 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity-Aware Assessment of Social Textual Engagement and Resonance: A Human-Centric Perspective on User-Generated Content Evaluation
Jun 01, 2026Traditional Video Quality Assessment (VQA) focuses narrowly on aesthetic fidelity, overlooking the complex social dynamics that define quality in User-Generated Content (UGC). In this work, we propose a paradigm shift from signal-centric metrics to human-centric resonance assessment. We introduce CASTER (Community-Aware Assessment of Social Textual Engagement and Resonance), a new task that evaluates whether a UGC item achieves positive community resonance based on its multimodal attributes rather than visual quality alone. To address this, we present MEDEA (Multimodal Engagement-Driven Evaluation Architecture), which introduces a novel Social Chain-of-Thought (Social-CoT) mechanism. Unlike traditional logical CoT, Social-CoT performs multimodal perspective-taking, instantiating diverse viewer personas to simulate collective cognitive and emotional reactions (i.e., the "community mind") before deriving a quality judgment. MEDEA is trained via a two-stage approach involving supervised fine-tuning and process-supervised reinforcement learning with Social Alignment Reward to ensure reasoning paths are grounded in authentic human social cognition. To support this task, we release CASTER-Bench, a comprehensive human-annotated benchmark covering diverse UGC categories. Experiments demonstrate that MEDEA significantly outperforms state-of-the-art baselines on CASTER-Bench while providing interpretable and empathetic reasoning paths that align with real community feedback.
Uni-ViGU: Towards Unified Video Generation and Understanding via A Diffusion-Based Video Generator
Apr 09, 2026Unified multimodal models integrating visual understanding and generation face a fundamental challenge: visual generation incurs substantially higher computational costs than understanding, particularly for video. This imbalance motivates us to invert the conventional paradigm: rather than extending understanding-centric MLLMs to support generation, we propose Uni-ViGU, a framework that unifies video generation and understanding by extending a video generator as the foundation. We introduce a unified flow method that performs continuous flow matching for video and discrete flow matching for text within a single process, enabling coherent multimodal generation. We further propose a modality-driven MoE-based framework that augments Transformer blocks with lightweight layers for text generation while preserving generative priors. To repurpose generation knowledge for understanding, we design a bidirectional training mechanism with two stages: Knowledge Recall reconstructs input prompts to leverage learned text-video correspondences, while Capability Refinement fine-tunes on detailed captions to establish discriminative shared representations. Experiments demonstrate that Uni-ViGU achieves competitive performance on both video generation and understanding, validating generation-centric architectures as a scalable path toward unified multimodal intelligence. Project Page and Code: https://fr0zencrane.github.io/uni-vigu-page/.
Fine-Grained Activation Steering: Steering Less, Achieving More
Feb 04, 2026Activation steering has emerged as a cost-effective paradigm for modifying large language model (LLM) behaviors. Existing methods typically intervene at the block level, steering the bundled activations of selected attention heads, feedforward networks, or residual streams. However, we reveal that block-level activations are inherently heterogeneous, entangling beneficial, irrelevant, and harmful features, thereby rendering block-level steering coarse, inefficient, and intrusive. To investigate the root cause, we decompose block activations into fine-grained atomic unit (AU)-level activations, where each AU-level activation corresponds to a single dimension of the block activation, and each AU denotes a slice of the block weight matrix. Steering an AU-level activation is thus equivalent to steering its associated AU. Our theoretical and empirical analysis show that heterogeneity arises because different AUs or dimensions control distinct token distributions in LLM outputs. Hence, block-level steering inevitably moves helpful and harmful token directions together, which reduces efficiency. Restricting intervention to beneficial AUs yields more precise and effective steering. Building on this insight, we propose AUSteer, a simple and efficient method that operates at a finer granularity of the AU level. AUSteer first identifies discriminative AUs globally by computing activation momenta on contrastive samples. It then assigns adaptive steering strengths tailored to diverse inputs and selected AU activations. Comprehensive experiments on multiple LLMs and tasks show that AUSteer consistently surpasses advanced baselines while steering considerably fewer activations, demonstrating that steering less achieves more.
