 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Neural Audio Fingerprinting using Music Foundation Models
Nov 07, 2025The proliferation of distorted, compressed, and manipulated music on modern media platforms like TikTok motivates the development of more robust audio fingerprinting techniques to identify the sources of musical recordings. In this paper, we develop and evaluate new neural audio fingerprinting techniques with the aim of improving their robustness. We make two contributions to neural fingerprinting methodology: (1) we use a pretrained music foundation model as the backbone of the neural architecture and (2) we expand the use of data augmentation to train fingerprinting models under a wide variety of audio manipulations, including time streching, pitch modulation, compression, and filtering. We systematically evaluate our methods in comparison to two state-of-the-art neural fingerprinting models: NAFP and GraFPrint. Results show that fingerprints extracted with music foundation models (e.g., MuQ, MERT) consistently outperform models trained from scratch or pretrained on non-musical audio. Segment-level evaluation further reveals their capability to accurately localize fingerprint matches, an important practical feature for catalog management.
LHGNN: Local-Higher Order Graph Neural Networks For Audio Classification and Tagging
Jan 07, 2025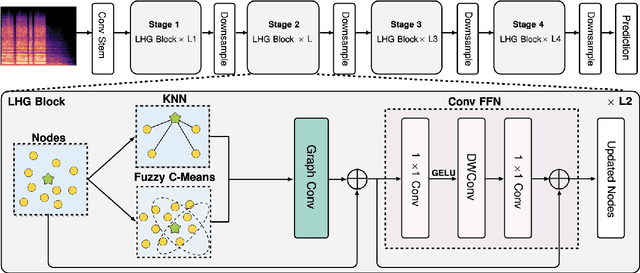



Transformers have set new benchmarks in audio processing tasks, leveraging self-attention mechanisms to capture complex patterns and dependencies within audio data. However, their focus on pairwise interactions limits their ability to process the higher-order relations essential for identifying distinct audio objects. To address this limitation, this work introduces the Local- Higher Order Graph Neural Network (LHGNN), a graph based model that enhances feature understanding by integrating local neighbourhood information with higher-order data from Fuzzy C-Means clusters, thereby capturing a broader spectrum of audio relationships. Evaluation of the model on three publicly available audio datasets shows that it outperforms Transformer-based models across all benchmarks while operating with substantially fewer parameters. Moreover, LHGNN demonstrates a distinct advantage in scenarios lacking ImageNet pretraining, establishing its effectiveness and efficiency in environments where extensive pretraining data is unavailable.
ST-ITO: Controlling Audio Effects for Style Transfer with Inference-Time Optimization
Oct 28, 2024Audio production style transfer is the task of processing an input to impart stylistic elements from a reference recording. Existing approaches often train a neural network to estimate control parameters for a set of audio effects. However, these approaches are limited in that they can only control a fixed set of effects, where the effects must be differentiable or otherwise employ specialized training techniques. In this work, we introduce ST-ITO, Style Transfer with Inference-Time Optimization, an approach that instead searches the parameter space of an audio effect chain at inference. This method enables control of arbitrary audio effect chains, including unseen and non-differentiable effects. Our approach employs a learned metric of audio production style, which we train through a simple and scalable self-supervised pretraining strategy, along with a gradient-free optimizer. Due to the limited existing evaluation methods for audio production style transfer, we introduce a multi-part benchmark to evaluate audio production style metrics and style transfer systems. This evaluation demonstrates that our audio representation better captures attributes related to audio production and enables expressive style transfer via control of arbitrary audio effects.
