 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Asynchronous Federated Learning: A Delicate Trade-Off Between Model-Parameter Staleness and Update Frequency
Feb 12, 2025



Synchronous federated learning (FL) scales poorly with the number of clients due to the straggler effect. Algorithms like FedAsync and GeneralizedFedAsync address this limitation by enabling asynchronous communication between clients and the central server. In this work, we rely on stochastic modeling to better understand the impact of design choices in asynchronous FL algorithms, such as the concurrency level and routing probabilities, and we leverage this knowledge to optimize loss. We characterize in particular a fundamental trade-off for optimizing asynchronous FL: minimizing gradient estimation errors by avoiding model parameter staleness, while also speeding up the system by increasing the throughput of model updates. Our two main contributions can be summarized as follows. First, we prove a discrete variant of Little's law to derive a closed-form expression for relative delay, a metric that quantifies staleness. This allows us to efficiently minimize the average loss per model update, which has been the gold standard in literature to date. Second, we observe that naively optimizing this metric leads us to slow down the system drastically by overemphazing staleness at the detriment of throughput. This motivates us to introduce an alternative metric that also takes system speed into account, for which we derive a tractable upper-bound that can be minimized numerically. Extensive numerical results show that these optimizations enhance accuracy by 10% to 30%.
Central Limit Theorem for Bayesian Neural Network trained with Variational Inference
Jun 10, 2024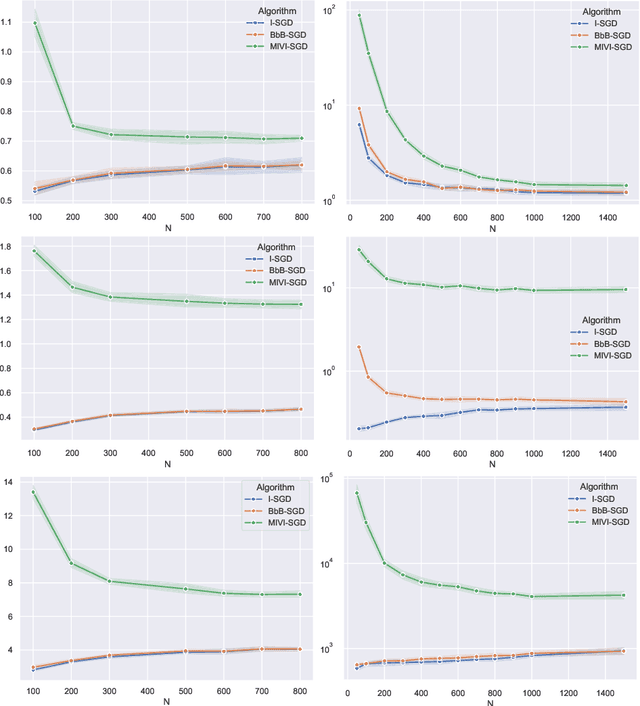
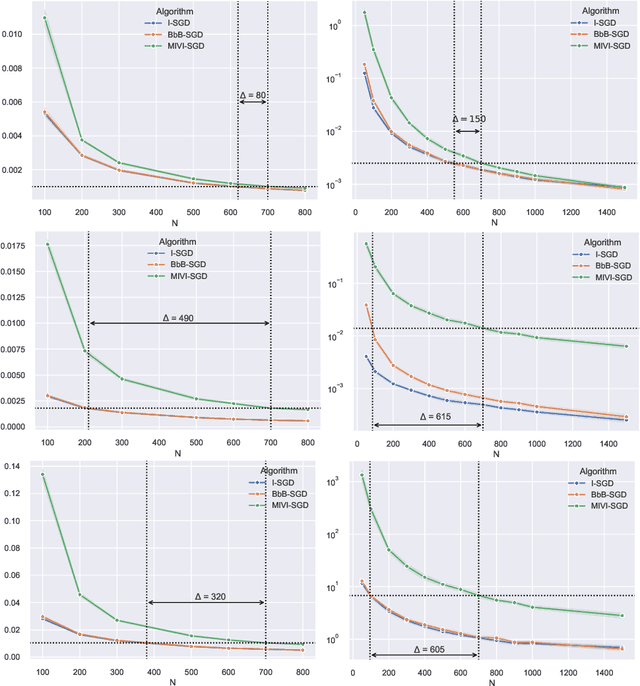
In this paper, we rigorously derive Central Limit Theorems (CLT) for Bayesian two-layerneural networks in the infinite-width limit and trained by variational inference on a regression task. The different networks are trained via different maximization schemes of the regularized evidence lower bound: (i) the idealized case with exact estimation of a multiple Gaussian integral from the reparametrization trick, (ii) a minibatch scheme using Monte Carlo sampling, commonly known as Bayes-by-Backprop, and (iii) a computationally cheaper algorithm named Minimal VI. The latter was recently introduced by leveraging the information obtained at the level of the mean-field limit. Laws of large numbers are already rigorously proven for the three schemes that admits the same asymptotic limit. By deriving CLT, this work shows that the idealized and Bayes-by-Backprop schemes have similar fluctuation behavior, that is different from the Minimal VI one. Numerical experiments then illustrate that the Minimal VI scheme is still more efficient, in spite of bigger variances, thanks to its important gain in computational complexity.