HOMURA: Taming the Sand-Glass for Time-Constrained LLM Translation via Reinforcement Learning
Jan 15, 2026Large Language Models (LLMs) have achieved remarkable strides in multilingual translation but are hindered by a systemic cross-lingual verbosity bias, rendering them unsuitable for strict time-constrained tasks like subtitling and dubbing. Current prompt-engineering approaches struggle to resolve this conflict between semantic fidelity and rigid temporal feasibility. To bridge this gap, we first introduce Sand-Glass, a benchmark specifically designed to evaluate translation under syllable-level duration constraints. Furthermore, we propose HOMURA, a reinforcement learning framework that explicitly optimizes the trade-off between semantic preservation and temporal compliance. By employing a KL-regularized objective with a novel dynamic syllable-ratio reward, HOMURA effectively "tames" the output length. Experimental results demonstrate that our method significantly outperforms strong LLM baselines, achieving precise length control that respects linguistic density hierarchies without compromising semantic adequacy.
Multiscale replay: A robust algorithm for stochastic variational inequalities with a Markovian buffer
Jan 04, 2026We introduce the Multiscale Experience Replay (MER) algorithm for solving a class of stochastic variational inequalities (VIs) in settings where samples are generated from a Markov chain and we have access to a memory buffer to store them. Rather than uniformly sampling from the buffer, MER utilizes a multi-scale sampling scheme to emulate the behavior of VI algorithms designed for independent and identically distributed samples, overcoming bias in the de facto serial scheme and thereby accelerating convergence. Notably, unlike standard sample-skipping variants of serial algorithms, MER is robust in that it achieves this acceleration in iteration complexity whenever possible, and without requiring knowledge of the mixing time of the Markov chain. We also discuss applications of MER, particularly in policy evaluation with temporal difference learning and in training generalized linear models with dependent data.
Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision
Aug 07, 2025
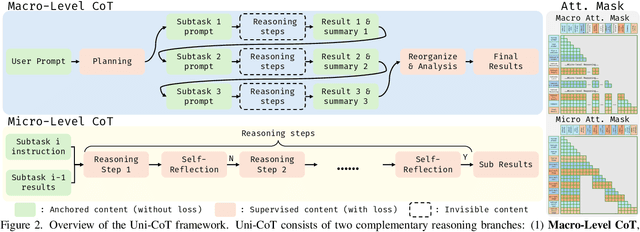

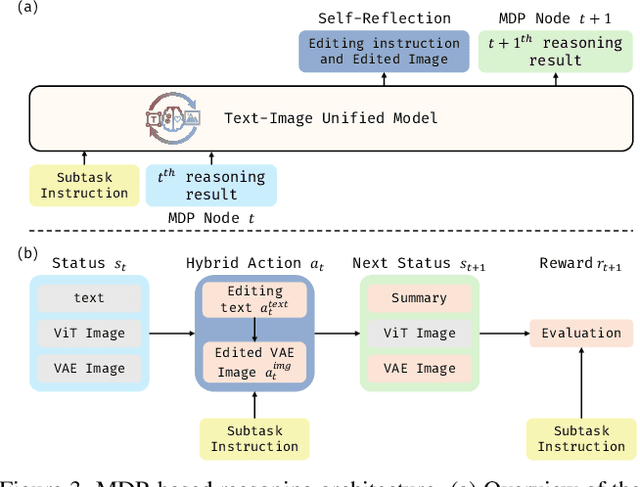
Chain-of-Thought (CoT) reasoning has been widely adopted to enhance Large Language Models (LLMs) by decomposing complex tasks into simpler, sequential subtasks. However, extending CoT to vision-language reasoning tasks remains challenging, as it often requires interpreting transitions of visual states to support reasoning. Existing methods often struggle with this due to limited capacity of modeling visual state transitions or incoherent visual trajectories caused by fragmented architectures. To overcome these limitations, we propose Uni-CoT, a Unified Chain-of-Thought framework that enables coherent and grounded multimodal reasoning within a single unified model. The key idea is to leverage a model capable of both image understanding and generation to reason over visual content and model evolving visual states. However, empowering a unified model to achieve that is non-trivial, given the high computational