Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraFPrint: A GNN-Based Approach for Audio Identification
Paper and Code



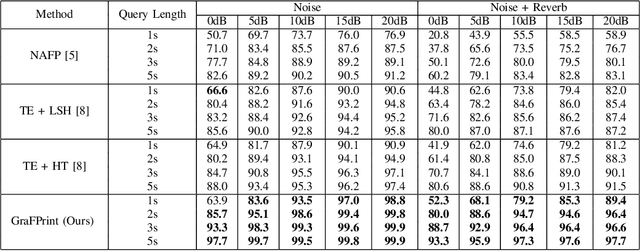
This paper introduces GraFPrint, an audio identification framework that leverages the structural learning capabilities of Graph Neural Networks (GNNs) to create robust audio fingerprints. Our method constructs a k-nearest neighbor (k-NN) graph from time-frequency representations and applies max-relative graph convolutions to encode local and global information. The network is trained using a self-supervised contrastive approach, which enhances resilience to ambient distortions by optimizing feature representation. GraFPrint demonstrates superior performance on large-scale datasets at various levels of granularity, proving to be both lightweight and scalable, making it suitable for real-world applications with extensive reference databases.
* Submitted to IEEE International Conference on Acoustics, Speech, and
Signal Processing (ICASSP 2025)
View paper on