Inexact subgradient methods for semialgebraic functions
Apr 30, 2024Motivated by the widespread use of approximate derivatives in machine learning and optimization, we study inexact subgradient methods with non-vanishing additive errors and step sizes. In the nonconvex semialgebraic setting, under boundedness assumptions, we prove that the method provides points that eventually fluctuate close to the critical set at a distance proportional to $\epsilon^\rho$ where $\epsilon$ is the error in subgradient evaluation and $\rho$ relates to the geometry of the problem. In the convex setting, we provide complexity results for the averaged values. We also obtain byproducts of independent interest, such as descent-like lemmas for nonsmooth nonconvex problems and some results on the limit of affine interpolants of differential inclusions.
Law of Large Numbers for Bayesian two-layer Neural Network trained with Variational Inference
Jul 10, 2023



We provide a rigorous analysis of training by variational inference (VI) of Bayesian neural networks in the two-layer and infinite-width case. We consider a regression problem with a regularized evidence lower bound (ELBO) which is decomposed into the expected log-likelihood of the data and the Kullback-Leibler (KL) divergence between the a priori distribution and the variational posterior. With an appropriate weighting of the KL, we prove a law of large numbers for three different training schemes: (i) the idealized case with exact estimation of a multiple Gaussian integral from the reparametrization trick, (ii) a minibatch scheme using Monte Carlo sampling, commonly known as Bayes by Backprop, and (iii) a new and computationally cheaper algorithm which we introduce as Minimal VI. An important result is that all methods converge to the same mean-field limit. Finally, we illustrate our results numerically and discuss the need for the derivation of a central limit theorem.
Balanced Training of Energy-Based Models with Adaptive Flow Sampling
Jun 21, 2023Energy-based models (EBMs) are versatile density estimation models that directly parameterize an unnormalized log density. Although very flexible, EBMs lack a specified normalization constant of the model, making the likelihood of the model computationally intractable. Several approximate samplers and variational inference techniques have been proposed to estimate the likelihood gradients for training. These techniques have shown promising results in generating samples, but little attention has been paid to the statistical accuracy of the estimated density, such as determining the relative importance of different classes in a dataset. In this work, we propose a new maximum likelihood training algorithm for EBMs that uses a different type of generative model, normalizing flows (NF), which have recently been proposed to facilitate sampling. Our method fits an NF to an EBM during training so that an NF-assisted sampling scheme provides an accurate gradient for the EBMs at all times, ultimately leading to a fast sampler for generating new data.
On Sampling with Approximate Transport Maps
Feb 09, 2023Transport maps can ease the sampling of distributions with non-trivial geometries by transforming them into distributions that are easier to handle. The potential of this approach has risen with the development of Normalizing Flows (NF) which are maps parameterized with deep neural networks trained to push a reference distribution towards a target. NF-enhanced samplers recently proposed blend (Markov chain) Monte Carlo methods with either (i) proposal draws from the flow or (ii) a flow-based reparametrization. In both cases, the quality of the learned transport conditions performance. The present work clarifies for the first time the relative strengths and weaknesses of these two approaches. Our study concludes that multimodal targets can reliability be handled with flow-based proposals up to moderately high dimensions. In contrast, methods relying on reparametrization struggle with multimodality but are more robust otherwise in high-dimensional settings and under poor training. To further illustrate the influence of target-proposal adequacy, we also derive a new quantitative bound for the mixing time of the Independent Metropolis-Hastings sampler.
