 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 The First Challenge on Weather Removal in Videos
Apr 14, 2026This paper presents a review of the LoViF 2026 Challenge on Weather Removal in Videos. The challenge encourages the development of methods for restoring clean videos from inputs degraded by adverse weather conditions such as rain and snow, with an emphasis on achieving visually plausible and temporally consistent results while preserving scene structure and motion dynamics. To support this task, we introduce a new short-form WRV dataset tailored for video weather removal. It consists of 18 videos 1,216 synthesized frames paired with 1,216 real-world ground-truth frames at a resolution of 832 x 480, and is split into training, validation, and test sets with a ratio of 1:1:1. The goal of this challenge is to advance robust and realistic video restoration under real-world weather conditions, with evaluation protocols that jointly consider fidelity and perceptual quality. The challenge attracted 37 participants and received 5 valid final submissions with corresponding fact sheets, contributing to progress in weather removal for videos. The project is publicly available at https://www.codabench.org/competitions/13462/.
Can We Predict the Next Question? A Collaborative Filtering Approach to Modeling User Behavior
Nov 17, 2025



In recent years, large language models (LLMs) have excelled in language understanding and generation, powering advanced dialogue and recommendation systems. However, a significant limitation persists: these systems often model user preferences statically, failing to capture the dynamic and sequential nature of interactive behaviors. The sequence of a user's historical questions provides a rich, implicit signal of evolving interests and cognitive patterns, yet leveraging this temporal data for predictive tasks remains challenging due to the inherent disconnect between language modeling and behavioral sequence modeling. To bridge this gap, we propose a Collaborative Filtering-enhanced Question Prediction (CFQP) framework. CFQP dynamically models evolving user-question interactions by integrating personalized memory modules with graph-based preference propagation. This dual mechanism allows the system to adaptively learn from user-specific histories while refining predictions through collaborative signals from similar users. Experimental results demonstrate that our approach effectively generates agents that mimic real-user questioning patterns, highlighting its potential for building proactive and adaptive dialogue systems.
Non-Contact Health Monitoring During Daily Personal Care Routines
Jun 11, 2025Remote photoplethysmography (rPPG) enables non-contact, continuous monitoring of physiological signals and offers a practical alternative to traditional health sensing methods. Although rPPG is promising for daily health monitoring, its application in long-term personal care scenarios, such as mirror-facing routines in high-altitude environments, remains challenging due to ambient lighting variations, frequent occlusions from hand movements, and dynamic facial postures. To address these challenges, we present LADH (Long-term Altitude Daily Health), the first long-term rPPG dataset containing 240 synchronized RGB and infrared (IR) facial videos from 21 participants across five common personal care scenarios, along with ground-truth PPG, respiration, and blood oxygen signals. Our experiments demonstrate that combining RGB and IR video inputs improves the accuracy and robustness of non-contact physiological monitoring, achieving a mean absolute error (MAE) of 4.99 BPM in heart rate estimation. Furthermore, we find that multi-task learning enhances performance across multiple physiological indicators simultaneously. Dataset and code are open at https://github.com/McJackTang/FusionVitals.
RIVAL: Reinforcement Learning with Iterative and Adversarial Optimization for Machine Translation
Jun 05, 2025Large language models (LLMs) possess strong multilingual capabilities, and combining Reinforcement Learning from Human Feedback (RLHF) with translation tasks has shown great potential. However, we observe that this paradigm performs unexpectedly poorly when applied to colloquial subtitle translation tasks. In this work, we investigate this issue and find that the offline reward model (RM) gradually diverges from the online LLM due to distributional shift, ultimately leading to undesirable training outcomes. To address this, we propose RIVAL, an adversarial training framework that formulates the process as a min-max game between the RM and the LLM. RIVAL iteratively updates the both models, with the RM trained to distinguish strong from weak translations (qualitative preference reward), and the LLM trained to enhance its translation for closing this gap. To stabilize training and improve generalizability, we also incorporate quantitative preference reward (e.g., BLEU) into the RM, enabling reference-free quality modeling aligned with human evaluation. Through extensive experiments, we demonstrate that the proposed adversarial training framework significantly improves upon translation baselines.
