 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining music sample identification with a self-supervised graph neural network
Jun 17, 2025Automatic sample identification (ASID), the detection and identification of portions of audio recordings that have been reused in new musical works, is an essential but challenging task in the field of audio query-based retrieval. While a related task, audio fingerprinting, has made significant progress in accurately retrieving musical content under "real world" (noisy, reverberant) conditions, ASID systems struggle to identify samples that have undergone musical modifications. Thus, a system robust to common music production transformations such as time-stretching, pitch-shifting, effects processing, and underlying or overlaying music is an important open challenge. In this work, we propose a lightweight and scalable encoding architecture employing a Graph Neural Network within a contrastive learning framework. Our model uses only 9% of the trainable parameters compared to the current state-of-the-art system while achieving comparable performance, reaching a mean average precision (mAP) of 44.2%. To enhance retrieval quality, we introduce a two-stage approach consisting of an initial coarse similarity search for candidate selection, followed by a cross-attention classifier that rejects irrelevant matches and refines the ranking of retrieved candidates - an essential capability absent in prior models. In addition, because queries in real-world applications are often short in duration, we benchmark our system for short queries using new fine-grained annotations for the Sample100 dataset, which we publish as part of this work.
GraFPrint: A GNN-Based Approach for Audio Identification
Oct 14, 2024


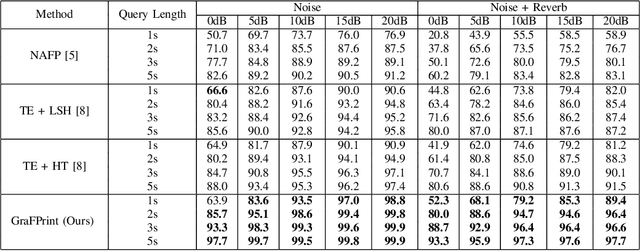
This paper introduces GraFPrint, an audio identification framework that leverages the structural learning capabilities of Graph Neural Networks (GNNs) to create robust audio fingerprints. Our method constructs a k-nearest neighbor (k-NN) graph from time-frequency representations and applies max-relative graph convolutions to encode local and global information. The network is trained using a self-supervised contrastive approach, which enhances resilience to ambient distortions by optimizing feature representation. GraFPrint demonstrates superior performance on large-scale datasets at various levels of granularity, proving to be both lightweight and scalable, making it suitable for real-world applications with extensive reference databases.