 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Music Mixing using a Generative Model of Effect Embeddings
Nov 11, 2025Music mixing involves combining individual tracks into a cohesive mixture, a task characterized by subjectivity where multiple valid solutions exist for the same input. Existing automatic mixing systems treat this task as a deterministic regression problem, thus ignoring this multiplicity of solutions. Here we introduce MEGAMI (Multitrack Embedding Generative Auto MIxing), a generative framework that models the conditional distribution of professional mixes given unprocessed tracks. MEGAMI uses a track-agnostic effects processor conditioned on per-track generated embeddings, handles arbitrary unlabeled tracks through a permutation-equivariant architecture, and enables training on both dry and wet recordings via domain adaptation. Our objective evaluation using distributional metrics shows consistent improvements over existing methods, while listening tests indicate performances approaching human-level quality across diverse musical genres.
Reverse Engineering of Music Mixing Graphs with Differentiable Processors and Iterative Pruning
Sep 19, 2025



Reverse engineering of music mixes aims to uncover how dry source signals are processed and combined to produce a final mix. We extend the prior works to reflect the compositional nature of mixing and search for a graph of audio processors. First, we construct a mixing console, applying all available processors to every track and subgroup. With differentiable processor implementations, we optimize their parameters with gradient descent. Then, we repeat the process of removing negligible processors and fine-tuning the remaining ones. This way, the quality of the full mixing console can be preserved while removing approximately two-thirds of the processors. The proposed method can be used not only to analyze individual music mixes but also to collect large-scale graph data that can be used for downstream tasks, e.g., automatic mixing. Especially for the latter purpose, efficient implementation of the search is crucial. To this end, we present an efficient batch-processing method that computes multiple processors in parallel. We also exploit the "dry/wet" parameter of the processors to accelerate the search. Extensive quantitative and qualitative analyses are conducted to evaluate the proposed method's performance, behavior, and computational cost.
Concept-TRAK: Understanding how diffusion models learn concepts through concept-level attribution
Jul 09, 2025



While diffusion models excel at image generation, their growing adoption raises critical concerns around copyright issues and model transparency. Existing attribution methods identify training examples influencing an entire image, but fall short in isolating contributions to specific elements, such as styles or objects, that matter most to stakeholders. To bridge this gap, we introduce \emph{concept-level attribution} via a novel method called \emph{Concept-TRAK}. Concept-TRAK extends influence functions with two key innovations: (1) a reformulated diffusion training loss based on diffusion posterior sampling, enabling robust, sample-specific attribution; and (2) a concept-aware reward function that emphasizes semantic relevance. We evaluate Concept-TRAK on the AbC benchmark, showing substantial improvements over prior methods. Through diverse case studies--ranging from identifying IP-protected and unsafe content to analyzing prompt engineering and compositional learning--we demonstrate how concept-level attribution yields actionable insights for responsible generative AI development and governance.
Fx-Encoder++: Extracting Instrument-Wise Audio Effects Representations from Mixtures
Jul 03, 2025General-purpose audio representations have proven effective across diverse music information retrieval applications, yet their utility in intelligent music production remains limited by insufficient understanding of audio effects (Fx). Although previous approaches have emphasized audio effects analysis at the mixture level, this focus falls short for tasks demanding instrument-wise audio effects understanding, such as automatic mixing. In this work, we present Fx-Encoder++, a novel model designed to extract instrument-wise audio effects representations from music mixtures. Our approach leverages a contrastive learning framework and introduces an "extractor" mechanism that, when provided with instrument queries (audio or text), transforms mixture-level audio effects embeddings into instrument-wise audio effects embeddings. We evaluated our model across retrieval and audio effects parameter matching tasks, testing its performance across a diverse range of instruments. The results demonstrate that Fx-Encoder++ outperforms previous approaches at mixture level and show a novel ability to extract effects representation instrument-wise, addressing a critical capability gap in intelligent music production systems.
Can Large Language Models Predict Audio Effects Parameters from Natural Language?