On Riemannian Stochastic Approximation Schemes with Fixed Step-Size
Feb 19, 2021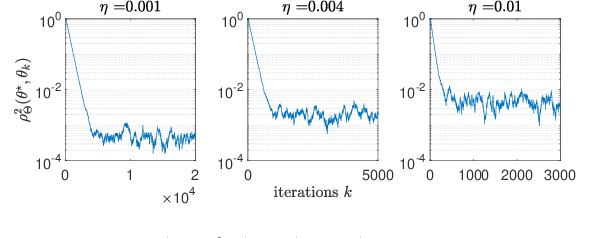
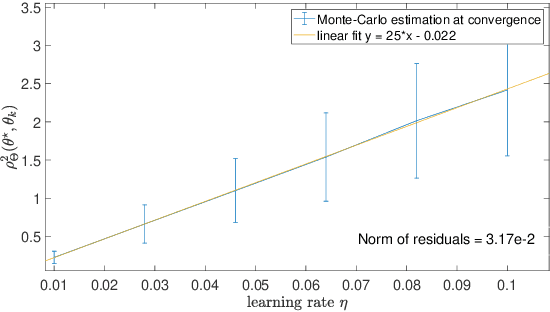
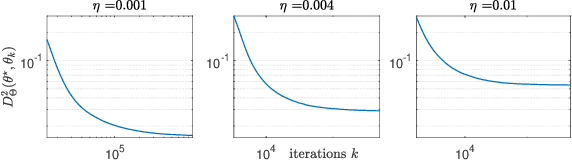
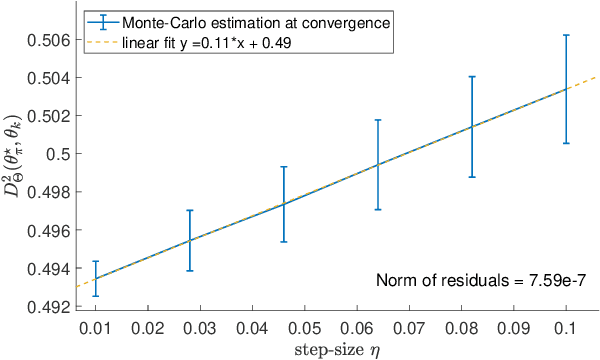
This paper studies fixed step-size stochastic approximation (SA) schemes, including stochastic gradient schemes, in a Riemannian framework. It is motivated by several applications, where geodesics can be computed explicitly, and their use accelerates crude Euclidean methods. A fixed step-size scheme defines a family of time-homogeneous Markov chains, parametrized by the step-size. Here, using this formulation, non-asymptotic performance bounds are derived, under Lyapunov conditions. Then, for any step-size, the corresponding Markov chain is proved to admit a unique stationary distribution, and to be geometrically ergodic. This result gives rise to a family of stationary distributions indexed by the step-size, which is further shown to converge to a Dirac measure, concentrated at the solution of the problem at hand, as the step-size goes to 0. Finally, the asymptotic rate of this convergence is established, through an asymptotic expansion of the bias, and a central limit theorem.
Convergence Analysis of Riemannian Stochastic Approximation Schemes
Jun 15, 2020This paper analyzes the convergence for a large class of Riemannian stochastic approximation (SA) schemes, which aim at tackling stochastic optimization problems. In particular, the recursions we study use either the exponential map of the considered manifold (geodesic schemes) or more general retraction functions (retraction schemes) used as a proxy for the exponential map. Such approximations are of great interest since they are low complexity alternatives to geodesic schemes. Under the assumption that the mean field of the SA is correlated with the gradient of a smooth Lyapunov function (possibly non-convex), we show that the above Riemannian SA schemes find an ${\mathcal{O}}(b_\infty + \log n / \sqrt{n})$-stationary point (in expectation) within ${\mathcal{O}}(n)$ iterations, where $b_\infty \geq 0$ is the asymptotic bias. Compared to previous works, the conditions we derive are considerably milder. First, all our analysis are global as we do not assume iterates to be a-priori bounded. Second, we study biased SA schemes. To be more specific, we consider the case where the mean-field function can only be estimated up to a small bias, and/or the case in which the samples are drawn from a controlled Markov chain. Third, the conditions on retractions required to ensure convergence of the related SA schemes are weak and hold for well-known examples. We illustrate our results on three machine learning problems.