GraFPrint: A GNN-Based Approach for Audio Identification
Oct 14, 2024


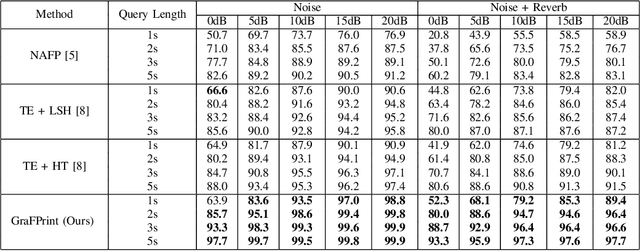
This paper introduces GraFPrint, an audio identification framework that leverages the structural learning capabilities of Graph Neural Networks (GNNs) to create robust audio fingerprints. Our method constructs a k-nearest neighbor (k-NN) graph from time-frequency representations and applies max-relative graph convolutions to encode local and global information. The network is trained using a self-supervised contrastive approach, which enhances resilience to ambient distortions by optimizing feature representation. GraFPrint demonstrates superior performance on large-scale datasets at various levels of granularity, proving to be both lightweight and scalable, making it suitable for real-world applications with extensive reference databases.
ATGNN: Audio Tagging Graph Neural Network
Nov 02, 2023



Deep learning models such as CNNs and Transformers have achieved impressive performance for end-to-end audio tagging. Recent works have shown that despite stacking multiple layers, the receptive field of CNNs remains severely limited. Transformers on the other hand are able to map global context through self-attention, but treat the spectrogram as a sequence of patches which is not flexible enough to capture irregular audio objects. In this work, we treat the spectrogram in a more flexible way by considering it as graph structure and process it with a novel graph neural architecture called ATGNN. ATGNN not only combines the capability of CNNs with the global information sharing ability of Graph Neural Networks, but also maps semantic relationships between learnable class embeddings and corresponding spectrogram regions. We evaluate ATGNN on two audio tagging tasks, where it achieves 0.585 mAP on the FSD50K dataset and 0.335 mAP on the AudioSet-balanced dataset, achieving comparable results to Transformer based models with significantly lower number of learnable parameters.
Few-shot bioacoustic event detection at the DCASE 2023 challenge
Jun 15, 2023



Few-shot bioacoustic event detection consists in detecting sound events of specified types, in varying soundscapes, while having access to only a few examples of the class of interest. This task ran as part of the DCASE challenge for the third time this year with an evaluation set expanded to include new animal species, and a new rule: ensemble models were no longer allowed. The 2023 few shot task received submissions from 6 different teams with F-scores reaching as high as 63% on the evaluation set. Here we