cost and the burden of training. To address this, Uni-CoT introduces a novel two-level reasoning paradigm: A Macro-Level CoT for high-level task planning and A Micro-Level CoT for subtask execution. This design significantly reduces the computational overhead. Furthermore, we introduce a structured training paradigm that combines interleaved image-text supervision for macro-level CoT with multi-task objectives for micro-level CoT. Together, these innovations allow Uni-CoT to perform scalable and coherent multi-modal reasoning. Furthermore, thanks to our design, all experiments can be efficiently completed using only 8 A100 GPUs with 80GB VRAM each. Experimental results on reasoning-driven image generation benchmark (WISE) and editing benchmarks (RISE and KRIS) indicates that Uni-CoT demonstrates SOTA performance and strong generalization, establishing Uni-CoT as a promising solution for multi-modal reasoning. Project Page and Code: https://sais-fuxi.github.io/projects/uni-cot/
RIVAL: Reinforcement Learning with Iterative and Adversarial Optimization for Machine Translation
Jun 05, 2025Large language models (LLMs) possess strong multilingual capabilities, and combining Reinforcement Learning from Human Feedback (RLHF) with translation tasks has shown great potential. However, we observe that this paradigm performs unexpectedly poorly when applied to colloquial subtitle translation tasks. In this work, we investigate this issue and find that the offline reward model (RM) gradually diverges from the online LLM due to distributional shift, ultimately leading to undesirable training outcomes. To address this, we propose RIVAL, an adversarial training framework that formulates the process as a min-max game between the RM and the LLM. RIVAL iteratively updates the both models, with the RM trained to distinguish strong from weak translations (qualitative preference reward), and the LLM trained to enhance its translation for closing this gap. To stabilize training and improve generalizability, we also incorporate quantitative preference reward (e.g., BLEU) into the RM, enabling reference-free quality modeling aligned with human evaluation. Through extensive experiments, we demonstrate that the proposed adversarial training framework significantly improves upon translation baselines.
Rethinking Prompt Optimizers: From Prompt Merits to Optimization
May 15, 2025
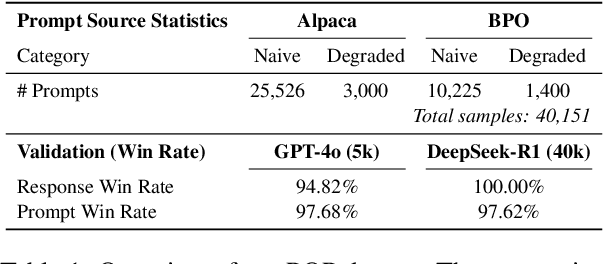
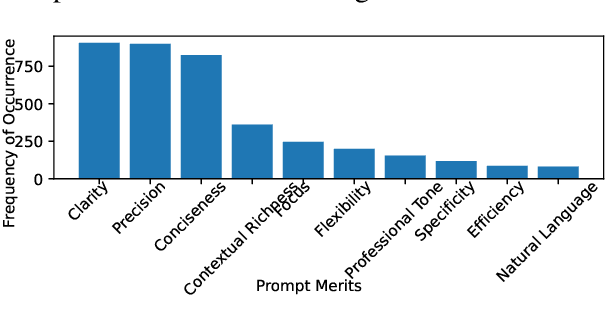
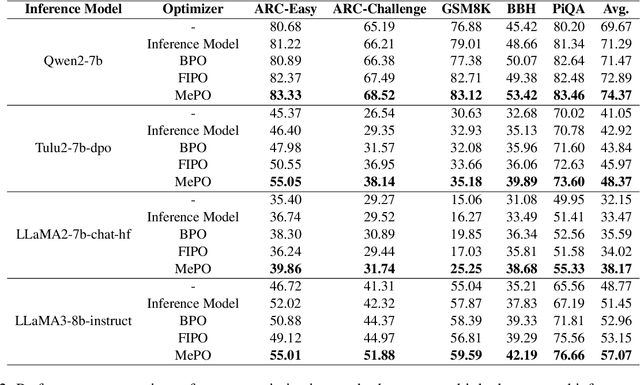
Prompt optimization (PO) offers a practical alternative to fine-tuning large language models (LLMs), enabling performance improvements without altering model weights. Existing methods typically rely on advanced, large-scale LLMs like GPT-4 to generate optimized prompts. However, due to limited downward compatibility, verbose, instruction-heavy prompts from advanced LLMs can overwhelm lightweight inference models and degrade response quality. In this work, we rethink prompt optimization through the lens of interpretable design. We first identify a set of model-agnostic prompt quality merits and empirically validate their effectiveness in enhancing prompt and response quality. We then introduce MePO, a