 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn robust recovery of signals from indirect observations
Jan 03, 2025We consider an uncertain linear inverse problem as follows. Given observation $\omega=Ax_*+\zeta$ where $A\in {\bf R}^{m\times p}$ and $\zeta\in {\bf R}^{m}$ is observation noise, we want to recover unknown signal $x_*$, known to belong to a convex set ${\cal X}\subset{\bf R}^{n}$. As opposed to the "standard" setting of such problem, we suppose that the model noise $\zeta$ is "corrupted" -- contains an uncertain (deterministic dense or singular) component. Specifically, we assume that $\zeta$ decomposes into $\zeta=N\nu_*+\xi$ where $\xi$ is the random noise and $N\nu_*$ is the "adversarial contamination" with known $\cal N\subset {\bf R}^n$ such that $\nu_*\in \cal N$ and $N\in {\bf R}^{m\times n}$. We consider two "uncertainty setups" in which $\cal N$ is either a convex bounded set or is the set of sparse vectors (with at most $s$ nonvanishing entries). We analyse the performance of "uncertainty-immunized" polyhedral estimates -- a particular class of nonlinear estimates as introduced in [15, 16] -- and show how "presumably good" estimates of the sort may be constructed in the situation where the signal set is an ellitope (essentially, a symmetric convex set delimited by quadratic surfaces) by means of efficient convex optimization routines.
Accelerated stochastic approximation with state-dependent noise
Jul 13, 2023



We consider a class of stochastic smooth convex optimization problems under rather general assumptions on the noise in the stochastic gradient observation. As opposed to the classical problem setting in which the variance of noise is assumed to be uniformly bounded, herein we assume that the variance of stochastic gradients is related to the "sub-optimality" of the approximate solutions delivered by the algorithm. Such problems naturally arise in a variety of applications, in particular, in the well-known generalized linear regression problem in statistics. However, to the best of our knowledge, none of the existing stochastic approximation algorithms for solving this class of problems attain optimality in terms of the dependence on accuracy, problem parameters, and mini-batch size. We discuss two non-Euclidean accelerated stochastic approximation routines--stochastic accelerated gradient descent (SAGD) and stochastic gradient extrapolation (SGE)--which carry a particular duality relationship. We show that both SAGD and SGE, under appropriate conditions, achieve the optimal convergence rate, attaining the optimal iteration and sample complexities simultaneously. However, corresponding assumptions for the SGE algorithm are more general; they allow, for instance, for efficient application of the SGE to statistical estimation problems under heavy tail noises and discontinuous score functions. We also discuss the application of the SGE to problems satisfying quadratic growth conditions, and show how it can be used to recover sparse solutions. Finally, we report on some simulation experiments to illustrate numerical performance of our proposed algorithms in high-dimensional settings.
Generalized generalized linear models: Convex estimation and online bounds
Apr 26, 2023We introduce a new computational framework for estimating parameters in generalized generalized linear models (GGLM), a class of models that extends the popular generalized linear models (GLM) to account for dependencies among observations in spatio-temporal data. The proposed approach uses a monotone operator-based variational inequality method to overcome non-convexity in parameter estimation and provide guarantees for parameter recovery. The results can be applied to GLM and GGLM, focusing on spatio-temporal models. We also present online instance-based bounds using martingale concentrations inequalities. Finally, we demonstrate the performance of the algorithm using numerical simulations and a real data example for wildfire incidents.