Federated Latent Factor Learning for Recovering Wireless Sensor Networks Signal with Privacy-Preserving
Apr 22, 2025Wireless Sensor Networks (WSNs) are a cutting-edge domain in the field of intelligent sensing. Due to sensor failures and energy-saving strategies, the collected data often have massive missing data, hindering subsequent analysis and decision-making. Although Latent Factor Learning (LFL) has been proven effective in recovering missing data, it fails to sufficiently consider data privacy protection. To address this issue, this paper innovatively proposes a federated latent factor learning (FLFL) based spatial signal recovery (SSR) model, named FLFL-SSR. Its main idea is two-fold: 1) it designs a sensor-level federated learning framework, where each sensor uploads only gradient updates instead of raw data to optimize the global model, and 2) it proposes a local spatial sharing strategy, allowing sensors within the same spatial region to share their latent feature vectors, capturing spatial correlations and enhancing recovery accuracy. Experimental results on two real-world WSNs datasets demonstrate that the proposed model outperforms existing federated methods in terms of recovery performance.
Visual-based spatial audio generation system for multi-speaker environments
Feb 13, 2025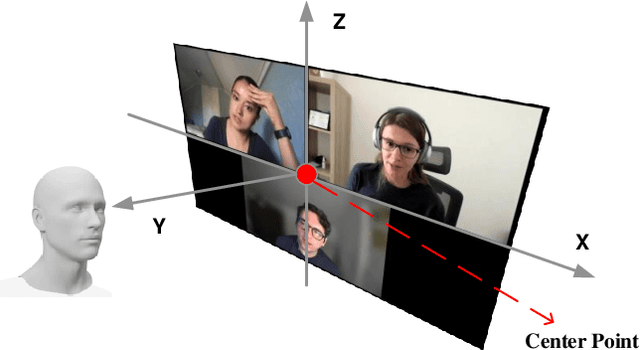



In multimedia applications such as films and video games, spatial audio techniques are widely employed to enhance user experiences by simulating 3D sound: transforming mono audio into binaural formats. However, this process is often complex and labor-intensive for sound designers, requiring precise synchronization of audio with the spatial positions of visual components. To address these challenges, we propose a visual-based spatial audio generation system - an automated system that integrates face detection YOLOv8 for object detection, monocular depth estimation, and spatial audio techniques. Notably, the system operates without requiring additional binaural dataset training. The proposed system is evaluated against existing Spatial Audio generation system using objective metrics. Experimental results demonstrate that our method significantly improves spatial consistency between audio and video, enhances speech quality, and performs robustly in multi-speaker scenarios. By streamlining the audio-visual alignment process, the proposed system enables sound engineers to achieve high-quality results efficiently, making it a valuable tool for professionals in multimedia production.
Differential Evolution Integrated Hybrid Deep Learning Model for Object Detection in Pre-made Dishes
Dec 29, 2024With the continuous improvement of people's living standards and fast-paced working conditions, pre-made dishes are becoming increasingly popular among families and restaurants due to their advantages of time-saving, convenience, variety, cost-effectiveness, standard quality, etc. Object detection is a key technology for selecting ingredients and evaluating the quality of dishes in the pre-made dishes industry. To date, many object detection approaches have been proposed. However, accurate object detection of pre-made dishes is extremely difficult because of overlapping occlusion of ingredients, similarity of ingredients, and insufficient light in the processing environment. As a result, the recognition scene is relatively complex and thus leads to poor object detection by a single model. To address this issue, this paper proposes a Differential Evolution Integrated Hybrid Deep Learning (DEIHDL) model. The main idea of DEIHDL is three-fold: 1) three YOLO-based and transformer-based base models are developed respectively to increase diversity for detecting objects of pre-made dishes, 2) the three base models are integrated by differential evolution optimized self-adjusting weights, and 3) weighted boxes fusion strategy is employed to score the confidence of the three base models during the integration. As such, DEIHDL possesses the multi-performance originating from the three base models to achieve accurate object detection in complex pre-made dish scenes. Extensive experiments on real datasets demonstrate that the proposed DEIHDL model significantly outperforms the base models in detecting objects of pre-made dishes.