May 27, 2025
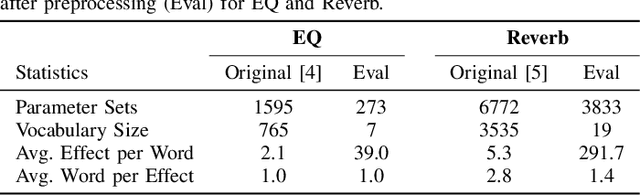
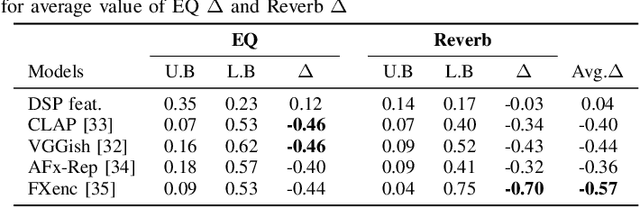
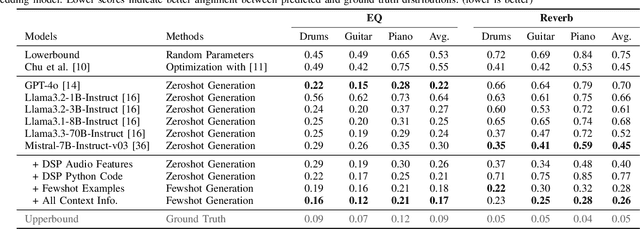
In music production, manipulating audio effects (Fx) parameters through natural language has the potential to reduce technical barriers for non-experts. We present LLM2Fx, a framework leveraging Large Language Models (LLMs) to predict Fx parameters directly from textual descriptions without requiring task-specific training or fine-tuning. Our approach address the text-to-effect parameter prediction (Text2Fx) task by mapping natural language descriptions to the corresponding Fx parameters for equalization and reverberation. We demonstrate that LLMs can generate Fx parameters in a zero-shot manner that elucidates the relationship between timbre semantics and audio effects in music production. To enhance performance, we introduce three types of in-context examples: audio Digital Signal Processing (DSP) features, DSP function code, and few-shot examples. Our results demonstrate that LLM-based Fx parameter generation outperforms previous optimization approaches, offering competitive performance in translating natural language descriptions to appropriate Fx settings. Furthermore, LLMs can serve as text-driven interfaces for audio production, paving the way for more intuitive and accessible music production tools.
A Comprehensive Real-World Assessment of Audio Watermarking Algorithms: Will They Survive Neural Codecs?
May 26, 2025We present a framework to foster the evaluation of deep learning-based audio watermarking algorithms, establishing a standardized benchmark and allowing systematic comparisons. To simulate real-world usage, we introduce a comprehensive audio attack pipeline, featuring various distortions such as compression, background noise, and reverberation, and propose a diverse test dataset, including speech, environmental sounds, and music recordings. By assessing the performance of four existing watermarking algorithms on our framework, two main insights stand out: (i) neural compression techniques pose the most significant challenge, even when algorithms are trained with such compressions; and (ii) training with audio attacks generally improves robustness, although it is insufficient in some cases. Furthermore, we find that specific distortions, such as polarity inversion, time stretching, or reverb, seriously affect certain algorithms. Our contributions strengthen the robustness and perceptual assessment of audio watermarking algorithms across a wide range of applications, while ensuring a fair and consistent evaluation approach. The evaluation framework, including the attack pipeline, is accessible at github.com/SonyResearch/wm_robustness_eval.
Improving Inference-Time Optimisation for Vocal Effects Style Transfer with a Gaussian Prior
May 16, 2025Style Transfer with Inference-Time Optimisation (ST-ITO) is a recent approach for transferring the applied effects of a reference audio to a raw audio track. It optimises the effect parameters to minimise the distance between the style embeddings of the processed audio and the reference. However, this method treats all possible configurations equally and relies solely on the embedding space, which can lead to unrealistic or biased results. We address this pitfall by introducing a Gaussian prior derived from a vocal preset dataset, DiffVox, over the parameter space. The resulting optimisation is equivalent to maximum-a-posteriori estimation. Evaluations on vocal effects transfer on the MedleyDB dataset show significant improvements across metrics compared to baselines, including a blind audio effects estimator, nearest-neighbour approaches, and uncalibrated ST-ITO. The proposed calibration reduces parameter mean squared error by up to 33% and matches the reference style better. Subjective evaluations with 16 participants confirm our method's superiority, especially in limited data regimes. This work demonstrates how incorporating prior knowledge in inference time enhances audio effects transfer, paving the way for more effective and realistic audio processing systems.
