 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse recovery by reduced variance stochastic approximation
Jun 11, 2020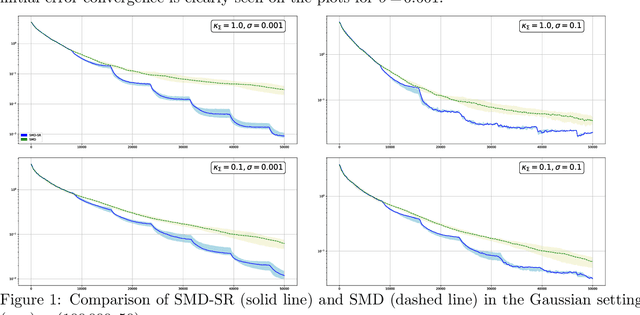
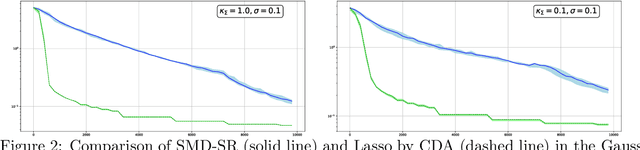
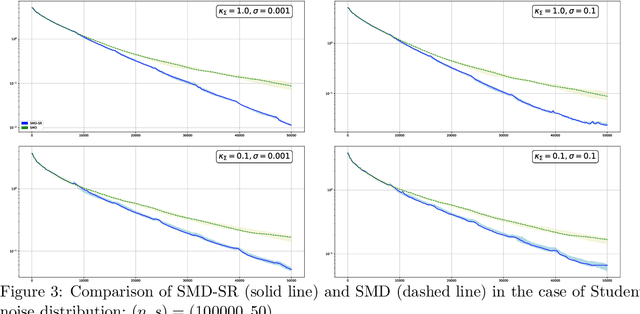
In this paper, we discuss application of iterative Stochastic Optimization routines to the problem of sparse signal recovery from noisy observation. Using Stochastic Mirror Descent algorithm as a building block, we develop a multistage procedure for recovery of sparse solutions to Stochastic Optimization problem under assumption of smoothness and quadratic minoration on the expected objective. An interesting feature of the proposed algorithm is its linear convergence of the approximate solution during the preliminary phase of the routine when the component of stochastic error in the gradient observation which is due to bad initial approximation of the optimal solution is larger than the "ideal" asymptotic error component owing to observation noise "at the optimal solution." We also show how one can straightforwardly enhance reliability of the corresponding solution by using Median-of-Means like techniques. We illustrate the performance of the proposed algorithms in application to classical problems of recovery of sparse and low rank signals in linear regression framework. We show, under rather weak assumption on the regressor and noise distributions, how they lead to parameter estimates which obey (up to factors which are logarithmic in problem dimension and confidence level) the best known to us accuracy bounds.
A Generic Acceleration Framework for Stochastic Composite Optimization
Jun 03, 2019


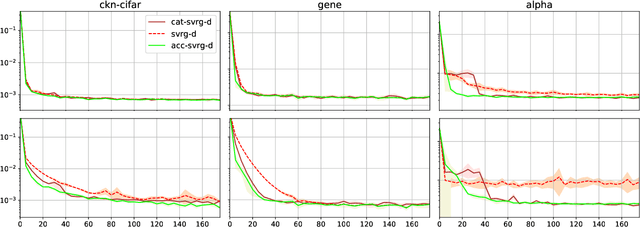
In this paper, we introduce various mechanisms to obtain accelerated first-order stochastic optimization algorithms when the objective function is convex or strongly convex. Specifically, we extend the Catalyst approach originally designed for deterministic objectives to the stochastic setting. Given an optimization method with mild convergence guarantees for strongly convex problems, the challenge is to accelerate convergence to a noise-dominated region, and then achieve convergence with an optimal worst-case complexity depending on the noise variance of the gradients. A side contribution of our work is also a generic analysis that can handle inexact proximal operators, providing new insights about the robustness of stochastic algorithms when the proximal operator cannot be exactly computed.
Estimate Sequences for Variance-Reduced Stochastic Composite Optimization
May 07, 2019
In this paper, we propose a unified view of gradient-based algorithms for stochastic convex composite optimization by extending the concept of estimate sequence introduced by Nesterov. This point of view covers the stochastic gradient descent method, variants of the approaches SAGA, SVRG, and has several advantages: (i) we provide a generic proof of convergence for the aforementioned methods; (ii) we show that this SVRG variant is adaptive to strong convexity; (iii) we naturally obtain new algorithms with the same guarantees; (iv) we derive generic strategies to make these algorithms robust to stochastic noise, which is useful when data is corrupted by small random perturbations. Finally, we show that this viewpoint is useful to obtain new accelerated algorithms in the sense of Nesterov.
* short version of preprint arXiv:1901.08788
Estimate Sequences for Stochastic Composite Optimization: Variance Reduction, Acceleration, and Robustness to Noise
Jan 25, 2019
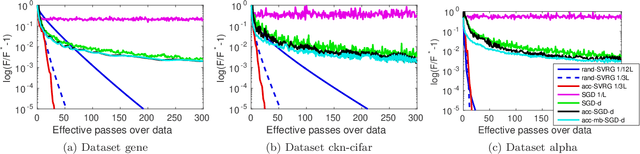
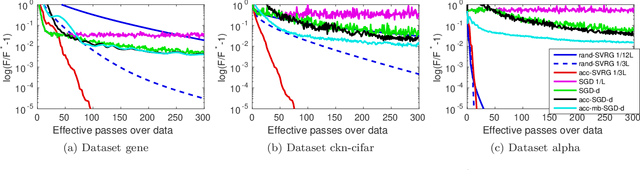

In this paper, we propose a unified view of gradient-based algorithms for stochastic convex composite optimization. By extending the concept of estimate sequence introduced by Nesterov, we interpret a large class of stochastic optimization methods as procedures that iteratively minimize a surrogate of the objective. This point of view covers stochastic gradient descent (SGD), the variance-reduction approaches SAGA, SVRG, MISO, their proximal variants, and has several advantages: (i) we provide a simple generic proof of convergence for all of the aforementioned methods; (ii) we naturally obtain new algorithms with the same guarantees; (iii) we derive generic strategies to make these algorithms robust to stochastic noise, which is useful when data is corrupted by small random perturbations. Finally, we show that this viewpoint is useful to obtain accelerated algorithms.