Pay Attention to Attention for Sequential Recommendation
Oct 28, 2024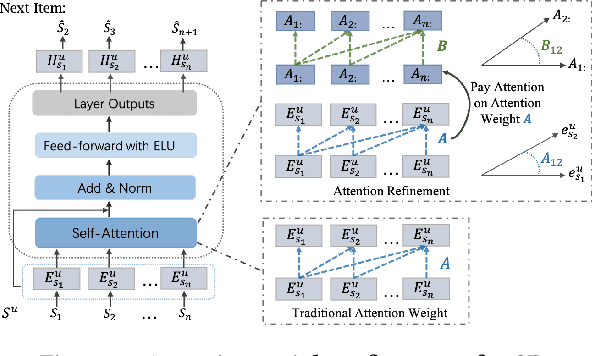
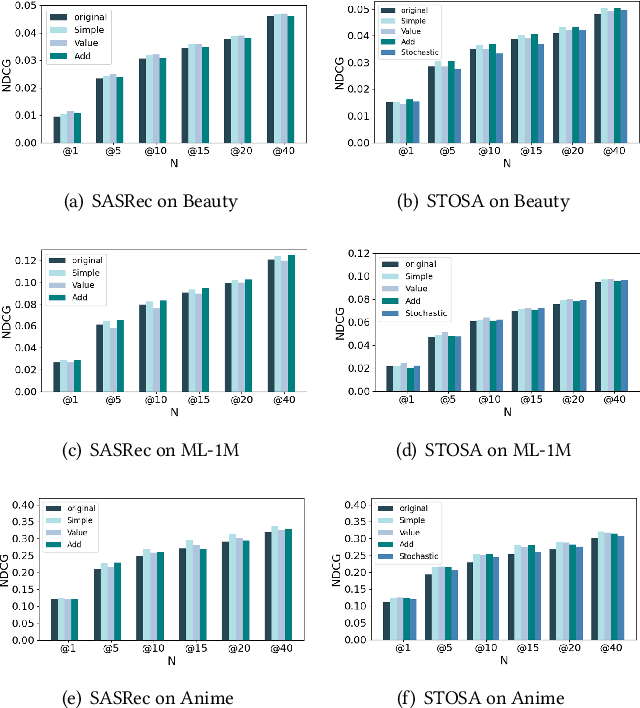
Transformer-based approaches have demonstrated remarkable success in various sequence-based tasks. However, traditional self-attention models may not sufficiently capture the intricate dependencies within items in sequential recommendation scenarios. This is due to the lack of explicit emphasis on attention weights, which play a critical role in allocating attention and understanding item-to-item correlations. To better exploit the potential of attention weights and improve the capability of sequential recommendation in learning high-order dependencies, we propose a novel sequential recommendation (SR) approach called attention weight refinement (AWRSR). AWRSR enhances the effectiveness of self-attention by additionally paying attention to attention weights, allowing for more refined attention distributions of correlations among items. We conduct comprehensive experiments on multiple real-world datasets, demonstrating that our approach consistently outperforms state-of-the-art SR models. Moreover, we provide a thorough analysis of AWRSR's effectiveness in capturing higher-level dependencies. These findings suggest that AWRSR offers a promising new direction for enhancing the performance of self-attention architecture in SR tasks, with potential applications in other sequence-based problems as well.
Summit Vitals: Multi-Camera and Multi-Signal Biosensing at High Altitudes
Sep 28, 2024Video photoplethysmography (vPPG) is an emerging method for non-invasive and convenient measurement of physiological signals, utilizing two primary approaches: remote video PPG (rPPG) and contact video PPG (cPPG). Monitoring vitals in high-altitude environments, where heart rates tend to increase and blood oxygen levels often decrease, presents significant challenges. To address these issues, we introduce the SUMS dataset comprising 80 synchronized non-contact facial and contact finger videos from 10 subjects during exercise and oxygen recovery scenarios, capturing PPG, respiration rate (RR), and SpO2. This dataset is designed to validate video vitals estimation algorithms and compare facial rPPG with finger cPPG. Additionally, fusing videos from different positions (i.e., face and finger) reduces the mean absolute error (MAE) of SpO2 predictions by 7.6\% and 10.6\% compared to only face and only finger, respectively. In cross-subject evaluation, we achieve an MAE of less than 0.5 BPM for HR estimation and 2.5\% for SpO2 estimation, demonstrating the precision of our multi-camera fusion techniques. Our findings suggest that simultaneous training on multiple indicators, such as PPG and blood oxygen, can reduce MAE in SpO2 estimation by 17.8\%.
An automatic mixing speech enhancement system for multi-track audio
Apr 27, 2024We propose a speech enhancement system for multitrack audio. The system will minimize auditory masking while allowing one to hear multiple simultaneous speakers. The system can be used in multiple communication scenarios e.g., teleconferencing, invoice gaming, and live streaming. The ITU-R BS.1387 Perceptual Evaluation of Audio Quality (PEAQ) model is used to evaluate the amount of masking in the audio signals. Different audio effects e.g., level balance, equalization, dynamic range compression, and spatialization are applied via an iterative Harmony searching algorithm that aims to minimize the masking. In the subjective listening test, the designed system can compete with mixes by professional sound engineers and outperforms mixes by existing auto-mixing systems.