 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay Attention to Attention for Sequential Recommendation
Paper and Code
Oct 28, 2024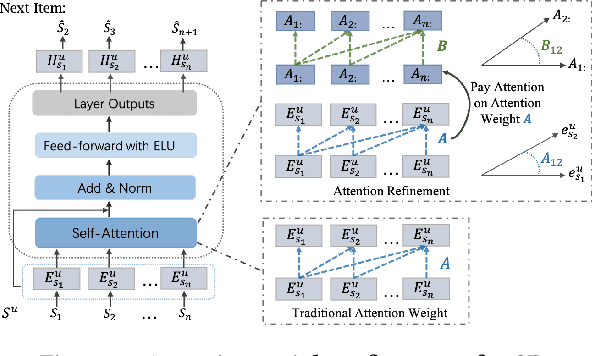
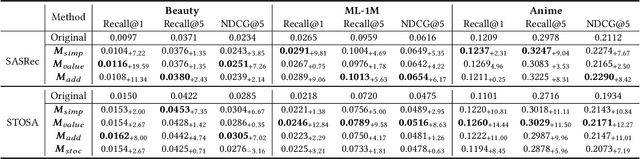
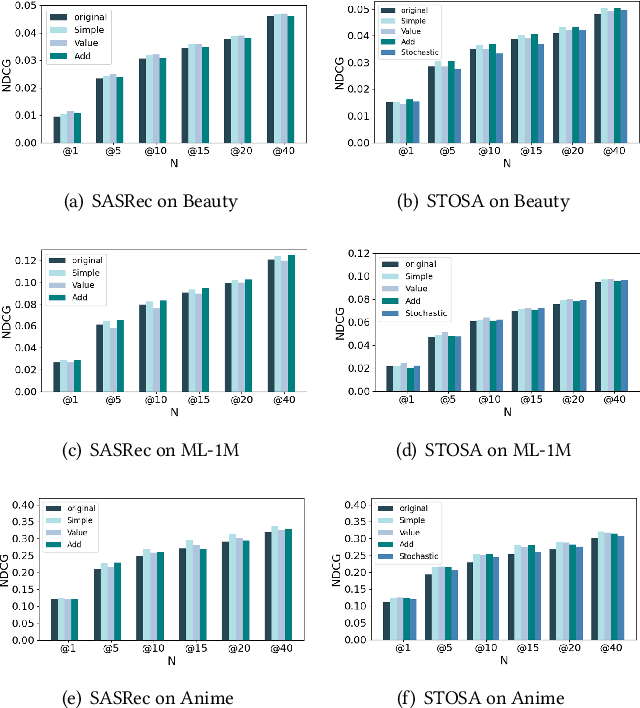
Transformer-based approaches have demonstrated remarkable success in various sequence-based tasks. However, traditional self-attention models may not sufficiently capture the intricate dependencies within items in sequential recommendation scenarios. This is due to the lack of explicit emphasis on attention weights, which play a critical role in allocating attention and understanding item-to-item correlations. To better exploit the potential of attention weights and improve the capability of sequential recommendation in learning high-order dependencies, we propose a novel sequential recommendation (SR) approach called attention weight refinement (AWRSR). AWRSR enhances the effectiveness of self-attention by additionally paying attention to attention weights, allowing for more refined attention distributions of correlations among items. We conduct comprehensive experiments on multiple real-world datasets, demonstrating that our approach consistently outperforms state-of-the-art SR models. Moreover, we provide a thorough analysis of AWRSR's effectiveness in capturing higher-level dependencies. These findings suggest that AWRSR offers a promising new direction for enhancing the performance of self-attention architecture in SR tasks, with potential applications in other sequence-based problems as well.