 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFour Decades of Digital Waveguides
Apr 14, 2026Digital waveguide physical modeling offers efficient simulation of acoustic wave propagation as compared to general finite-difference schemes commonly used in computational physics. This efficiency has enabled the real-time implementation of physically modeled musical instruments and sound effects, as well as real-time vocal models and artificial reverberation. This paper provides an overview of the historical evolution and applications of digital waveguide modeling and highlights recent advances in the field. Parametric optimization using classical, evolutionary and neural approaches are also discussed and compared. Digital waveguides provide physically accurate simulations with reduced computational cost, and can now be optimized with modern machine learning and differentiable digital signal processing techniques.
Learning Vocal-Tract Area and Radiation with a Physics-Informed Webster Model
Feb 14, 2026We present a physics-informed voiced backend renderer for singing-voice synthesis. Given synthetic single-channel audio and a fund-amental--frequency trajectory, we train a time-domain Webster model as a physics-informed neural network to estimate an interpretable vocal-tract area function and an open-end radiation coefficient. Training enforces partial differential equation and boundary consistency; a lightweight DDSP path is used only to stabilize learning, while inference is purely physics-based. On sustained vowels (/a/, /i/, /u/), parameters rendered by an independent finite-difference time-domain Webster solver reproduce spectral envelopes competitively with a compact DDSP baseline and remain stable under changes in discretization, moderate source variations, and about ten percent pitch shifts. The in-graph waveform remains breathier than the reference, motivating periodicity-aware objectives and explicit glottal priors in future work.
Bimodal Connection Attention Fusion for Speech Emotion Recognition
Mar 08, 2025Multi-modal emotion recognition is challenging due to the difficulty of extracting features that capture subtle emotional differences. Understanding multi-modal interactions and connections is key to building effective bimodal speech emotion recognition systems. In this work, we propose Bimodal Connection Attention Fusion (BCAF) method, which includes three main modules: the interactive connection network, the bimodal attention network, and the correlative attention network. The interactive connection network uses an encoder-decoder architecture to model modality connections between audio and text while leveraging modality-specific features. The bimodal attention network enhances semantic complementation and exploits intra- and inter-modal interactions. The correlative attention network reduces cross-modal noise and captures correlations between audio and text. Experiments on the MELD and IEMOCAP datasets demonstrate that the proposed BCAF method outperforms existing state-of-the-art baselines.
Differentiable Black-box and Gray-box Modeling of Nonlinear Audio Effects
Feb 20, 2025Audio effects are extensively used at every stage of audio and music content creation. The majority of differentiable audio effects modeling approaches fall into the black-box or gray-box paradigms; and most models have been proposed and applied to nonlinear effects like guitar amplifiers, overdrive, distortion, fuzz and compressor. Although a plethora of architectures have been introduced for the task at hand there is still lack of understanding on the state of the art, since most publications experiment with one type of nonlinear audio effect and a very small number of devices. In this work we aim to shed light on the audio effects modeling landscape by comparing black-box and gray-box architectures on a large number of nonlinear audio effects, identifying the most suitable for a wide range of devices. In the process, we also: introduce time-varying gray-box models and propose models for compressor, distortion and fuzz, publish a large dataset for audio effects research - ToneTwist AFx https://github.com/mcomunita/tonetwist-afx-dataset - that is also the first open to community contributions, evaluate models on a variety of metrics and conduct extensive subjective evaluation. Code https://github.com/mcomunita/nablafx and supplementary material https://github.com/mcomunita/nnlinafx-supp-material are also available.
Stable-V2A: Synthesis of Synchronized Sound Effects with Temporal and Semantic Controls
Dec 19, 2024



Sound designers and Foley artists usually sonorize a scene, such as from a movie or video game, by manually annotating and sonorizing each action of interest in the video. In our case, the intent is to leave full creative control to sound designers with a tool that allows them to bypass the more repetitive parts of their work, thus being able to focus on the creative aspects of sound production. We achieve this presenting Stable-V2A, a two-stage model consisting of: an RMS-Mapper that estimates an envelope representative of the audio characteristics associated with the input video; and Stable-Foley, a diffusion model based on Stable Audio Open that generates audio semantically and temporally aligned with the target video. Temporal alignment is guaranteed by the use of the envelope as a ControlNet input, while semantic alignment is achieved through the use of sound representations chosen by the designer as cross-attention conditioning of the diffusion process. We train and test our model on Greatest Hits, a dataset commonly used to evaluate V2A models. In addition, to test our model on a case study of interest, we introduce Walking The Maps, a dataset of videos extracted from video games depicting animated characters walking in different locations. Samples and code available on our demo page at https://ispamm.github.io/Stable-V2A.
Exploring trends in audio mixes and masters: Insights from a dataset analysis
Dec 04, 2024