describe the task, focusing on describing the elements that differed from previous years. We also take a look back at past editions to describe how the task has evolved. Not only have the F-score results steadily improved (40% to 60% to 63%), but the type of systems proposed have also become more complex. Sound event detection systems are no longer simple variations of the baselines provided: multiple few-shot learning methodologies are still strong contenders for the task.
Learning to detect an animal sound from five examples
May 22, 2023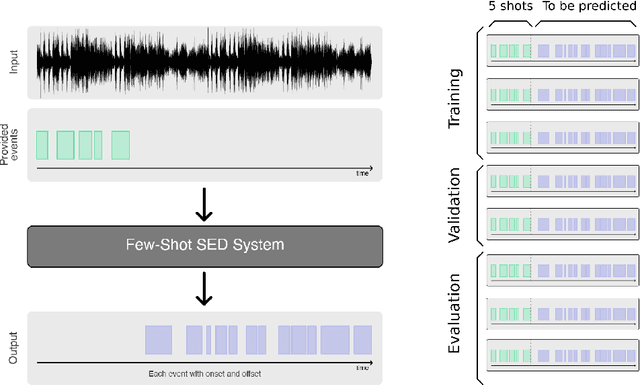
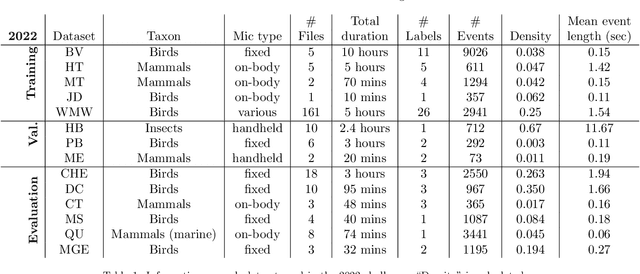
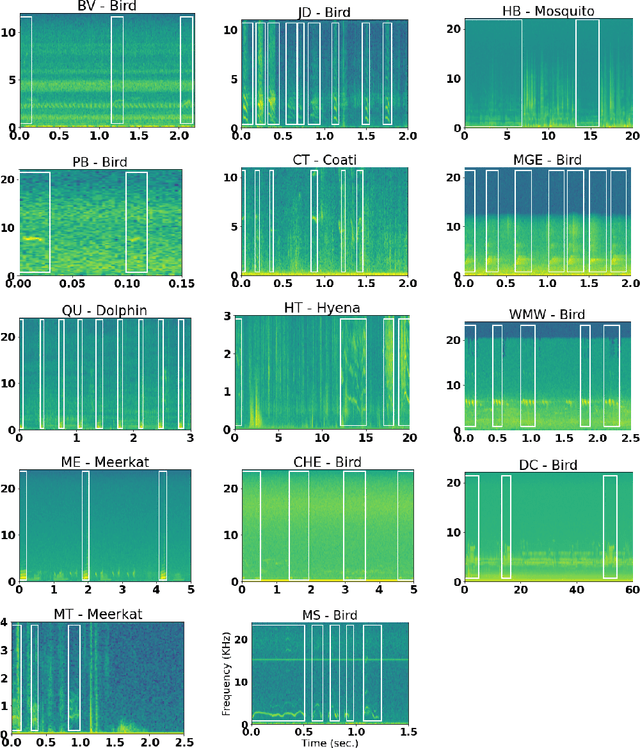
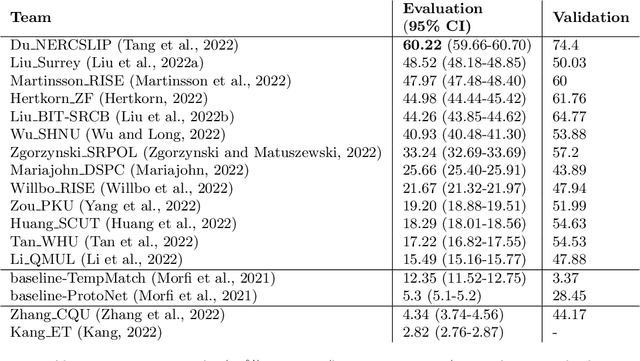
Automatic detection and classification of animal sounds has many applications in biodiversity monitoring and animal behaviour. In the past twenty years, the volume of digitised wildlife sound available has massively increased, and automatic classification through deep learning now shows strong results. However, bioacoustics is not a single task but a vast range of small-scale tasks (such as individual ID, call type, emotional indication) with wide variety in data characteristics, and most bioacoustic tasks do not come with strongly-labelled training data. The standard paradigm of supervised learning, focussed on a single large-scale dataset and/or a generic pre-trained algorithm, is insufficient. In this work we recast bioacoustic sound event detection within the AI framework of few-shot learning. We adapt this framework to sound event detection, such that a system can be given the annotated start/end times of as few as 5 events, and can then detect events in long-duration audio -- even when the sound category was not known at the time of algorithm training. We introduce a collection of open datasets designed to strongly test a system's ability to perform few-shot sound event detections, and we present the results of a public contest to address the task. We show that prototypical networks are a strong-performing method, when enhanced with adaptations for general characteristics of animal sounds. We demonstrate that widely-varying sound event durations are an important factor in performance, as well as non-stationarity, i.e. gradual changes in conditions throughout the duration of a recording. For fine-grained bioacoustic recognition tasks without massive annotated training data, our results demonstrate that few-shot sound event detection is a powerful new method, strongly outperforming traditional signal-processing detection methods in the fully automated scenario.