Stochastic Mirror Descent for Large-Scale Sparse Recovery
Oct 23, 2022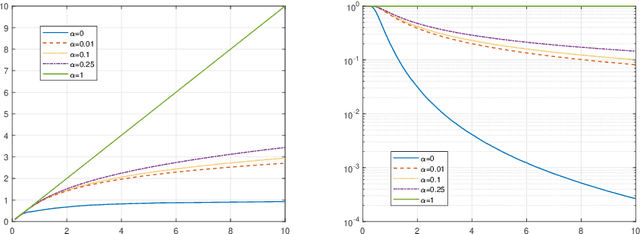
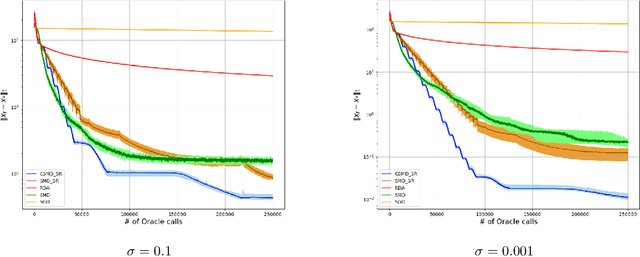
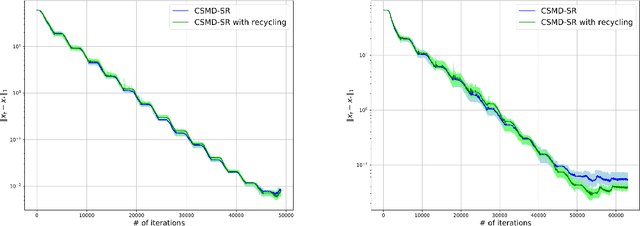
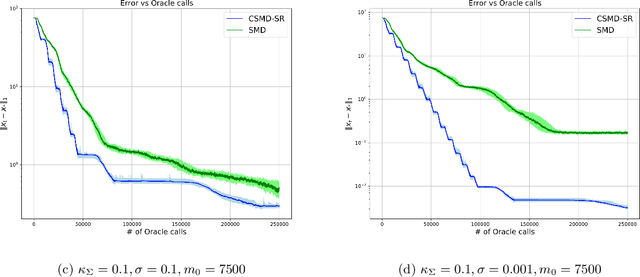
In this paper we discuss an application of Stochastic Approximation to statistical estimation of high-dimensional sparse parameters. The proposed solution reduces to resolving a penalized stochastic optimization problem on each stage of a multistage algorithm; each problem being solved to a prescribed accuracy by the non-Euclidean Composite Stochastic Mirror Descent (CSMD) algorithm. Assuming that the problem objective is smooth and quadratically minorated and stochastic perturbations are sub-Gaussian, our analysis prescribes the method parameters which ensure fast convergence of the estimation error (the radius of a confidence ball of a given norm around the approximate solution). This convergence is linear during the first "preliminary" phase of the routine and is sublinear during the second "asymptotic" phase. We consider an application of the proposed approach to sparse Generalized Linear Regression problem. In this setting, we show that the proposed algorithm attains the optimal convergence of the estimation error under weak assumptions on the regressor distribution. We also present a numerical study illustrating the performance of the algorithm on high-dimensional simulation data.
Sparse recovery by reduced variance stochastic approximation
Jun 11, 2020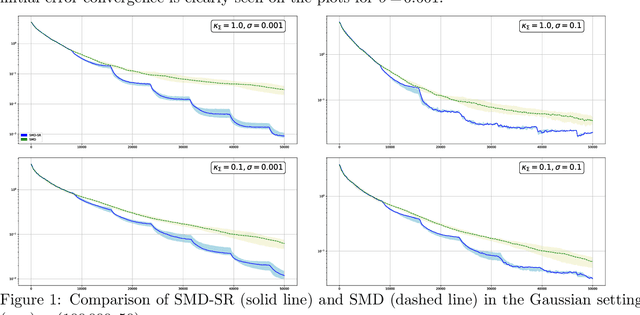
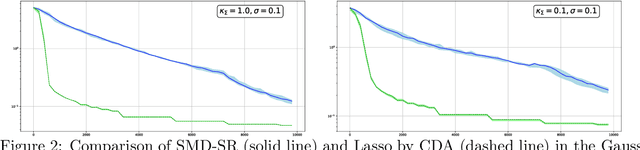
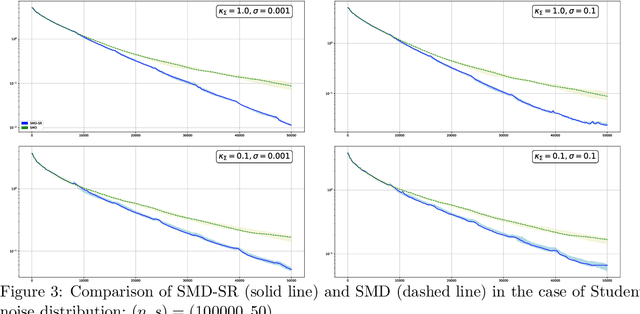
In this paper, we discuss application of iterative Stochastic Optimization routines to the problem of sparse signal recovery from noisy observation. Using Stochastic Mirror Descent algorithm as a building block, we develop a multistage procedure for recovery of sparse solutions to Stochastic Optimization problem under assumption of smoothness and quadratic minoration on the expected objective. An interesting feature of the proposed algorithm is its linear convergence of the approximate solution during the preliminary phase of the routine when the component of stochastic error