On Last-Layer Algorithms for Classification: Decoupling Representation from Uncertainty Estimation
Jan 22, 2020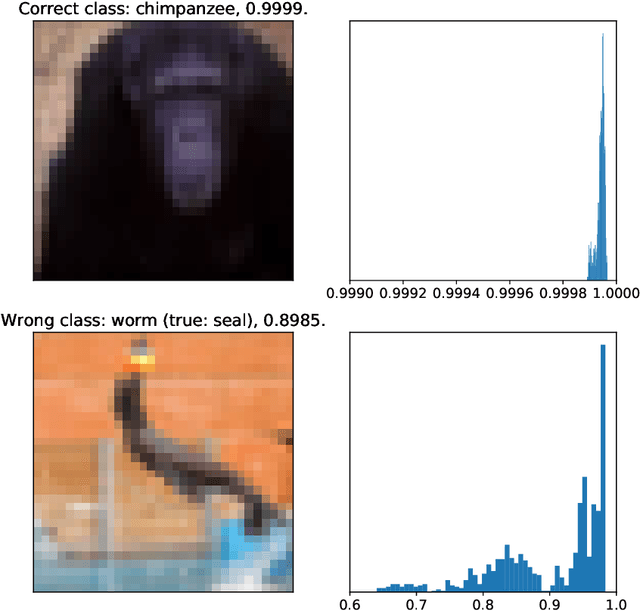
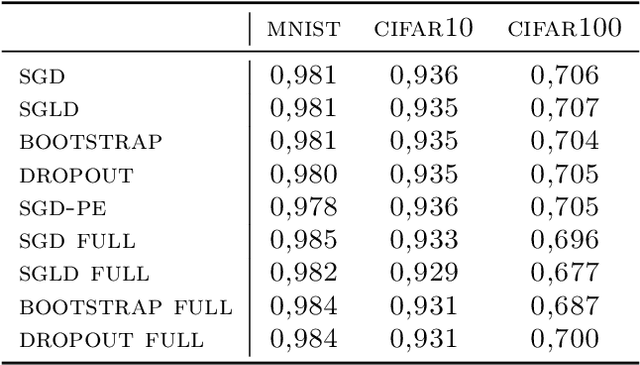
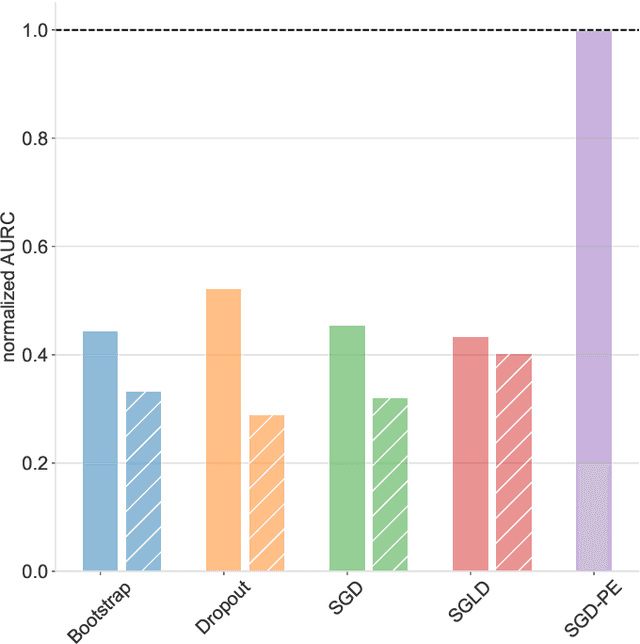
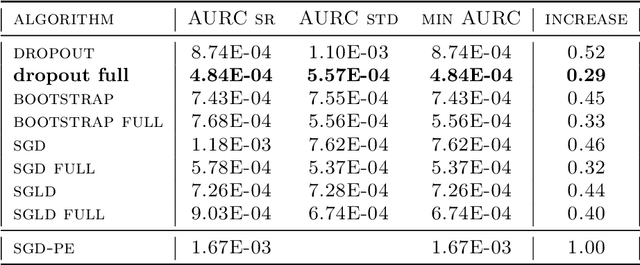
Uncertainty quantification for deep learning is a challenging open problem. Bayesian statistics offer a mathematically grounded framework to reason about uncertainties; however, approximate posteriors for modern neural networks still require prohibitive computational costs. We propose a family of algorithms which split the classification task into two stages: representation learning and uncertainty estimation. We compare four specific instances, where uncertainty estimation is performed via either an ensemble of Stochastic Gradient Descent or Stochastic Gradient Langevin Dynamics snapshots, an ensemble of bootstrapped logistic regressions, or via a number of Monte Carlo Dropout passes. We evaluate their performance in terms of \emph{selective} classification (risk-coverage), and their ability to detect out-of-distribution samples. Our experiments suggest there is limited value in adding multiple uncertainty layers to deep classifiers, and we observe that these simple methods strongly outperform a vanilla point-estimate SGD in some complex benchmarks like ImageNet.
