 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models
Feb 25, 2026Scaling multimodal alignment between video and audio is challenging, particularly due to limited data and the mismatch between text descriptions and frame-level video information. In this work, we tackle the scaling challenge in multimodal-to-audio generation, examining whether models trained on short instances can generalize to longer ones during testing. To tackle this challenge, we present multimodal hierarchical networks so-called MMHNet, an enhanced extension of state-of-the-art video-to-audio models. Our approach integrates a hierarchical method and non-causal Mamba to support long-form audio generation. Our proposed method significantly improves long audio generation up to more than 5 minutes. We also prove that training short and testing long is possible in the video-to-audio generation tasks without training on the longer durations. We show in our experiments that our proposed method could achieve remarkable results on long-video to audio benchmarks, beating prior works in video-to-audio tasks. Moreover, we showcase our model capability in generating more than 5 minutes, while prior video-to-audio methods fall short in generating with long durations.
Do Foundational Audio Encoders Understand Music Structure?
Dec 19, 2025In music information retrieval (MIR) research, the use of pretrained foundational audio encoders (FAEs) has recently become a trend. FAEs pretrained on large amounts of music and audio data have been shown to improve performance on MIR tasks such as music tagging and automatic music transcription. However, their use for music structure analysis (MSA) remains underexplored. Although many open-source FAE models are available, only a small subset has been examined for MSA, and the impact of factors such as learning methods, training data, and model context length on MSA performance remains unclear. In this study, we conduct comprehensive experiments on 11 types of FAEs to investigate how these factors affect MSA performance. Our results demonstrate that FAEs using selfsupervised learning with masked language modeling on music data are particularly effective for MSA. These findings pave the way for future research in MSA.
VIRTUE: Visual-Interactive Text-Image Universal Embedder
Oct 01, 2025Multimodal representation learning models have demonstrated successful operation across complex tasks, and the integration of vision-language models (VLMs) has further enabled embedding models with instruction-following capabilities. However, existing embedding models lack visual-interactive capabilities to specify regions of interest from users (e.g., point, bounding box, mask), which have been explored in generative models to broaden their human-interactive applicability. Equipping embedding models with visual interactions not only would unlock new applications with localized grounding of user intent, which remains unexplored, but also enable the models to learn entity-level information within images to complement their global representations for conventional embedding tasks. In this paper, we propose a novel Visual-InteRactive Text-Image Universal Embedder (VIRTUE) that extends the capabilities of the segmentation model and the vision-language model to the realm of representation learning. In VIRTUE, the segmentation model can process visual prompts that pinpoint specific regions within an image, thereby enabling the embedder to handle complex and ambiguous scenarios more precisely. To evaluate the visual-interaction ability of VIRTUE, we introduce a large-scale Segmentation-and-Scene Caption Retrieval (SCaR) benchmark comprising 1M samples that aims to retrieve the text caption by jointly considering the entity with a specific object and image scene. VIRTUE consistently achieves a state-of-the-art performance with significant improvements across 36 universal MMEB (3.1%-8.5%) and five visual-interactive SCaR (15.2%-20.3%) tasks.
TITAN-Guide: Taming Inference-Time AligNment for Guided Text-to-Video Diffusion Models
Aug 01, 2025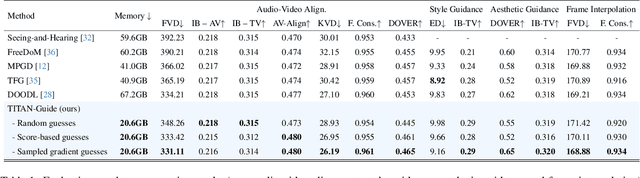