in the gradient observation which is due to bad initial approximation of the optimal solution is larger than the "ideal" asymptotic error component owing to observation noise "at the optimal solution." We also show how one can straightforwardly enhance reliability of the corresponding solution by using Median-of-Means like techniques. We illustrate the performance of the proposed algorithms in application to classical problems of recovery of sparse and low rank signals in linear regression framework. We show, under rather weak assumption on the regressor and noise distributions, how they lead to parameter estimates which obey (up to factors which are logarithmic in problem dimension and confidence level) the best known to us accuracy bounds.
Convex Recovery of Marked Spatio-Temporal Point Processes
Mar 29, 2020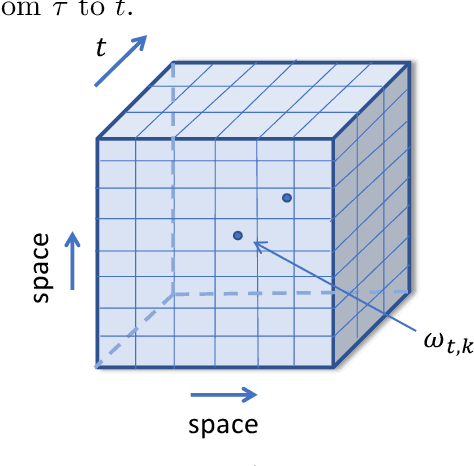

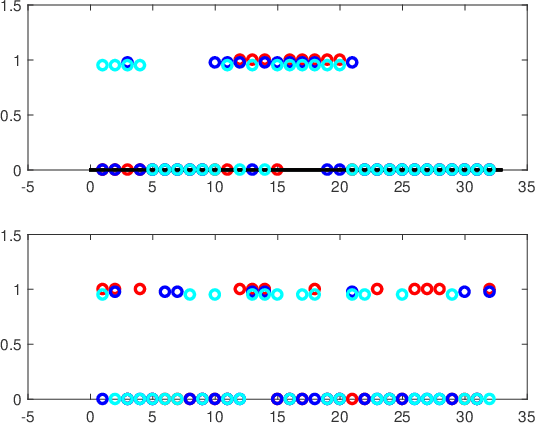
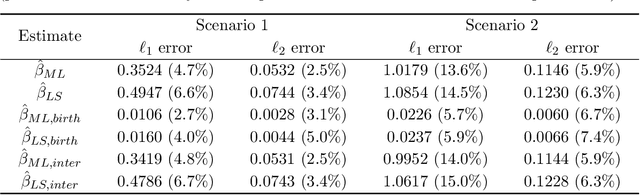
We present a multi-dimensional Bernoulli process model for spatial-temporal discrete event data with categorical marks, where the probability of an event of a specific category in a location may be influenced by past events at this and other locations. The focus is to introduce general forms of influence function which can capture an arbitrary shape of influence from historical events, between locations, and between different categories of events. The general form of influence function differs from the commonly adapted exponential delaying function over time, and more importantly, in our model, we can learn the delayed influence of prior events, which is an aspect seemingly largely ignored in prior literature. Prior knowledge or assumptions on the influence function are incorporated into our framework by allowing general convex constraints on the parameters specifying the influence function. We develop two approaches for recovering these parameters, using the constrained least-square (LS) and maximum likelihood (ML) estimations. We demonstrate the performance of our approach on synthetic examples and illustrate its promise using real data (crime data and novel coronavirus data), in extracting knowledge about the general influences and making predictions.
