 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Black-box and Gray-box Modeling of Nonlinear Audio Effects
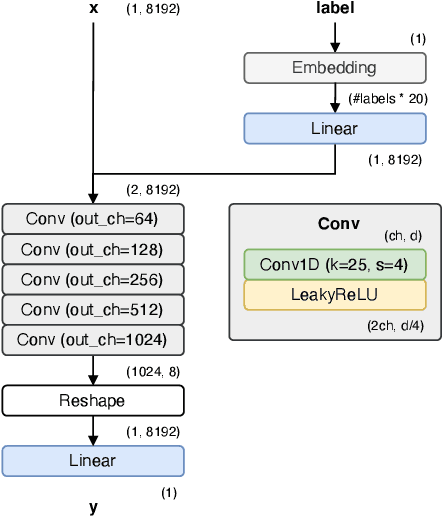
Feb 20, 2025Audio effects are extensively used at every stage of audio and music content creation. The majority of differentiable audio effects modeling approaches fall into the black-box or gray-box paradigms; and most models have been proposed and applied to nonlinear effects like guitar amplifiers, overdrive, distortion, fuzz and compressor. Although a plethora of architectures have been introduced for the task at hand there is still lack of understanding on the state of the art, since most publications experiment with one type of nonlinear audio effect and a very small number of devices. In this work we aim to shed light on the audio effects modeling landscape by comparing black-box and gray-box architectures on a large number of nonlinear audio effects, identifying the most suitable for a wide range of devices. In the process, we also: introduce time-varying gray-box models and propose models for compressor, distortion and fuzz, publish a large dataset for audio effects research - ToneTwist AFx https://github.com/mcomunita/tonetwist-afx-dataset - that is also the first open to community contributions, evaluate models on a variety of metrics and conduct extensive subjective evaluation. Code https://github.com/mcomunita/nablafx and supplementary material https://github.com/mcomunita/nnlinafx-supp-material are also available.
Stable-V2A: Synthesis of Synchronized Sound Effects with Temporal and Semantic Controls
Dec 19, 2024



Sound designers and Foley artists usually sonorize a scene, such as from a movie or video game, by manually annotating and sonorizing each action of interest in the video. In our case, the intent is to leave full creative control to sound designers with a tool that allows them to bypass the more repetitive parts of their work, thus being able to focus on the creative aspects of sound production. We achieve this presenting Stable-V2A, a two-stage model consisting of: an RMS-Mapper that estimates an envelope representative of the audio characteristics associated with the input video; and Stable-Foley, a diffusion model based on Stable Audio Open that generates audio semantically and temporally aligned with the target video. Temporal alignment is guaranteed by the use of the envelope as a ControlNet input, while semantic alignment is achieved through the use of sound representations chosen by the designer as cross-attention conditioning of the diffusion process. We train and test our model on Greatest Hits, a dataset commonly used to evaluate V2A models. In addition, to test our model on a case study of interest, we introduce Walking The Maps, a dataset of videos extracted from video games depicting animated characters walking in different locations. Samples and code available on our demo page at https://ispamm.github.io/Stable-V2A.
ST-ITO: Controlling Audio Effects for Style Transfer with Inference-Time Optimization
Oct 28, 2024Audio production style transfer is the task of processing an input to impart stylistic elements from a reference recording. Existing approaches often train a neural network to estimate control parameters for a set of audio effects. However, these approaches are limited in that they can only control a fixed set of effects, where the effects must be differentiable or otherwise employ specialized training techniques. In this work, we introduce ST-ITO, Style Transfer with Inference-Time Optimization, an approach that instead searches the parameter space of an audio effect chain at inference. This method enables control of arbitrary audio effect chains, including unseen and non-differentiable effects. Our approach employs a learned metric of audio production style, which we train through a simple and scalable self-supervised pretraining strategy, along with a gradient-free optimizer. Due to the limited existing evaluation methods for audio production style transfer, we introduce a multi-part benchmark to evaluate audio production style metrics and style transfer systems. This evaluation demonstrates that our audio representation better captures attributes related to audio production and enables expressive style transfer via control of arbitrary audio effects.
SpecMaskGIT: Masked Generative Modeling of Audio Spectrograms for Efficient Audio Synthesis and Beyond
Jun 26, 2024