In the recent development of conditional diffusion models still require heavy supervised fine-tuning for performing control on a category of tasks. Training-free conditioning via guidance with off-the-shelf models is a favorable alternative to avoid further fine-tuning on the base model. However, the existing training-free guidance frameworks either have heavy memory requirements or offer sub-optimal control due to rough estimation. These shortcomings limit the applicability to control diffusion models that require intense computation, such as Text-to-Video (T2V) diffusion models. In this work, we propose Taming Inference Time Alignment for Guided Text-to-Video Diffusion Model, so-called TITAN-Guide, which overcomes memory space issues, and provides more optimal control in the guidance process compared to the counterparts. In particular, we develop an efficient method for optimizing diffusion latents without backpropagation from a discriminative guiding model. In particular, we study forward gradient descents for guided diffusion tasks with various options on directional directives. In our experiments, we demonstrate the effectiveness of our approach in efficiently managing memory during latent optimization, while previous methods fall short. Our proposed approach not only minimizes memory requirements but also significantly enhances T2V performance across a range of diffusion guidance benchmarks. Code, models, and demo are available at https://titanguide.github.io.
Schrödinger Bridge Consistency Trajectory Models for Speech Enhancement
Jul 16, 2025Speech enhancement (SE) utilizing diffusion models is a promising technology that improves speech quality in noisy speech data. Furthermore, the Schr\"odinger bridge (SB) has recently been used in diffusion-based SE to improve speech quality by resolving a mismatch between the endpoint of the forward process and the starting point of the reverse process. However, the SB still exhibits slow inference owing to the necessity of a large number of function evaluations (NFE) for inference to obtain high-quality results. While Consistency Models (CMs) address this issue by employing consistency training that uses distillation from pretrained models in the field of image generation, it does not improve generation quality when the number of steps increases. As a solution to this problem, Consistency Trajectory Models (CTMs) not only accelerate inference speed but also maintain a favorable trade-off between quality and speed. Furthermore, SoundCTM demonstrates the applicability of CTM techniques to the field of sound generation. In this paper, we present Schr\"odinger bridge Consistency Trajectory Models (SBCTM) by applying the CTM's technique to the Schr\"odinger bridge for SE. Additionally, we introduce a novel auxiliary loss, including a perceptual loss, into the original CTM's training framework. As a result, SBCTM achieves an approximately 16x improvement in the real-time factor (RTF) compared to the conventional Schr\"odinger bridge for SE. Furthermore, the favorable trade-off between quality and speed in SBCTM allows for time-efficient inference by limiting multi-step refinement to cases where 1-step inference is insufficient. Our code, pretrained models, and audio samples are available at https://github.com/sony/sbctm/.
SpecMaskFoley: Steering Pretrained Spectral Masked Generative Transformer Toward Synchronized Video-to-audio Synthesis via ControlNet
May 22, 2025



Foley synthesis aims to synthesize high-quality audio that is both semantically and temporally aligned with video frames. Given its broad application in creative industries, the task has gained increasing attention in the research community. To avoid the non-trivial task of training audio generative models from scratch, adapting pretrained audio generative models for video-synchronized foley synthesis presents an attractive direction. ControlNet, a method for adding fine-grained controls to pretrained generative models, has been applied to foley synthesis, but its use has been limited to handcrafted human-readable temporal conditions. In contrast, from-scratch models achieved success by leveraging high-dimensional deep features extracted using pretrained video encoders. We have observed a performance gap between ControlNet-based and from-scratch foley models. To narrow this gap, we propose SpecMaskFoley, a method that steers the pretrained SpecMaskGIT model toward video-synchronized foley synthesis via ControlNet. To unlock the potential of a single ControlNet branch, we resolve the discrepancy between the temporal video features and the time-frequency nature of the pretrained SpecMaskGIT via a frequency-aware temporal feature aligner, eliminating the need for complicated conditioning mechanisms widely used in prior arts. Evaluations on a common foley synthesis benchmark demonstrate that SpecMaskFoley could even outperform strong from-scratch baselines, substantially advancing the development of ControlNet-based foley synthesis models. Demo page: https://zzaudio.github.io/SpecMaskFoley_Demo/
SAVGBench: Benchmarking Spatially Aligned Audio-Video Generation
Dec 18, 2024



This work addresses the lack of multimodal generative models capable of producing high-quality videos with spatially aligned audio. While recent advancements in generative models have been successful in video generation, they often overlook the spatial alignment between audio and visuals, which is essential for immersive experiences. To tackle this problem, we establish a new research direction in benchmarking Spatially Aligned Audio-Video Generation (SAVG). We propose three key components for the benchmark: dataset, baseline, and metrics. We introduce a spatially aligned audio-visual dataset, derived from an audio-visual dataset consisting of multichannel audio, video, and spatiotemporal annotations of sound events. We propose a baseline audio-visual diffusion model focused on stereo audio-visual joint learning to accommodate spatial sound. Finally, we present metrics to evaluate video and spatial audio quality, including a new spatial audio-visual alignment metric. Our experimental result demonstrates that gaps exist between the baseline model and ground truth in terms of video and audio quality, and spatial alignment between both modalities.
Music Foundation Model as Generic Booster for Music Downstream Tasks
Nov 05, 2024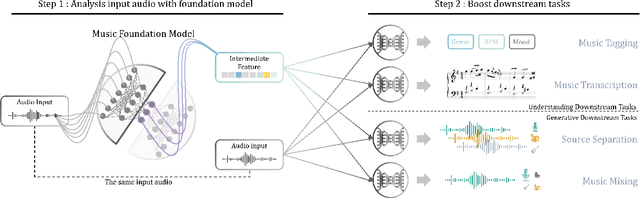


We demonstrate the efficacy of using intermediate representations from a single foundation model to enhance various music downstream tasks. We introduce SoniDo, a music foundation model (MFM) designed to extract hierarchical features from target music samples. By leveraging hierarchical intermediate features, SoniDo constrains the information granularity, leading to improved performance across various downstream tasks including both understanding and generative tasks. We specifically evaluated this approach on representative tasks such as music tagging, music transcription, music source separation, and music mixing. Our results reveal that the features extracted from foundation models provide valuable enhancements in training downstream task models. This highlights the capability of using features extracted from music foundation models as a booster for downstream tasks. Our approach not only benefits existing task-specific models but also supports music downstream tasks constrained by data scarcity. This paves the way for more effective and accessible music processing solutions.
OpenMU: Your Swiss Army Knife for Music Understanding
Oct 21, 2024