Unifying mirror descent and dual averaging
Oct 30, 2019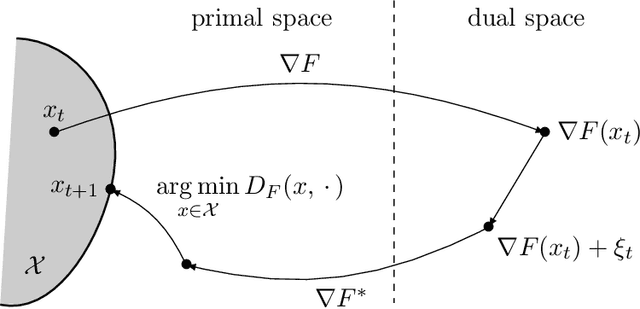
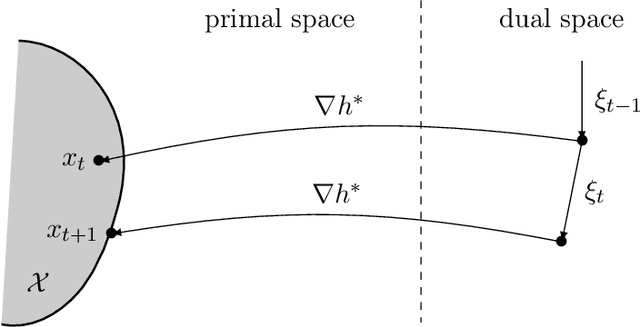
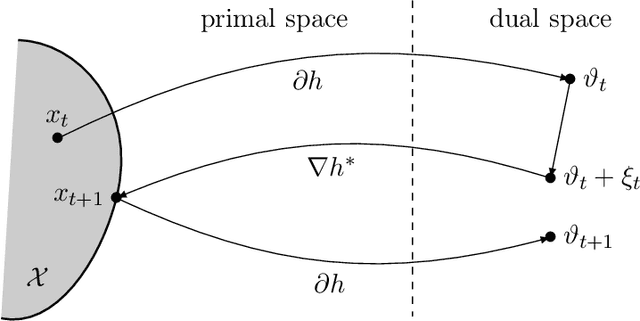
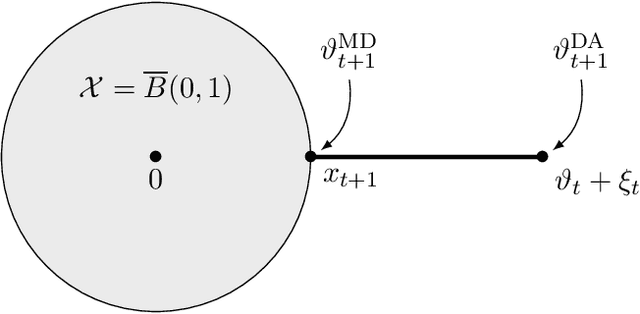
We introduce and analyse a new family of algorithms which generalizes and unifies both the mirror descent and the dual averaging algorithms. The unified analysis of the algorithms involves the introduction of a generalized Bregman divergence which utilizes subgradients instead of gradients. Our approach is general enough to encompass classical settings in convex optimization, online learning, and variational inequalities such as saddle-point problems.
