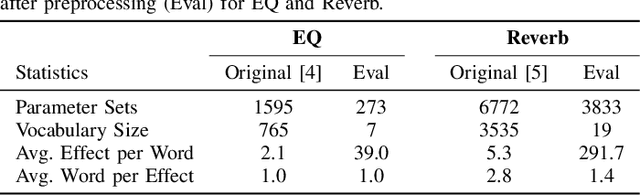
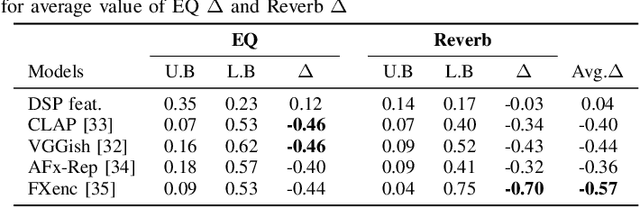
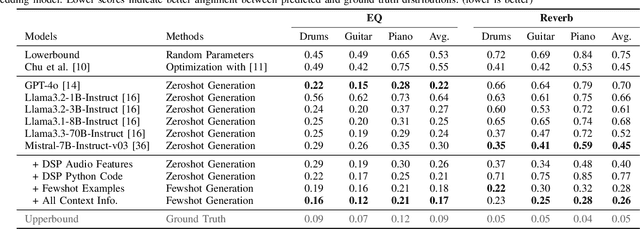
In music production, manipulating audio effects (Fx) parameters through natural language has the potential to reduce technical barriers for non-experts. We present LLM2Fx, a framework leveraging Large Language Models (LLMs) to predict Fx parameters directly from textual descriptions without requiring task-specific training or fine-tuning. Our approach address the text-to-effect parameter prediction (Text2Fx) task by mapping natural language descriptions to the corresponding Fx parameters for equalization and reverberation. We demonstrate that LLMs can generate Fx parameters in a zero-shot manner that elucidates the relationship between timbre semantics and audio effects in music production. To enhance performance, we introduce three types of in-context examples: audio Digital Signal Processing (DSP) features, DSP function code, and few-shot examples. Our results demonstrate that LLM-based Fx parameter generation outperforms previous optimization approaches, offering competitive performance in translating natural language descriptions to appropriate Fx settings. Furthermore, LLMs can serve as text-driven interfaces for audio production, paving the way for more intuitive and accessible music production tools.
TALKPLAY: Multimodal Music Recommendation with Large Language Models
Feb 20, 2025



We present TalkPlay, a multimodal music recommendation system that reformulates the recommendation task as large language model token generation. TalkPlay represents music through an expanded token vocabulary that encodes multiple modalities - audio, lyrics, metadata, semantic tags, and playlist co-occurrence. Using these rich representations, the model learns to generate recommendations through next-token prediction on music recommendation conversations, that requires learning the associations natural language query and response, as well as music items. In other words, the formulation transforms music recommendation into a natural language understanding task, where the model's ability to predict conversation tokens directly optimizes query-item relevance. Our approach eliminates traditional recommendation-dialogue pipeline complexity, enabling end-to-end learning of query-aware music recommendations. In the experiment, TalkPlay is successfully trained and outperforms baseline methods in various aspects, demonstrating strong context understanding as a conversational music recommender.
PIAST: A Multimodal Piano Dataset with Audio, Symbolic and Text
Nov 04, 2024