DiffVox: A Differentiable Model for Capturing and Analysing Professional Effects Distributions
Apr 20, 2025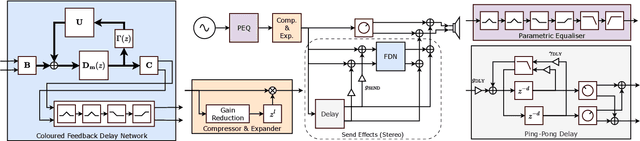

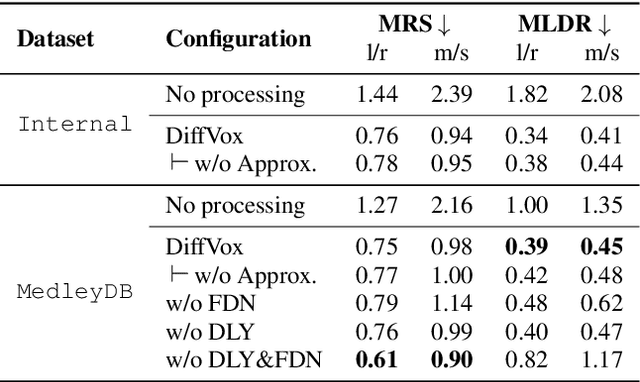
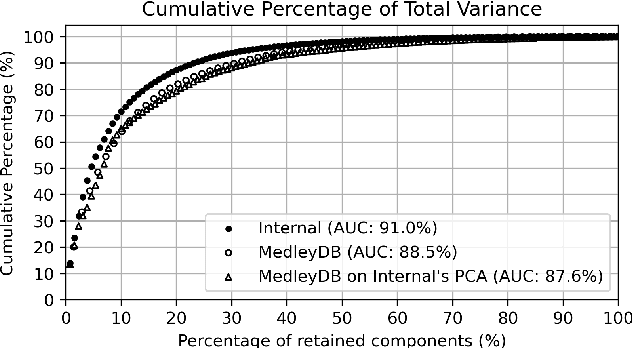
This study introduces a novel and interpretable model, DiffVox, for matching vocal effects in music production. DiffVox, short for ``Differentiable Vocal Fx", integrates parametric equalisation, dynamic range control, delay, and reverb with efficient differentiable implementations to enable gradient-based optimisation for parameter estimation. Vocal presets are retrieved from two datasets, comprising 70 tracks from MedleyDB and 365 tracks from a private collection. Analysis of parameter correlations highlights strong relationships between effects and parameters, such as the high-pass and low-shelf filters often behaving together to shape the low end, and the delay time correlates with the intensity of the delayed signals. Principal component analysis reveals connections to McAdams' timbre dimensions, where the most crucial component modulates the perceived spaciousness while the secondary components influence spectral brightness. Statistical testing confirms the non-Gaussian nature of the parameter distribution, highlighting the complexity of the vocal effects space. These initial findings on the parameter distributions set the foundation for future research in vocal effects modelling and automatic mixing. Our source code and datasets are accessible at https://github.com/SonyResearch/diffvox.
SteerMusic: Enhanced Musical Consistency for Zero-shot Text-Guided and Personalized Music Editing
Apr 15, 2025Music editing is an important step in music production, which has broad applications, including game development and film production. Most existing zero-shot text-guided methods rely on pretrained diffusion models by involving forward-backward diffusion processes for editing. However, these methods often struggle to maintain the music content consistency. Additionally, text instructions alone usually fail to accurately describe the desired music. In this paper, we propose two music editing methods that enhance the consistency between the original and edited music by leveraging score distillation. The first method, SteerMusic, is a coarse-grained zero-shot editing approach using delta denoising score. The second method, SteerMusic+, enables fine-grained personalized music editing by manipulating a concept token that represents a user-defined musical style. SteerMusic+ allows for the editing of music into any user-defined musical styles that cannot be achieved by the text instructions alone. Experimental results show that our methods outperform existing approaches in preserving both music content consistency and editing fidelity. User studies further validate that our methods achieve superior music editing quality. Audio examples are available on https://steermusic.pages.dev/.
Cross-Modal Learning for Music-to-Music-Video Description Generation
Mar 14, 2025Music-to-music-video generation is a challenging task due to the intrinsic differences between the music and video modalities. The advent of powerful text-to-video diffusion models has opened a promising pathway for music-video (MV) generation by first addressing the music-to-MV description task and subsequently leveraging these models for video generation. In this study, we focus on the MV description generation task and propose a comprehensive pipeline encompassing training data construction and multimodal model fine-tuning. We fine-tune existing pre-trained multimodal models on our newly constructed music-to-MV description dataset based on the Music4All dataset, which integrates both musical and visual information. Our experimental results demonstrate that music representations can be effectively mapped to textual domains, enabling the generation of meaningful MV description directly from music inputs. We also identify key components in the dataset construction pipeline that critically impact the quality of MV description and highlight specific musical attributes that warrant greater focus for improved MV description generation.