Unifying mirror descent and dual averaging
Oct 30, 2019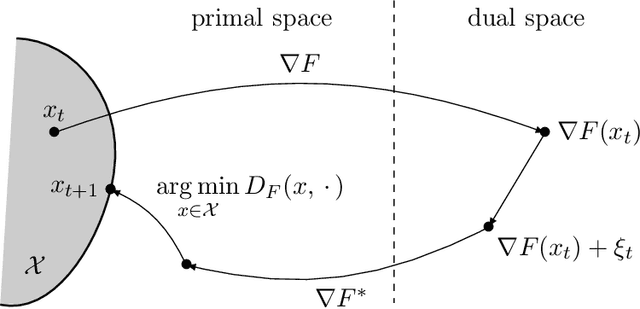
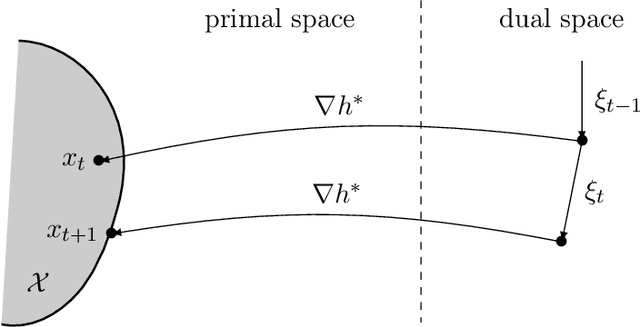
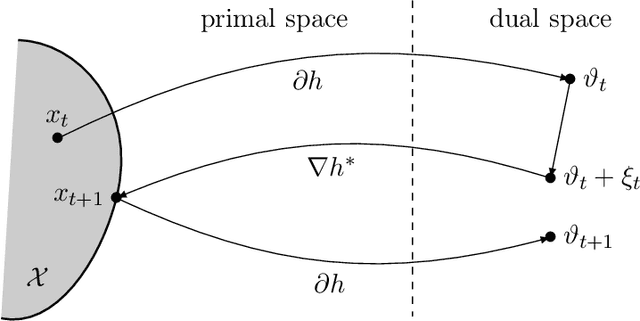
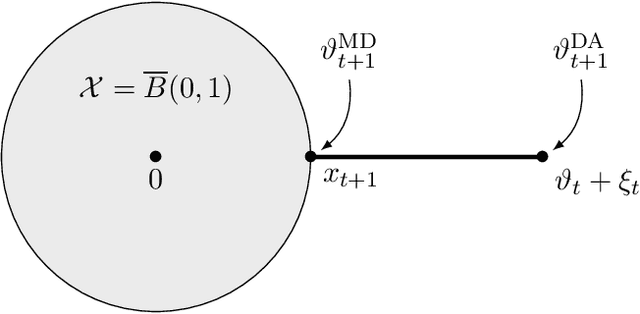
We introduce and analyse a new family of algorithms which generalizes and unifies both the mirror descent and the dual averaging algorithms. The unified analysis of the algorithms involves the introduction of a generalized Bregman divergence which utilizes subgradients instead of gradients. Our approach is general enough to encompass classical settings in convex optimization, online learning, and variational inequalities such as saddle-point problems.