 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe critical slowing down in diffusion models
May 12, 2026Computational sampling has been central to the sciences since the mid-20th century. While machine-learning-based approaches have recently enabled major advances, their behavior remains poorly understood, with limited theoretical control over when and why they succeed. Here we provide such insight for diffusion models-a class of generative schemes highly effective in practice-by analyzing their application to the $O(n)$ model of statistical field theory in the Gaussian limit $n \to \infty$. In this analytically tractable setting, we show that training a score model with a one-layer network architecture matching the exact solution exhibits a form of critical slowing down in parameter learning. This slowing down also impacts the generation process, indicating that the well-known difficulties of sampling near criticality persist even for learned generative models. To overcome this bottleneck, we demonstrate the power of combining architectural depth with physical locality. We find that using a two-layer architecture drastically reduces the critical slowing down, with the training time scaling logarithmically rather than quadratically with system size. By introducing a local score approximation we show that this acceleration in training time can be achieved without increasing the number of neural network parameters. Taken together, these results demonstrate that diffusion models can overcome the critical slowing down through appropriate architectural design, and establish a controlled framework for understanding and improving learned sampling methods in statistical physics and beyond.
Annealing in variational inference mitigates mode collapse: A theoretical study on Gaussian mixtures
Feb 13, 2026Mode collapse, the failure to capture one or more modes when targetting a multimodal distribution, is a central challenge in modern variational inference. In this work, we provide a mathematical analysis of annealing based strategies for mitigating mode collapse in a tractable setting: learning a Gaussian mixture, where mode collapse is known to arise. Leveraging a low dimensional summary statistics description, we precisely characterize the interplay between the initial temperature and the annealing rate, and derive a sharp formula for the probability of mode collapse. Our analysis shows that an appropriately chosen annealing scheme can robustly prevent mode collapse. Finally, we present numerical evidence that these theoretical tradeoffs qualitatively extend to neural network based models, RealNVP normalizing flows, providing guidance for designing annealing strategies mitigating mode collapse in practical variational inference pipelines.
Riemannian Stochastic Interpolants for Amorphous Particle Systems
Dec 18, 2025Modern generative models hold great promise for accelerating diverse tasks involving the simulation of physical systems, but they must be adapted to the specific constraints of each domain. Significant progress has been made for biomolecules and crystalline materials. Here, we address amorphous materials (glasses), which are disordered particle systems lacking atomic periodicity. Sampling equilibrium configurations of glass-forming materials is a notoriously slow and difficult task. This obstacle could be overcome by developing a generative framework capable of producing equilibrium configurations with well-defined likelihoods. In this work, we address this challenge by leveraging an equivariant Riemannian stochastic interpolation framework which combines Riemannian stochastic interpolant and equivariant flow matching. Our method rigorously incorporates periodic boundary conditions and the symmetries of multi-component particle systems, adapting an equivariant graph neural network to operate directly on the torus. Our numerical experiments on model amorphous systems demonstrate that enforcing geometric and symmetry constraints significantly improves generative performance.
Improving the evaluation of samplers on multi-modal targets
Apr 11, 2025Addressing multi-modality constitutes one of the major challenges of sampling. In this reflection paper, we advocate for a more systematic evaluation of samplers towards two sources of difficulty that are mode separation and dimension. For this, we propose a synthetic experimental setting that we illustrate on a selection of samplers, focusing on the challenging criterion of recovery of the mode relative importance. These evaluations are crucial to diagnose the potential of samplers to handle multi-modality and therefore to drive progress in the field.
Learned Reference-based Diffusion Sampling for multi-modal distributions
Oct 25, 2024



Over the past few years, several approaches utilizing score-based diffusion have been proposed to sample from probability distributions, that is without having access to exact samples and relying solely on evaluations of unnormalized densities. The resulting samplers approximate the time-reversal of a noising diffusion process, bridging the target distribution to an easy-to-sample base distribution. In practice, the performance of these methods heavily depends on key hyperparameters that require ground truth samples to be accurately tuned. Our work aims to highlight and address this fundamental issue, focusing in particular on multi-modal distributions, which pose significant challenges for existing sampling methods. Building on existing approaches, we introduce Learned Reference-based Diffusion Sampler (LRDS), a methodology specifically designed to leverage prior knowledge on the location of the target modes in order to bypass the obstacle of hyperparameter tuning. LRDS proceeds in two steps by (i) learning a reference diffusion model on samples located in high-density space regions and tailored for multimodality, and (ii) using this reference model to foster the training of a diffusion-based sampler. We experimentally demonstrate that LRDS best exploits prior knowledge on the target distribution compared to competing algorithms on a variety of challenging distributions.
A theoretical perspective on mode collapse in variational inference
Oct 17, 2024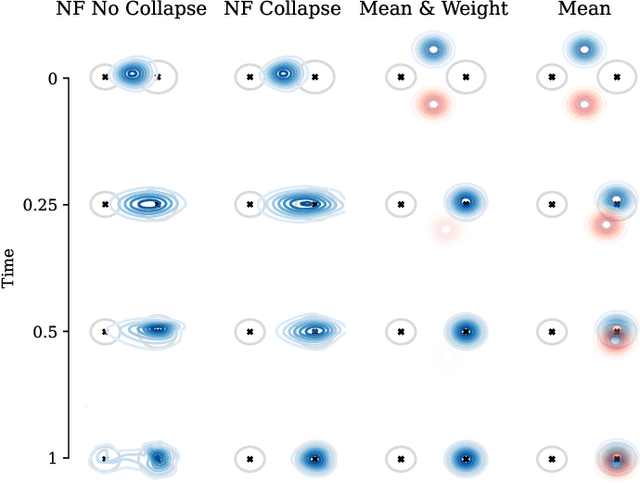