Adaptive Denoising of Signals with Shift-Invariant Structure
Jun 11, 2018
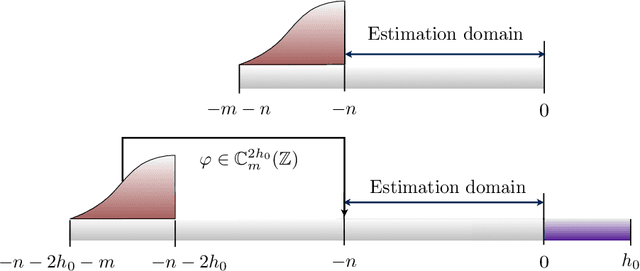
We study the problem of discrete-time signal denoising, following the line of research initiated by [Nem91] and further developed in [JN09, JN10, HJNO15, OHJN16]. Previous papers considered the following setup: the signal is assumed to admit a convolution-type linear oracle -- an unknown linear estimator in the form of the convolution of the observations with an unknown time-invariant filter with small $\ell_2$-norm. It was shown that such an oracle can be "mimicked" by an efficiently computable non-linear convolution-type estimator, in which the filter minimizes the Fourier-domain $\ell_\infty$-norm of the residual, regularized by the Fourier-domain $\ell_1$-norm of the filter. Following [OHJN16], here we study an alternative family of estimators, replacing the $\ell_\infty$-norm of the residual with the $\ell_2$-norm. Such estimators are found to have better statistical properties, in particular, we prove sharp oracle inequalities for their $\ell_2$-loss. Our guarantees require an extra assumption of approximate shift-invariance: the signal must be $\varkappa$-close, in $\ell_2$-metric, to some shift-invariant linear subspace with bounded dimension $s$. However, this subspace can be completely unknown, and the remainder terms in the oracle inequalities scale at most polynomially with $s$ and $\varkappa$. In conclusion, we show that the new assumption implies the previously considered one, providing explicit constructions of the convolution-type linear oracles with $\ell_2$-norm bounded in terms of parameters $s$ and $\varkappa$.
Conditional Gradient Algorithms for Norm-Regularized Smooth Convex Optimization
Mar 28, 2013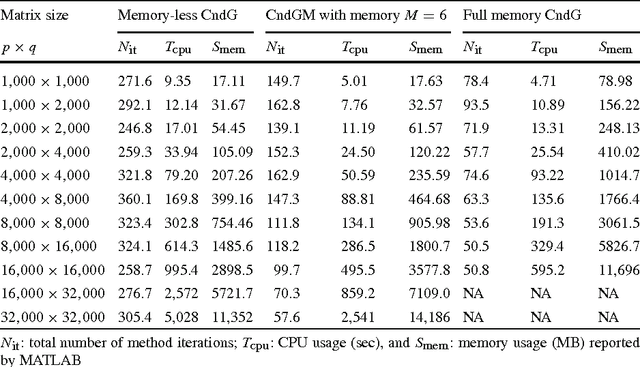
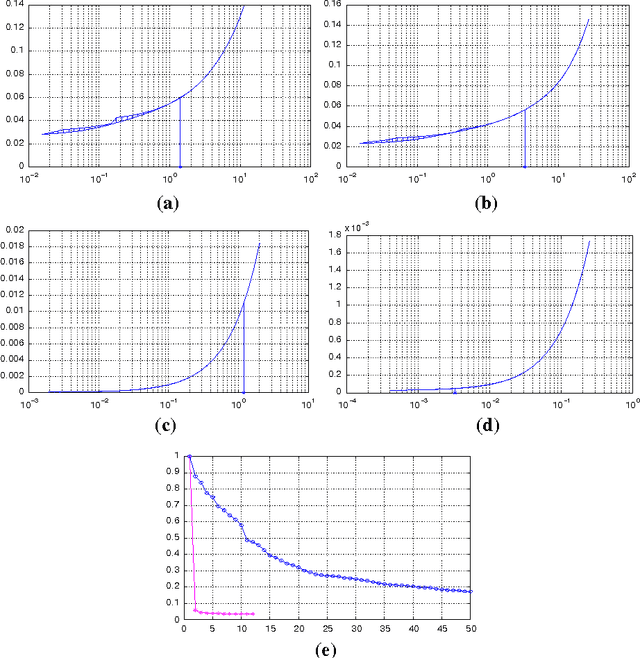
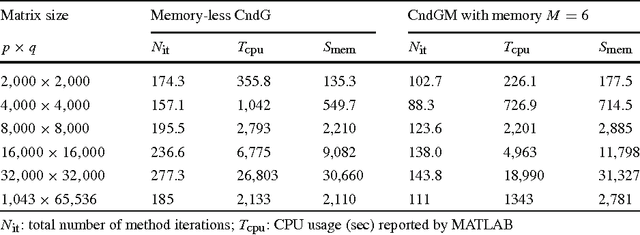

Motivated by some applications in signal processing and machine learning, we consider two convex optimization problems where, given a cone $K$, a norm $\|\cdot\|$ and a smooth convex function $f$, we want either 1) to minimize the norm over the intersection of the cone and a level set of $f$, or 2) to minimize over the cone the sum of $f$ and a multiple of the norm. We focus on the case where (a) the dimension of the problem is too large to allow for interior point algorithms, (b) $\|\cdot\|$ is "too complicated" to allow for computationally cheap Bregman projections required in the first-order proximal gradient algorithms. On the other hand, we assume that {it is relatively easy to minimize linear forms over the intersection of $K$ and the unit $\|\cdot\|$-ball}. Motivating examples are given by the nuclear norm with $K$ being the entire space of matrices, or the positive semidefinite cone in the space of symmetric matrices, and the Total Variation norm on the space of 2D images. We discuss versions of the Conditional Gradient algorithm capable to handle our problems of interest, provide the related theoretical efficiency estimates and outline some applications.