We present OpenMU-Bench, a large-scale benchmark suite for addressing the data scarcity issue in training multimodal language models to understand music. To construct OpenMU-Bench, we leveraged existing datasets and bootstrapped new annotations. OpenMU-Bench also broadens the scope of music understanding by including lyrics understanding and music tool usage. Using OpenMU-Bench, we trained our music understanding model, OpenMU, with extensive ablations, demonstrating that OpenMU outperforms baseline models such as MU-Llama. Both OpenMU and OpenMU-Bench are open-sourced to facilitate future research in music understanding and to enhance creative music production efficiency.
Mining Your Own Secrets: Diffusion Classifier Scores for Continual Personalization of Text-to-Image Diffusion Models
Oct 02, 2024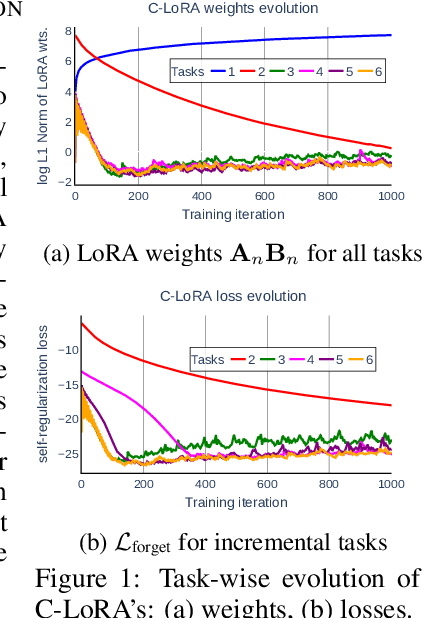
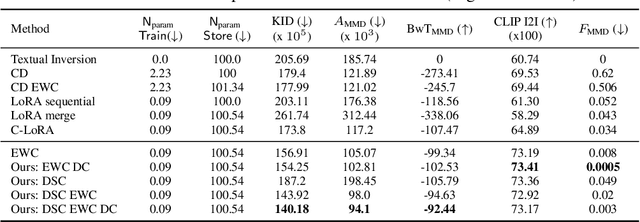
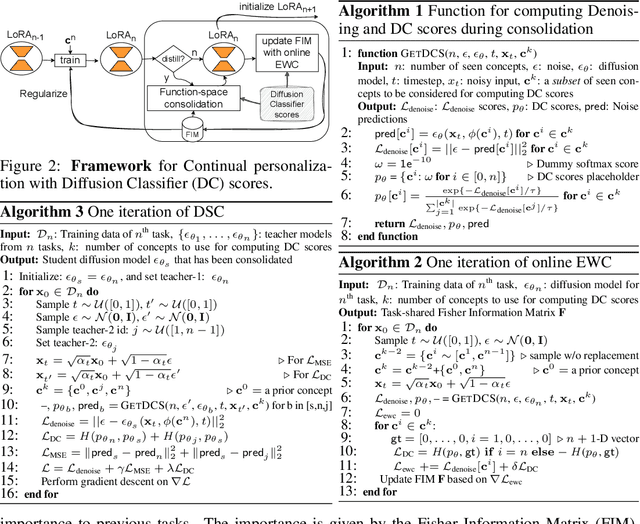
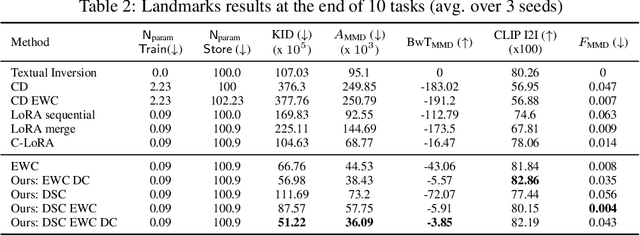
Personalized text-to-image diffusion models have grown popular for their ability to efficiently acquire a new concept from user-defined text descriptions and a few images. However, in the real world, a user may wish to personalize a model on multiple concepts but one at a time, with no access to the data from previous concepts due to storage/privacy concerns. When faced with this continual learning (CL) setup, most personalization methods fail to find a balance between acquiring new concepts and retaining previous ones -- a challenge that continual personalization (CP) aims to solve. Inspired by the successful CL methods that rely on class-specific information for regularization, we resort to the inherent class-conditioned density estimates, also known as diffusion classifier (DC) scores, for continual personalization of text-to-image diffusion models. Namely, we propose using DC scores for regularizing the parameter-space and function-space of text-to-image diffusion models, to achieve continual personalization. Using several diverse evaluation setups, datasets, and metrics, we show that our proposed regularization-based CP methods outperform the state-of-the-art C-LoRA, and other baselines. Finally, by operating in the replay-free CL setup and on low-rank adapters, our method incurs zero storage and parameter overhead, respectively, over the state-of-the-art.