We present an analysis of a dataset of audio metrics and aesthetic considerations about mixes and masters provided by the web platform MixCheck studio. The platform is designed for educational purposes, primarily targeting amateur music producers, and aimed at analysing their recordings prior to them being released. The analysis focuses on the following data points: integrated loudness, mono compatibility, presence of clipping and phase issues, compression and tonal profile across 30 user-specified genres. Both mixed (mixes) and mastered audio (masters) are included in the analysis, where mixes refer to the initial combination and balance of individual tracks, and masters refer to the final refined version optimized for distribution. Results show that loudness-related issues along with dynamics issues are the most prevalent, particularly in mastered audio. However mastered audio presents better results in compression than just mixed audio. Additionally, results show that mastered audio has a lower percentage of stereo field and phase issues.
ST-ITO: Controlling Audio Effects for Style Transfer with Inference-Time Optimization
Oct 28, 2024Audio production style transfer is the task of processing an input to impart stylistic elements from a reference recording. Existing approaches often train a neural network to estimate control parameters for a set of audio effects. However, these approaches are limited in that they can only control a fixed set of effects, where the effects must be differentiable or otherwise employ specialized training techniques. In this work, we introduce ST-ITO, Style Transfer with Inference-Time Optimization, an approach that instead searches the parameter space of an audio effect chain at inference. This method enables control of arbitrary audio effect chains, including unseen and non-differentiable effects. Our approach employs a learned metric of audio production style, which we train through a simple and scalable self-supervised pretraining strategy, along with a gradient-free optimizer. Due to the limited existing evaluation methods for audio production style transfer, we introduce a multi-part benchmark to evaluate audio production style metrics and style transfer systems. This evaluation demonstrates that our audio representation better captures attributes related to audio production and enables expressive style transfer via control of arbitrary audio effects.
An automatic mixing speech enhancement system for multi-track audio
Apr 27, 2024We propose a speech enhancement system for multitrack audio. The system will minimize auditory masking while allowing one to hear multiple simultaneous speakers. The system can be used in multiple communication scenarios e.g., teleconferencing, invoice gaming, and live streaming. The ITU-R BS.1387 Perceptual Evaluation of Audio Quality (PEAQ) model is used to evaluate the amount of masking in the audio signals. Different audio effects e.g., level balance, equalization, dynamic range compression, and spatialization are applied via an iterative Harmony searching algorithm that aims to minimize the masking. In the subjective listening test, the designed system can compete with mixes by professional sound engineers and outperforms mixes by existing auto-mixing systems.
Differentiable All-pole Filters for Time-varying Audio Systems
Apr 12, 2024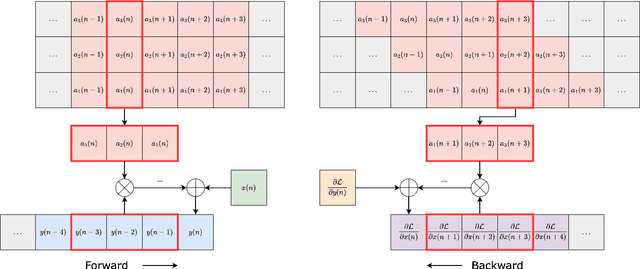

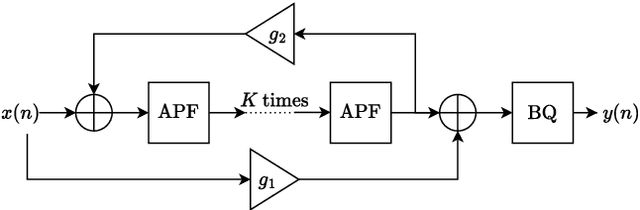

Infinite impulse response filters are an essential building block of many time-varying audio systems, such as audio effects and synthesisers. However, their recursive structure impedes end-to-end training of these systems using automatic differentiation. Although non-recursive filter approximations like frequency sampling and frame-based processing have been proposed and widely used in previous works, they cannot accurately reflect the gradient of the original system. We alleviate this difficulty by re-expressing a time-varying all-pole filter to backpropagate the gradients through itself, so the filter implementation is not bound to the technical limitations of automatic differentiation frameworks. This implementation can be employed within any audio system containing filters with poles for efficient gradient evaluation. We demonstrate its training efficiency and expressive capabilities for modelling real-world dynamic audio systems on a phaser, time-varying subtractive synthesiser, and feed-forward compressor. We make our code available and provide the trained audio effect and synth models in a VST plugin at https://christhetree.github.io/all_pole_filters/.
SyncFusion: Multimodal Onset-synchronized Video-to-Audio Foley Synthesis
Oct 23, 2023Sound design involves creatively selecting, recording, and editing sound effects for various media like cinema, video games, and virtual/augmented reality. One of the most time-consuming steps when designing sound is synchronizing audio with video. In some cases, environmental recordings from video shoots are available, which can aid in the process. However, in video games and animations, no reference audio exists, requiring manual annotation of event timings from the video. We propose a system to extract repetitive actions onsets from a video, which are then used - in conjunction with audio or textual embeddings - to condition a diffusion model trained to generate a new synchronized sound effects audio track. In this way, we leave complete creative control to the sound designer while removing the burden of synchronization with video. Furthermore, editing the onset track or changing the conditioning embedding requires much less effort than editing the audio track itself, simplifying the sonification process. We provide sound examples, source code, and pretrained models to faciliate reproducibility