Accuracy guaranties for $\ell_1$ recovery of block-sparse signals
Feb 27, 2013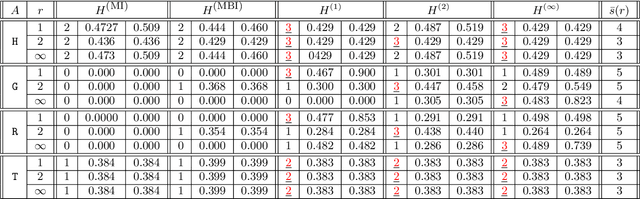
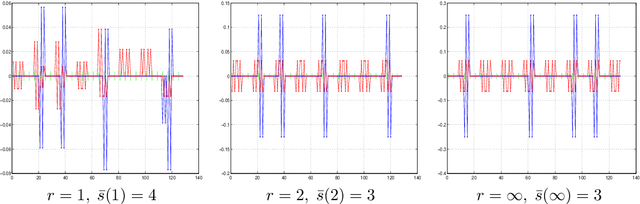
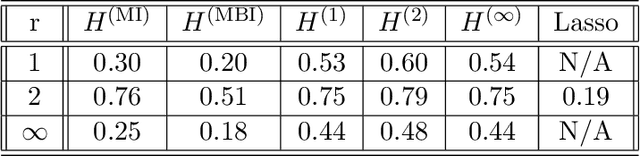
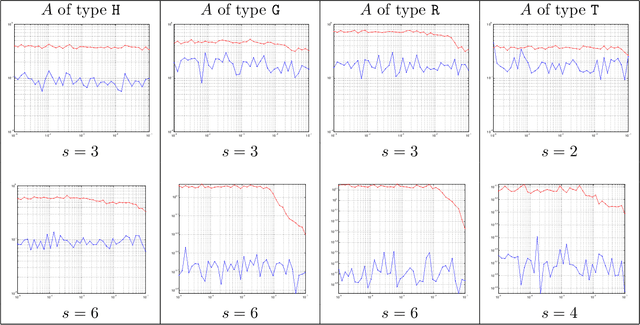
We introduce a general framework to handle structured models (sparse and block-sparse with possibly overlapping blocks). We discuss new methods for their recovery from incomplete observation, corrupted with deterministic and stochastic noise, using block-$\ell_1$ regularization. While the current theory provides promising bounds for the recovery errors under a number of different, yet mostly hard to verify conditions, our emphasis is on verifiable conditions on the problem parameters (sensing matrix and the block structure) which guarantee accurate recovery. Verifiability of our conditions not only leads to efficiently computable bounds for the recovery error but also allows us to optimize these error bounds with respect to the method parameters, and therefore construct estimators with improved statistical properties. To justify our approach, we also provide an oracle inequality, which links the properties of the proposed recovery algorithms and the best estimation performance. Furthermore, utilizing these verifiable conditions, we develop a computationally cheap alternative to block-$\ell_1$ minimization, the non-Euclidean Block Matching Pursuit algorithm. We close by presenting a numerical study to investigate the effect of different block regularizations and demonstrate the performance of the proposed recoveries.
* Published in at http://dx.doi.org/10.1214/12-AOS1057 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)