Recent advances in generative models that iteratively synthesize audio clips sparked great success to text-to-audio synthesis (TTA), but with the cost of slow synthesis speed and heavy computation. Although there have been attempts to accelerate the iterative procedure, high-quality TTA systems remain inefficient due to hundreds of iterations required in the inference phase and large amount of model parameters. To address the challenges, we propose SpecMaskGIT, a light-weighted, efficient yet effective TTA model based on the masked generative modeling of spectrograms. First, SpecMaskGIT synthesizes a realistic 10s audio clip by less than 16 iterations, an order-of-magnitude less than previous iterative TTA methods. As a discrete model, SpecMaskGIT outperforms larger VQ-Diffusion and auto-regressive models in the TTA benchmark, while being real-time with only 4 CPU cores or even 30x faster with a GPU. Next, built upon a latent space of Mel-spectrogram, SpecMaskGIT has a wider range of applications (e.g., the zero-shot bandwidth extension) than similar methods built on the latent wave domain. Moreover, we interpret SpecMaskGIT as a generative extension to previous discriminative audio masked Transformers, and shed light on its audio representation learning potential. We hope our work inspires the exploration of masked audio modeling toward further diverse scenarios.
SyncFusion: Multimodal Onset-synchronized Video-to-Audio Foley Synthesis
Oct 23, 2023Sound design involves creatively selecting, recording, and editing sound effects for various media like cinema, video games, and virtual/augmented reality. One of the most time-consuming steps when designing sound is synchronizing audio with video. In some cases, environmental recordings from video shoots are available, which can aid in the process. However, in video games and animations, no reference audio exists, requiring manual annotation of event timings from the video. We propose a system to extract repetitive actions onsets from a video, which are then used - in conjunction with audio or textual embeddings - to condition a diffusion model trained to generate a new synchronized sound effects audio track. In this way, we leave complete creative control to the sound designer while removing the burden of synchronization with video. Furthermore, editing the onset track or changing the conditioning embedding requires much less effort than editing the audio track itself, simplifying the sonification process. We provide sound examples, source code, and pretrained models to faciliate reproducibility
Modulation Extraction for LFO-driven Audio Effects
May 22, 2023



Low frequency oscillator (LFO) driven audio effects such as phaser, flanger, and chorus, modify an input signal using time-varying filters and delays, resulting in characteristic sweeping or widening effects. It has been shown that these effects can be modeled using neural networks when conditioned with the ground truth LFO signal. However, in most cases, the LFO signal is not accessible and measurement from the audio signal is nontrivial, hindering the modeling process. To address this, we propose a framework capable of extracting arbitrary LFO signals from processed audio across multiple digital audio effects, parameter settings, and instrument configurations. Since our system imposes no restrictions on the LFO signal shape, we demonstrate its ability to extract quasiperiodic, combined, and distorted modulation signals that are relevant to effect modeling. Furthermore, we show how coupling the extraction model with a simple processing network enables training of end-to-end black-box models of unseen analog or digital LFO-driven audio effects using only dry and wet audio pairs, overcoming the need to access the audio effect or internal LFO signal. We make our code available and provide the trained audio effect models in a real-time VST plugin.
Modelling black-box audio effects with time-varying feature modulation
Nov 01, 2022



Deep learning approaches for black-box modelling of audio effects have shown promise, however, the majority of existing work focuses on nonlinear effects with behaviour on relatively short time-scales, such as guitar amplifiers and distortion. While recurrent and convolutional architectures can theoretically be extended to capture behaviour at longer time scales, we show that simply scaling the width, depth, or dilation factor of existing architectures does not result in satisfactory performance when modelling audio effects such as fuzz and dynamic range compression. To address this, we propose the integration of time-varying feature-wise linear modulation into existing temporal convolutional backbones, an approach that enables learnable adaptation of the intermediate activations. We demonstrate that our approach more accurately captures long-range dependencies for a range of fuzz and compressor implementations across both time and frequency domain metrics. We provide sound examples, source code, and pretrained models to faciliate reproducibility.
Neural Synthesis of Footsteps Sound Effects with Generative Adversarial Networks
Oct 18, 2021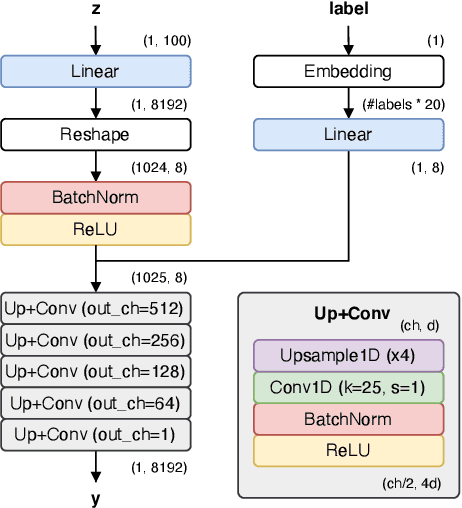