While piano music has become a significant area of study in Music Information Retrieval (MIR), there is a notable lack of datasets for piano solo music with text labels. To address this gap, we present PIAST (PIano dataset with Audio, Symbolic, and Text), a piano music dataset. Utilizing a piano-specific taxonomy of semantic tags, we collected 9,673 tracks from YouTube and added human annotations for 2,023 tracks by music experts, resulting in two subsets: PIAST-YT and PIAST-AT. Both include audio, text, tag annotations, and transcribed MIDI utilizing state-of-the-art piano transcription and beat tracking models. Among many possible tasks with the multi-modal dataset, we conduct music tagging and retrieval using both audio and MIDI data and report baseline performances to demonstrate its potential as a valuable resource for MIR research.
EMOPIA: A Multi-Modal Pop Piano Dataset For Emotion Recognition and Emotion-based Music Generation
Aug 03, 2021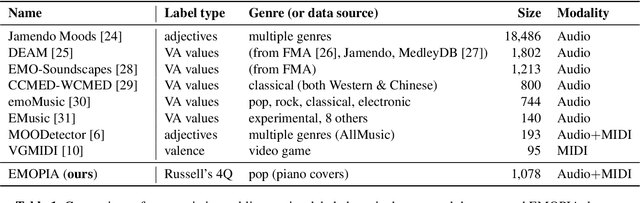
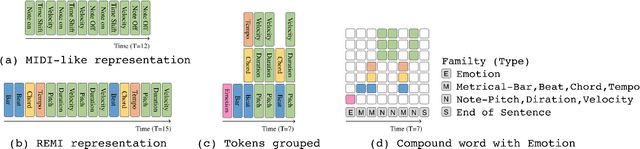
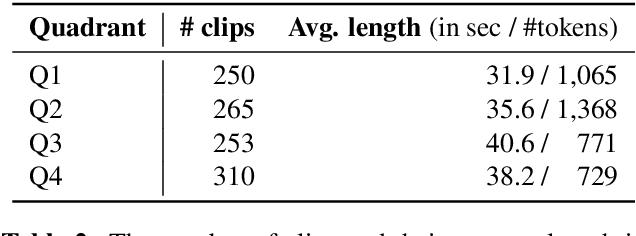
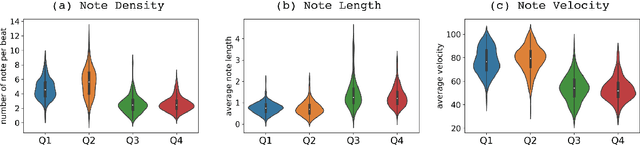
While there are many music datasets with emotion labels in the literature, they cannot be used for research on symbolic-domain music analysis or generation, as there are usually audio files only. In this paper, we present the EMOPIA (pronounced `yee-m\`{o}-pi-uh') dataset, a shared multi-modal (audio and MIDI) database focusing on perceived emotion in pop piano music, to facilitate research on various tasks related to music emotion. The dataset contains 1,087 music clips from 387 songs and clip-level emotion labels annotated by four dedicated annotators. Since the clips are not restricted to one clip per song, they can also be used for song-level analysis. We present the methodology for building the dataset, covering the song list curation, clip selection, and emotion annotation processes. Moreover, we prototype use cases on clip-level music emotion classification and emotion-based symbolic music generation by training and evaluating corresponding models using the dataset. The result demonstrates the potential of EMOPIA for being used in future exploration on piano emotion-related MIR tasks.
TräumerAI: Dreaming Music with StyleGAN
Feb 09, 2021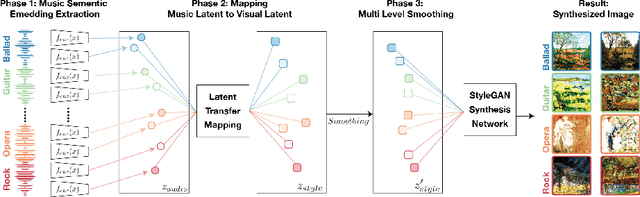


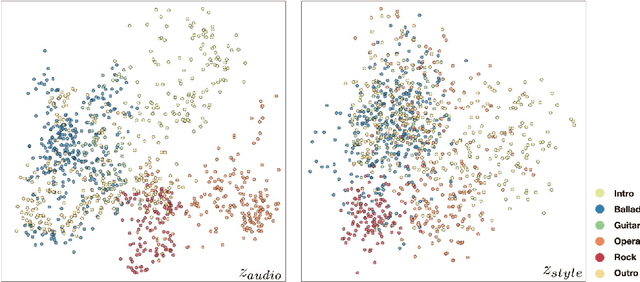
The goal of this paper to generate a visually appealing video that responds to music with a neural network so that each frame of the video reflects the musical characteristics of the corresponding audio clip. To achieve the goal, we propose a neural music visualizer directly mapping deep music embeddings to style embeddings of StyleGAN, named Tr\"aumerAI, which consists of a music auto-tagging model using short-chunk CNN and StyleGAN2 pre-trained on WikiArt dataset. Rather than establishing an objective metric between musical and visual semantics, we manually labeled the pairs in a subjective manner. An annotator listened to 100 music clips of 10 seconds long and selected an image that suits the music among the 200 StyleGAN-generated examples. Based on the collected data, we trained a simple transfer function that converts an audio embedding to a style embedding. The generated examples show that the mapping between audio and video makes a certain level of intra-segment similarity and inter-segment dissimilarity.
Musical Word Embedding: Bridging the Gap between Listening Contexts and Music
Jul 23, 2020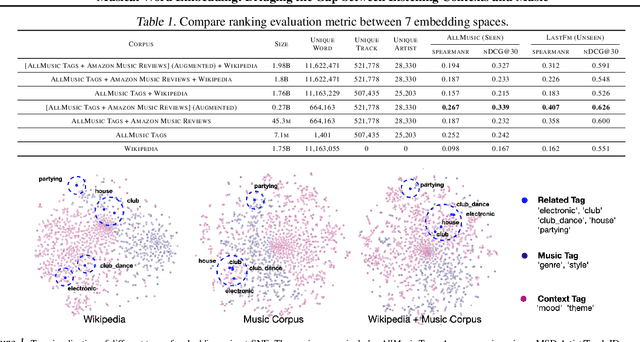
Word embedding pioneered by Mikolov et al. is a staple technique for word representations in natural language processing (NLP) research which has also found popularity in music information retrieval tasks. Depending on the type of text data for word embedding, however, vocabulary size and the degree of musical pertinence can significantly vary. In this work, we (1) train the distributed representation of words using combinations of both general text data and music-specific data and (2) evaluate the system in terms of how they associate listening contexts with musical compositions.