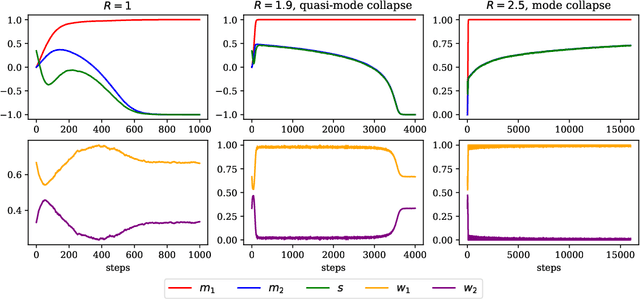

While deep learning has expanded the possibilities for highly expressive variational families, the practical benefits of these tools for variational inference (VI) are often limited by the minimization of the traditional Kullback-Leibler objective, which can yield suboptimal solutions. A major challenge in this context is \emph{mode collapse}: the phenomenon where a model concentrates on a few modes of the target distribution during training, despite being statistically capable of expressing them all. In this work, we carry a theoretical investigation of mode collapse for the gradient flow on Gaussian mixture models. We identify the key low-dimensional statistics characterizing the flow, and derive a closed set of low-dimensional equations governing their evolution. Leveraging this compact description, we show that mode collapse is present even in statistically favorable scenarios, and identify two key mechanisms driving it: mean alignment and vanishing weight. Our theoretical findings are consistent with the implementation of VI using normalizing flows, a class of popular generative models, thereby offering practical insights.
Stochastic Localization via Iterative Posterior Sampling
Feb 16, 2024Building upon score-based learning, new interest in stochastic localization techniques has recently emerged. In these models, one seeks to noise a sample from the data distribution through a stochastic process, called observation process, and progressively learns a denoiser associated to this dynamics. Apart from specific applications, the use of stochastic localization for the problem of sampling from an unnormalized target density has not been explored extensively. This work contributes to fill this gap. We consider a general stochastic localization framework and introduce an explicit class of observation processes, associated with flexible denoising schedules. We provide a complete methodology, $\textit{Stochastic Localization via Iterative Posterior Sampling}$ (SLIPS), to obtain approximate samples of this dynamics, and as a by-product, samples from the target distribution. Our scheme is based on a Markov chain Monte Carlo estimation of the denoiser and comes with detailed practical guidelines. We illustrate the benefits and applicability of SLIPS on several benchmarks, including Gaussian mixtures in increasing dimensions, Bayesian logistic regression and a high-dimensional field system from statistical-mechanics.
Active learning of Boltzmann samplers and potential energies with quantum mechanical accuracy
Jan 29, 2024



Extracting consistent statistics between relevant free-energy minima of a molecular system is essential for physics, chemistry and biology. Molecular dynamics (MD) simulations can aid in this task but are computationally expensive, especially for systems that require quantum accuracy. To overcome this challenge, we develop an approach combining enhanced sampling with deep generative models and active learning of a machine learning potential (MLP). We introduce an adaptive Markov chain Monte Carlo framework that enables the training of one Normalizing Flow (NF) and one MLP per state. We simulate several Markov chains in parallel until they reach convergence, sampling the Boltzmann distribution with an efficient use of energy evaluations. At each iteration, we compute the energy of a subset of the NF-generated configurations using Density Functional Theory (DFT), we predict the remaining configuration's energy with the MLP and actively train the MLP using the DFT-computed energies. Leveraging the trained NF and MLP models, we can compute thermodynamic observables such as free-energy differences or optical spectra. We apply this method to study the isomerization of an ultrasmall silver nanocluster, belonging to a set of systems with diverse applications in the fields of medicine and catalysis.
Balanced Training of Energy-Based Models with Adaptive Flow Sampling
Jun 21, 2023Energy-based models (EBMs) are versatile density estimation models that directly parameterize an unnormalized log density. Although very flexible, EBMs lack a specified normalization constant of the model, making the likelihood of the model computationally intractable. Several approximate samplers and variational inference techniques have been proposed to estimate the likelihood gradients for training. These techniques have shown promising results in generating samples, but little attention has been paid to the statistical accuracy of the estimated density, such as determining the relative importance of different classes in a dataset. In this work, we propose a new maximum likelihood training algorithm for EBMs that uses a different type of generative model, normalizing flows (NF), which have recently been proposed to facilitate sampling. Our method fits an NF to an EBM during training so that an NF-assisted sampling scheme provides an accurate gradient for the EBMs at all times, ultimately leading to a fast sampler for generating new data.
On Sampling with Approximate Transport Maps
Feb 09, 2023Transport maps can ease the sampling of distributions with non-trivial geometries by transforming them into distributions that are easier to handle. The potential of this approach has risen with the development of Normalizing Flows (NF) which are maps parameterized with deep neural networks trained to push a reference distribution towards a target. NF-enhanced samplers recently proposed blend (Markov chain) Monte Carlo methods with either (i) proposal draws from the flow or (ii) a flow-based reparametrization. In both cases, the quality of the learned transport conditions performance. The present work clarifies for the first time the relative strengths and weaknesses of these two approaches. Our study concludes that multimodal targets can reliability be handled with flow-based proposals up to moderately high dimensions. In contrast, methods relying on reparametrization struggle with multimodality but are more robust otherwise in high-dimensional settings and under poor training. To further illustrate the influence of target-proposal adequacy, we also derive a new quantitative bound for the mixing time of the Independent Metropolis-Hastings sampler.