merit-guided, lightweight, and locally deployable prompt optimizer trained on our preference dataset built from merit-aligned prompts generated by a lightweight LLM. Unlike prior work, MePO avoids online optimization reliance, reduces cost and privacy concerns, and, by learning clear, interpretable merits, generalizes effectively to both large-scale and lightweight inference models. Experiments demonstrate that MePO achieves better results across diverse tasks and model types, offering a scalable and robust solution for real-world deployment. Our model and dataset are available at: https://github.com/MidiyaZhu/MePO
Projected gradient methods for nonconvex and stochastic optimization: new complexities and auto-conditioned stepsizes
Dec 18, 2024We present a novel class of projected gradient (PG) methods for minimizing a smooth but not necessarily convex function over a convex compact set. We first provide a novel analysis of the "vanilla" PG method, achieving the best-known iteration complexity for finding an approximate stationary point of the problem. We then develop an "auto-conditioned" projected gradient (AC-PG) variant that achieves the same iteration complexity without requiring the input of the Lipschitz constant of the gradient or any line search procedure. The key idea is to estimate the Lipschitz constant using first-order information gathered from the previous iterations, and to show that the error caused by underestimating the Lipschitz constant can be properly controlled. We then generalize the PG methods to the stochastic setting, by proposing a stochastic projected gradient (SPG) method and a variance-reduced stochastic gradient (VR-SPG) method, achieving new complexity bounds in different oracle settings. We also present auto-conditioned stepsize policies for both stochastic PG methods and establish comparable convergence guarantees.
LLMCL-GEC: Advancing Grammatical Error Correction with LLM-Driven Curriculum Learning
Dec 17, 2024While large-scale language models (LLMs) have demonstrated remarkable capabilities in specific natural language processing (NLP) tasks, they may still lack proficiency compared to specialized models in certain domains, such as grammatical error correction (GEC). Drawing inspiration from the concept of curriculum learning, we have delved into refining LLMs into proficient GEC experts by devising effective curriculum learning (CL) strategies. In this paper, we introduce a novel approach, termed LLM-based curriculum learning, which capitalizes on the robust semantic comprehension and discriminative prowess inherent in LLMs to gauge the complexity of GEC training data. Unlike traditional curriculum learning techniques, our method closely mirrors human expert-designed curriculums. Leveraging the proposed LLM-based CL method, we sequentially select varying levels of curriculums ranging from easy to hard, and iteratively train and refine using the pretrianed T5 and LLaMA series models. Through rigorous testing and analysis across diverse benchmark assessments in English GEC, including the CoNLL14 test, BEA19 test, and BEA19 development sets, our approach showcases a significant performance boost over baseline models and conventional curriculum learning methodologies.