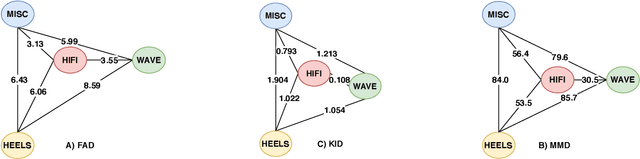
Footsteps are among the most ubiquitous sound effects in multimedia applications. There is substantial research into understanding the acoustic features and developing synthesis models for footstep sound effects. In this paper, we present a first attempt at adopting neural synthesis for this task. We implemented two GAN-based architectures and compared the results with real recordings as well as six traditional sound synthesis methods. Our architectures reached realism scores as high as recorded samples, showing encouraging results for the task at hand.
Guitar Effects Recognition and Parameter Estimation with Convolutional Neural Networks
Dec 06, 2020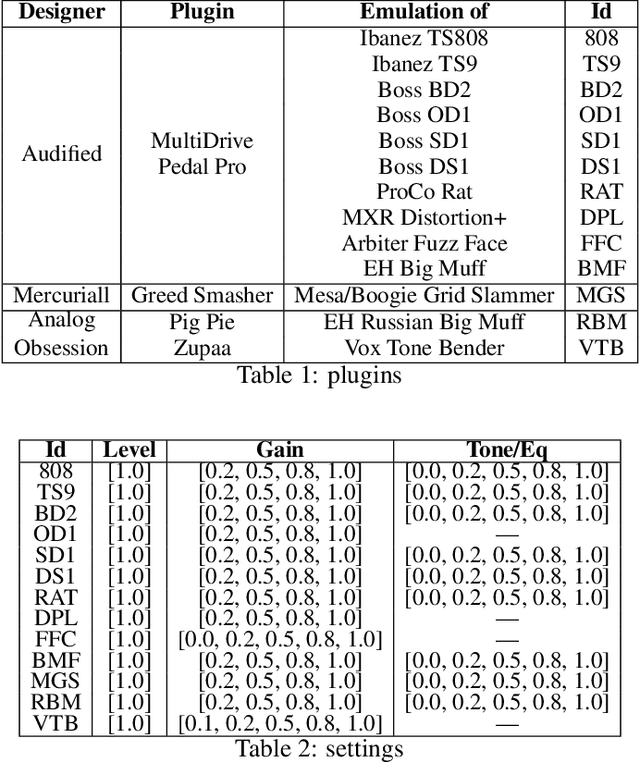
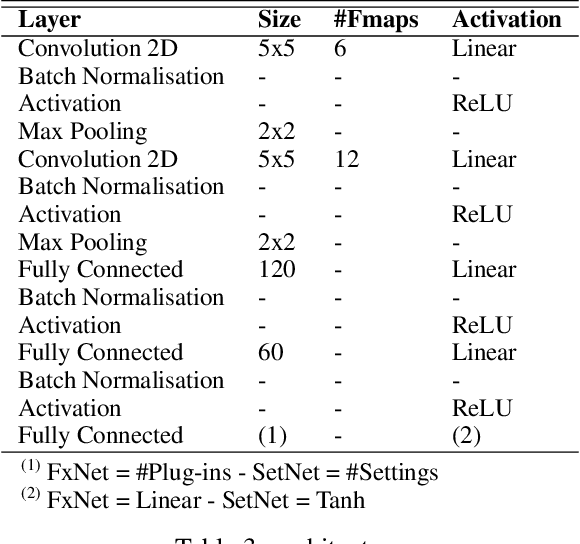
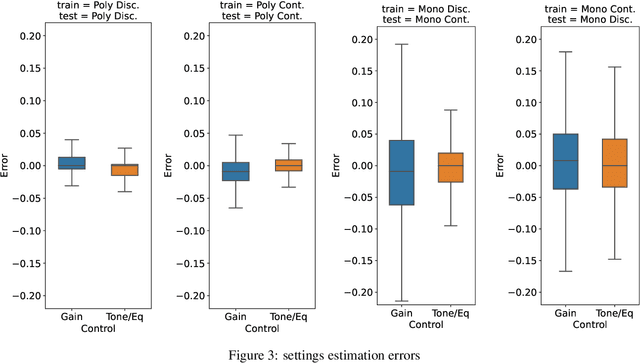

Despite the popularity of guitar effects, there is very little existing research on classification and parameter estimation of specific plugins or effect units from guitar recordings. In this paper, convolutional neural networks were used for classification and parameter estimation for 13 overdrive, distortion and fuzz guitar effects. A novel dataset of processed electric guitar samples was assembled, with four sub-datasets consisting of monophonic or polyphonic samples and discrete or continuous settings values, for a total of about 250 hours of processed samples. Results were compared for networks trained and tested on the same or on a different sub-dataset. We found that discrete datasets could lead to equally high performance as continuous ones, whilst being easier to design, analyse and modify. Classification accuracy was above 80\%, with confusion matrices reflecting similarities in the effects timbre and circuits design. With parameter values between 0.0 and 1.0, the mean absolute error is in most cases below 0.05, while the root mean square error is below 0.1 in all cases but one.